







 本文对比分析了多种开源OLAP引擎,包括基于MPP架构的Presto、SparkSQL,预计算架构的Kylin、Druid,搜索引擎架构的ES,纯列存的ClickHouse以及基于内存的SnappyData。详细讨论了它们在数据规模、查询性能、灵活性、易用性、处理方式和实时性等方面的优缺点。
本文对比分析了多种开源OLAP引擎,包括基于MPP架构的Presto、SparkSQL,预计算架构的Kylin、Druid,搜索引擎架构的ES,纯列存的ClickHouse以及基于内存的SnappyData。详细讨论了它们在数据规模、查询性能、灵活性、易用性、处理方式和实时性等方面的优缺点。
开源OLAP引擎对比
OLAP简介
- OLAP(On-Line Analytical Processing),即联机分析处理,其主要的功能在于方便大规模数据分析及统计计算,对决策提供参考和支持
- 特点
- 数据量大
- 高速响应
- 灵活交互
- 多维分析

- 分类
- 存储类型分类
- ROLAP(RelationalOLAP)
- MOLAP(MultidimensionalOLAP)
- HOLAP(HybridOLAP)
- 处理类型分类
- MPP架构
- 搜索引擎架构
- 预处理架构
- 开源OLAP解决方案
- Presto、SparkSQL、Impala以及SnappyData等MPP架构和ROLAP的引擎
- Druid和Kylin等预处理架构和MOLAP的引擎
- ES这种搜索引擎架构的
- ClickHouse以及IndexR这种列式数据库
分布式OLAP引擎分类及对比
- 从数据规模、查询性能、灵活性、易用性、处理方式以及实时性进行对比
基于MPP架构的ROLAP引擎
- 代表:Presto、Impala以及Spark SQL等利用关系模型来处理OLAP查询,通过并发来提高查询性能
- 优点
- 支持的数据规模大(非存储引擎)
- 灵活性高,随意查询数据
- 易用性强,支持标准SQL以及多表join和窗口函数
- 处理方式简单,无需预处理,全部后处理,没有冗余数据
- 缺点
- 性能较差,当查询复杂度高且数据量大时,可能分钟级别的响应。同时其不是存储引擎,因此没有本地存储,当join时shuffle开销大,性能差
- 举例:SparkSql为例子,其只是哥计算引擎,导致需要从外部加载数据,从而数据的实时性得不到保证;多表join的时候性能也很难得到秒级的响应
- 开源社区出现了一种依托于Spark SQL的AP引擎,如:TiSpark(TiKV作为存储)、SnappyData
- 实时性较差,不支持数据的实时导入,偏离线处理
预计算引擎架构的MOLAP
- 代表
- Kylin是完全的预计算引擎,通过枚举所有维度的组合,建立各种Cube进行提前聚合,以HBase为基础的OLAP引擎
- Druid则是轻量级的提前聚合(roll-up),同时根据倒排索引以及bitmap提高查询效率的时间序列数据和存储引擎
- 优点
- Kylin
- 支持数据规模超大(HBase)
- 易用性强,支持标准SQL
- 性能很高,查询速度很快
- Druid
- 支持的数据规模大(本地存储+DeepStorage–HDFS)
- 性能高,列存压缩,预聚合加上倒排索引以及位图索引,秒级查询
- 实时性高,可以通过kafka实时导入数据
- 缺点
- Kylin
- 灵活性较弱,不支持adhoc查询;且没有二级索引,过滤时性能一般;不支持join以及对数据的更新
- 处理方式复杂,需要定义Cube预计算;当维度超过20个时,存储可能会爆炸式增长;且无法查询明细数据了;维护复杂
- 实时性很差,很多时候只能查询前一天或几个小时前的数据
- Druid
- 灵活性适中,虽然维度之间随意组合,但不支持adhoc查询,不能自由组合查询,且丢失了明细数据
- 易用性较差,不支持join,不支持更新,sql支持很弱(有些插件类似于pinot的PQL语言),只能JSON格式查询;对于去重操作不能精准去重
- 处理方式复杂,需要流处理引擎将数据join成宽表,维护相对复杂;对内存要求较高
- 场景
- Kylin:适合对实时数据需求不高,但响应时间较高的查询,且维度较多,需求较为固定的特定查询;而不适合实时性要求高的adhoc类查询
- Druid:数据量大,对实时性要求高且响应时间短,以及维度较少且需求固定的简单聚合类查询(sum,count,TopN),多以storm和flink组合进行预处理;而不适合需要join、update和支持SQL和窗口函数等复杂的adhoc查询;不适合用于SQL复杂数据分析的场景
搜索引擎架构
- 代表
- ES是典型的搜索引擎类的架构系统,在入库时将数据转换为倒排索引,采用Scatter-Gather计算模型提高查询性能。- 对于搜索类的查询效果较好,但当数据量较大时,对于Scan类和聚合类为主的查询性能较低
- 优点
- 性能较高,支持倒排索引和各种过滤后的聚合查询
- 实时性强,在文档上建立完索引后,立刻可以查询
- 处理方式简单,无需预处理
- 缺点
- 支持的数据规模较小,高并发不理想
- 灵活性差,不支持复杂的adhoc查询
- 易用性差,不支持SQL;DSL成本高,且不能精准去重
- 场景
-ES适合那种全文检索,且数据规模较少时过滤条件很多的聚合查询,并发度也不大的场景。
- 同样,如果分析人员想用SQL分析,那么也不适合ES
纯列存OLAP
- 代表
- ClickHouse是个列存数据库,保存原始明细数据,通过MergeTree使得数据存储本地化来提高性能
- 是个单机版超高性能的数据库
- 优点
- 性能高,列存压缩比高,通过索引实现秒级响应
- 实时性强,支持kafka导入
- 处理方式简单,无需预处理,保存明细数据
- 缺点
- 数据规模一般
- 灵活性差,不支持任意的adhoc查询,join的支持不好。
- 易用性较弱,SQL语法不标准,不支持窗口函数等;维护成本高
- 场景
- 适合数据规模不大情况下的单机且单表的数据分析
基于内存的SnappyData
- 代表
- SnappyData是个计算与存储引擎,全内存、行列混合存储且完全不需预处理,支持SQL与Spark SQL
- 兼顾MPP的特点且colocate特性使得数据本地化,支持join、列表的update以及窗口函数等任意的adhoc查询
- 优点
- 性能高,列存压缩+全内存,数据状态共享,秒级查询
- 实时性强,支持kafka的stream table以及实时导入
- 处理方式简单,无需预处理,保存明细数据,数据本地存储
- 灵活性高,是个sql数据库,支持任意字段的查询、update以及窗口函数和复杂的adhoc查询
- 易用性强,支持标准SQL和Spark SQL,精准去重,支持各种分许函数
- 缺点
- 数据规模中等,由于全内存导致成本较高,且需要关注GC问题
- 维护成本高
- 场景
- SnappyData适合那种数据规模中等(PB以下),需求变化较多,实时性要求较高、响应时间较短且复杂的窗口函数类查询;同时适合查询明细数据以及探索式的adhoc查询
- 如果数据规模不大,且希望找到一种简单易用且实时性要求高的多维OLAP引擎,最重要的是可供分析人员使用的SQL的引擎,那么SnappyData比较适合。前提是需要在成本与效率之间做个平衡,SQL固然能提高开发效率,但内存较大的服务器成本也确实相对较高
对比
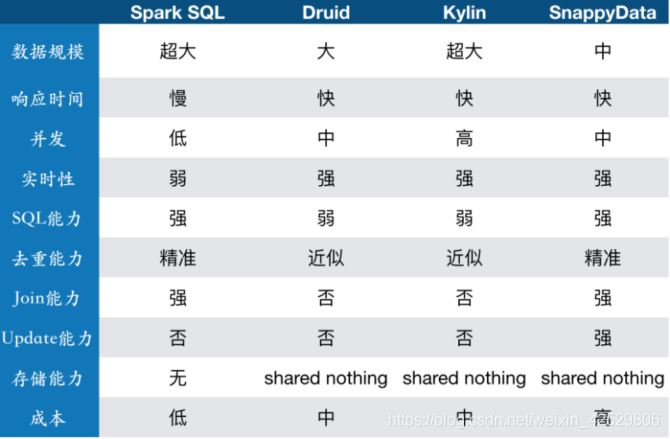
| 指标 | Spark SQL | Druid | Kylin | SnappyData |
|---|---|---|---|---|
| 数据规模 | 超大 | 大 | 超大 | 中 |
| 响应时间 | 慢 | 快 | 快 | 快 |
| 并发 | 低 | 中 | 高 | 中 |
| 实时性 | 弱 | 强 | 强 | 强 |
| SQL能力 | 强 | 弱 | 弱 | 强 |
| 去重能力 | 精准 | 近似 | 近似 | 精准 |
| Join能力 | 强 | 否 | 否 | 强 |
| Update能力 | 否 | 否 | 否 | 强 |
| 存储能力 | 无 | sharded nothing | sharded nothing | sharded nothing |
| 成本 | 低 | 中 | 中 | 高 |

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









