






 本文介绍了如何通过分析网络请求,利用Python的requests库获取天猫店铺的商品信息。首先,通过Chrome浏览器开发者工具找到数据来源,然后使用requests.get()方法,结合URL参数(如页码)和伪造的HTTP头部(headers)来请求数据。最后,解析返回的JSON数据并进行保存。
本文介绍了如何通过分析网络请求,利用Python的requests库获取天猫店铺的商品信息。首先,通过Chrome浏览器开发者工具找到数据来源,然后使用requests.get()方法,结合URL参数(如页码)和伪造的HTTP头部(headers)来请求数据。最后,解析返回的JSON数据并进行保存。
分析要获取的页面信息
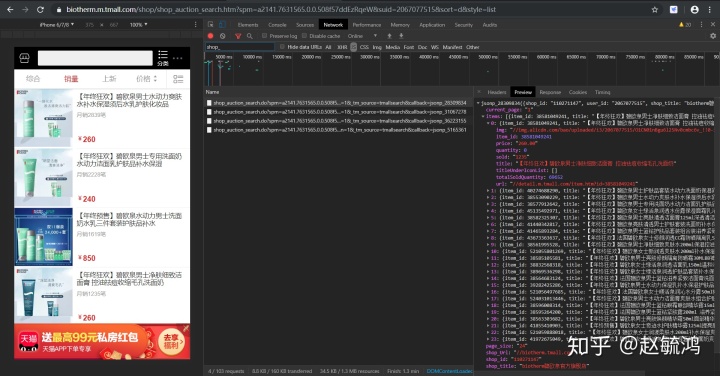
- 打开chrome浏览器——进入天猫首页——随便进入某家官方旗舰店——ctrl+shift+i打开浏览器检查工具——点击手机页面,刷新网页——之后会发现我们想要的信息就在network_js下的以shop_auction开头的包中
- 使用requests.get()方法获取我们想要的店铺信息
我们需要传入两个参数:
1)url:
https://biotherm.m.tmall.com/shop/shop_auction_search.do?sort=d&style=list&p=1&page_size=12&from=h5&shop_id=110271147&ajson=1&_tm_source=tmallsearch&callback=jsonp_31067278
https://biotherm.m.tmall.com/shop/shop_auction_search.do?sort=d&style=list&p=3&page_size=12&from=h5&shop_id=110271147&ajson=1&_tm_source=tmallsearch&callback=jsonp_36223155
摘取几个url链接我们不难发现规律:p = 1这里就是页码,后面的callback表示的是返回文件的名字吧估计,后面的8位数字猜测是随机数改了之后刷新页面发现数据是一致的,哈哈
url能搞定了
2)伪装头headers:
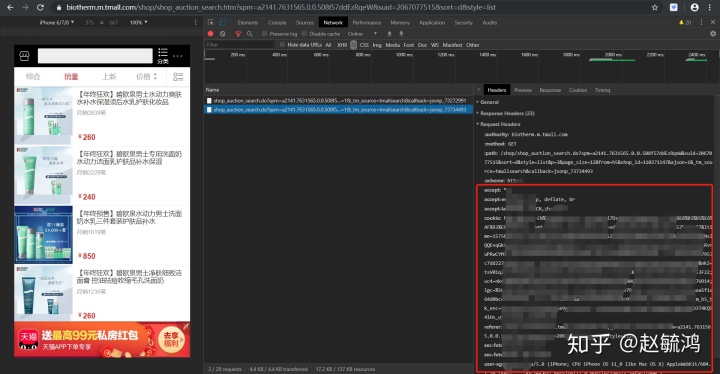
小需求,所以手工复制搞一下就好,其他高级方法还不会哈哈
3. 解析返回的json文件并保存
import requests
import json
import random
import re
import xlsxwriter
import datetime
'''定义一个天猫类,传入cookie、店铺名称,返回一个xlsx文件,包含店铺里面所有商品的信息'''
class Tmallstore():
def __init__(self,storename,cookies):
'''初始化天猫类,需要传入要获取的店铺名称,cookie'''
self.store = storename
self.header = {
'accept':'*/*',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'cookie':cookies,
'referer':'https://{0}.m.tmall.com/shop/shop_auction_search.htm?sort=d&style=list'.format(storename),
'sec-fetch-mode':'no-cors',
'sec-fetch-site':'same-origin',
'user-agent':'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1'
}
self.item_dict = {
'id':[],
'item_id':[],
'title':[],
'img':[],
'sold':[],
'quantity':[],
'totalSoldQuantity':[],
'url':[],
'price':[]
}
self.id = 0
def pageurl(self,pagenum):
'''传入要获取的页码,返回该页面的url链接'''
random_num = random.randint(20739921,87739530)
return 'https://{0}.m.tmall.com/shop/shop_auction_search.do?sort=d&style=list&p={1}&page_size=12&from=h5&ajson=1&_tm_source=tmallsearch&callback=jsonp_{2}'.format(self.store,pagenum,random_num)
def gethtmljson(self,pagenum):
'''传入要获取的页码,返回该页面的json内容'''
pageurl = self.pageurl(pagenum)
req = requests.get(pageurl,headers = self.header)
req.encoding = req.apparent_encoding
infos = re.findall('(({.*}))',req.text)[0]
infos_json = json.loads(infos)
return infos_json
def getpagenum(self,pagenum):
'''获取该店铺的页面数量'''
page_json = self.gethtmljson(pagenum)
page_num = int(page_json.get('total_page'))
item_num = int(page_json.get('total_results'))
print('店铺的商品共计{0},共计{1}页'.format(item_num,page_num))
return page_num
def getitem(self,pagenum):
'''解析该页面所包含的商品信息,并将解析结果添加至self.item_dict'''
page_json = self.gethtmljson(pagenum)
item_detail = page_json.get('items')
for eachitem in item_detail:
self.id += 1
self.item_dict['id'].append(self.id)
self.item_dict['item_id'].append(eachitem.get('item_id','None'))
self.item_dict['title'].append(eachitem.get('title','None'))
self.item_dict['img'].append('https:' + eachitem.get('img','None'))
self.item_dict['sold'].append(eachitem.get('sold','None'))
self.item_dict['quantity'].append(eachitem.get('quantity','None'))
self.item_dict['totalSoldQuantity'].append(eachitem.get('totalSoldQuantity','None'))
self.item_dict['url'].append('https:' + eachitem.get('url','None'))
self.item_dict['price'].append(eachitem.get('price','None'))
def save_as_xlsx(self):
'''循环遍历所有页面,完成内容提取并保存至self.item_dict,最后将获取的内容写入到xlsx文件中'''
all_page_store = self.getpagenum(1)
for j in range(1,all_page_store + 1):
self.getitem(j)
print('第{}页商品信息已经获取完毕!'.format(j))
cur = datetime.datetime.now()
today_str = '{0}_{1}_{2}'.format(cur.year,cur.month,cur.day)
f_wb = xlsxwriter.Workbook('{0}_{1}.xlsx'.format(self.store,today_str))
f_wt = f_wb.add_worksheet('items_of_{}'.format(self.store))
f_wt.write_row('A1',['id','item_id','title','img','sold','quantity','totalSoldQuantity','url','price'])
f_wt.write_column('A2',self.item_dict['id'])
f_wt.write_column('B2',self.item_dict['item_id'])
f_wt.write_column('C2',self.item_dict['title'])
f_wt.write_column('D2',self.item_dict['img'])
f_wt.write_column('E2',self.item_dict['sold'])
f_wt.write_column('F2',self.item_dict['quantity'])
f_wt.write_column('G2',self.item_dict['totalSoldQuantity'])
f_wt.write_column('H2',self.item_dict['url'])
f_wt.write_column('I2',self.item_dict['price'])
f_wb.close()
print('文件已经保存至{}_{}.xlsx'.format(self.store,today_str))
#在store_list中自定义填入要获取的天猫旗舰店店铺名称,天猫店铺首页的链接中有
store_list = ['algnjjry','baicaoshijia','biotherm','bisutanghzp']
#从浏览器复制一份cookie更新一下
cookie_store = 'xxxxxxxxx'
for eachstore in store_list:
storeclass = Tmallstore(eachstore,cookie_store)
storeclass.save_as_xlsx()

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









