






过滤器
- 概念:用来过滤用户的请求和响应,修改用户请求和响应的数据,对请求进行拦截
- 作用:
-
解决全局乱码问题
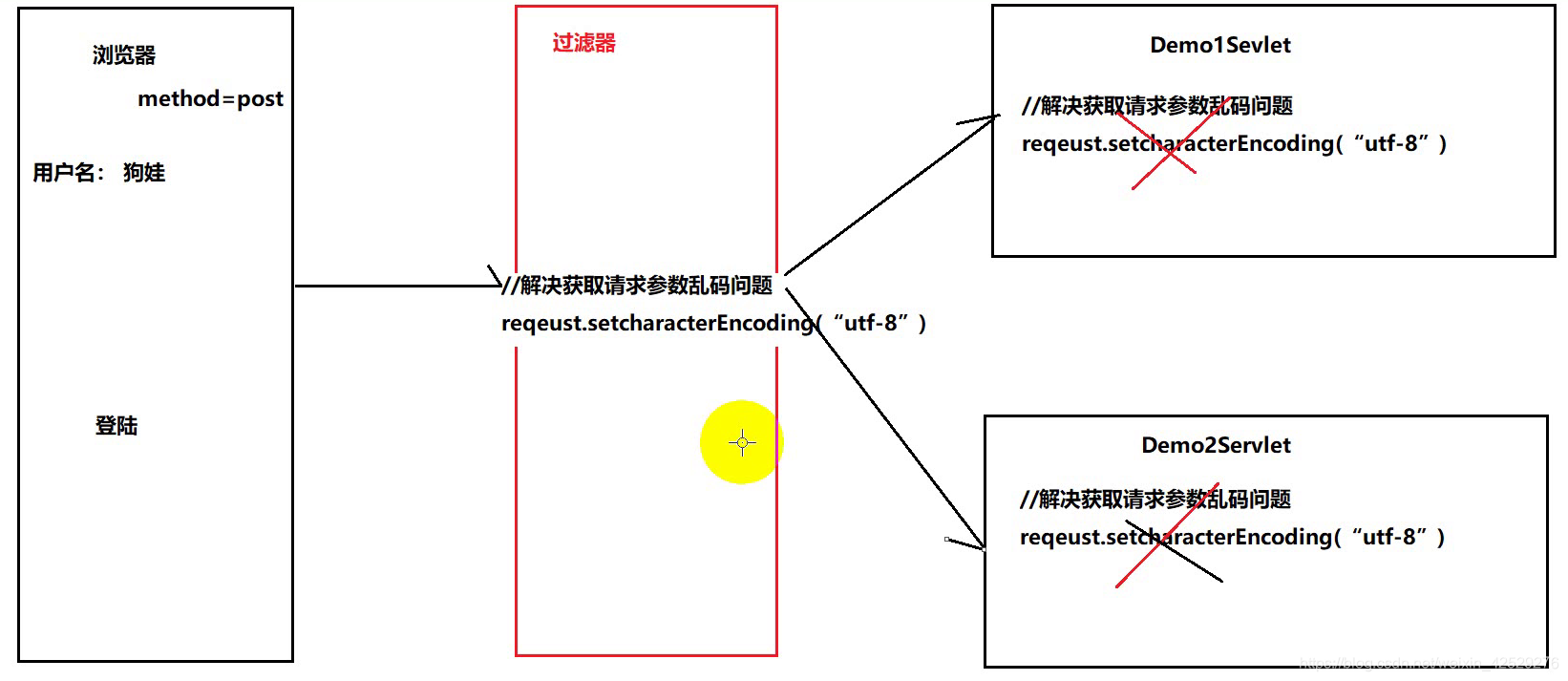
-
过滤论坛发表内容中的非法字符
-
登录权限的检查
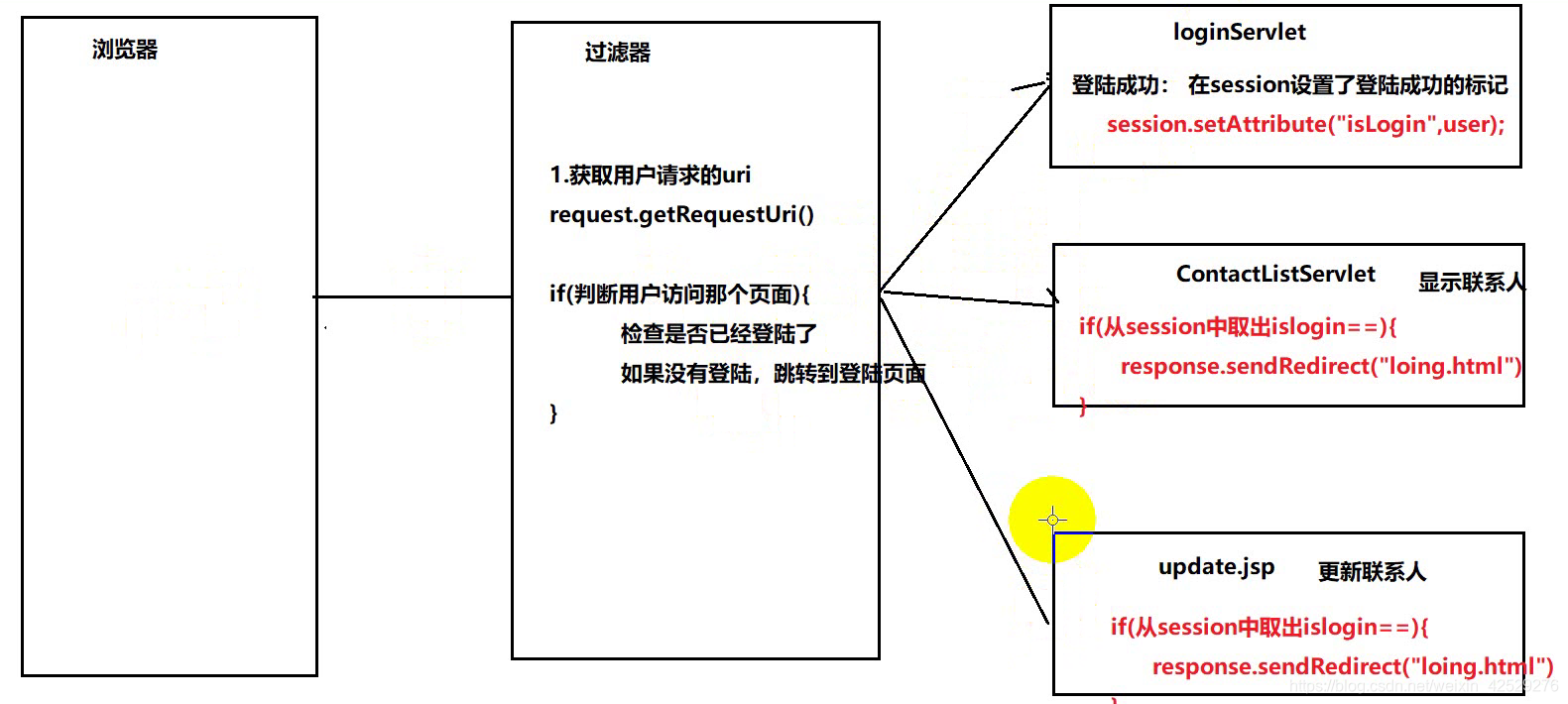
- 使用过滤器
步骤:
(1) 创建类实现Filter接口
(2) 注解配置过滤器拦截的请求路径
(3) 在doFilter方法中描写过滤任务
(4) 调用chain.Filter方法放行 - 注意事项:
(1) Filier类是一个接口
(2) 只有访问过滤器请求路径指定的网页才会执行过滤功能
(3) doFilter方法默认拦截请求,如果需要经过过滤器之后可以继续访问资源,需要调用chain.Filter方法放行 - 过滤器的执行流程
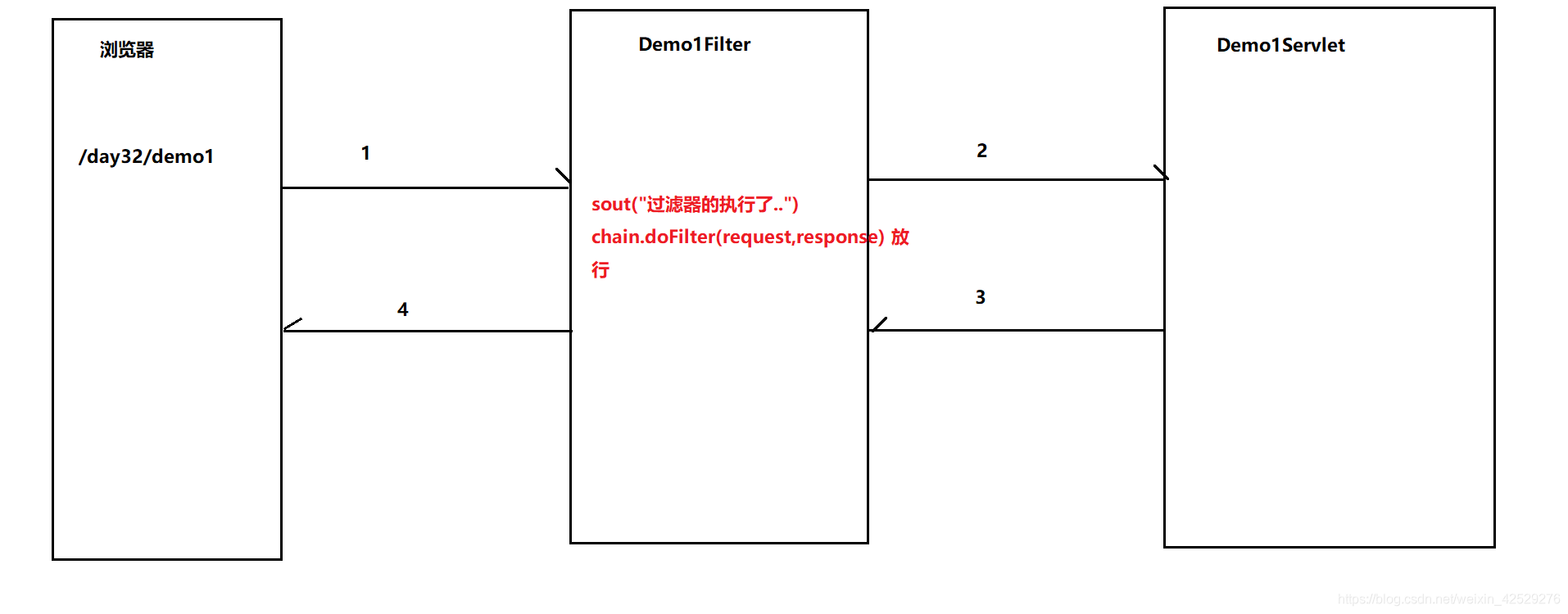
先执行Demo1Filter的doFilter方法,如果存在chain.doFilter放行就执行Demo1Servlet,再回到Demo1Filter - 过滤器的生命周期
过滤器的生命周期相关的方法包括三个,分别是:init,doFilter,destroy
- init方法
创建Filter对象的时候调用init方法,服务器启动则会创建Filter对象,调用init方法,并说明Filter对象在内存中只有一个
应用场景:配置文件的代码可以放在init方法中执行,这样配置文件代码只会自行一次 - doFilter方法
每次请求符合过滤路径就会执行一次 - destroy方法
Filter对象销毁的时候会执行destroy方法,服务器重启或关闭的时候会销毁Filter对象,从而执行destroy方法
-
映射路径
介绍:配置过滤器不同的映射路径可以让过滤器有选择地过滤请求
7.1 精准匹配
路径为完整路径,比较"/demo01",“/1.html”。只有访问demo01或者1.html的时候才会执行过滤功能
7.2 模糊匹配(必须使用到通配符"*“)
使用规则:
(1) 如果是”/"开头的路径,必须以*符号结尾。如果*不在结尾,则*通配符失效,失去通配符的作用,变成普通的*
使用:- 映射路径为:/*,则表示过滤全局资源
- 映射路径为:/目录名称…/*,表示要访问目录下的所以文件时,会执行过滤功能
(2) 如果需要匹配后缀名,则必须需要以"*"符号开头。比如*.jsp,*.html
-
拦截方式
注意:过滤器只会过滤url地址直接访问和请求重定向的资源,不会拦截请求转发的资源
8.1 拦截方式类别
(1) request,默认的拦截方式,只会过滤url地址直接访问和请求重定向,不会拦截请求转发
(2) forward,只会拦截请求转发的资源
配置方式:dispatcherTypes用于配置拦截方式
在@WebFilter()中配置dispatcherTypes的属性,dispatcherTypes = dispatcherType.REQUEST或FORWARD
注意:dispatcherTypes是一个数组类型,如果想要过滤三种方式的资源,可以赋值一个数组值,如:dispatcherTypes = {dispatcherType.REQUEST,dispatcherType.FORWARD} -
过滤器链
- 概念: 访问资源的时候会经过多重过滤,多个过滤器组合成过滤器链
- 执行流程
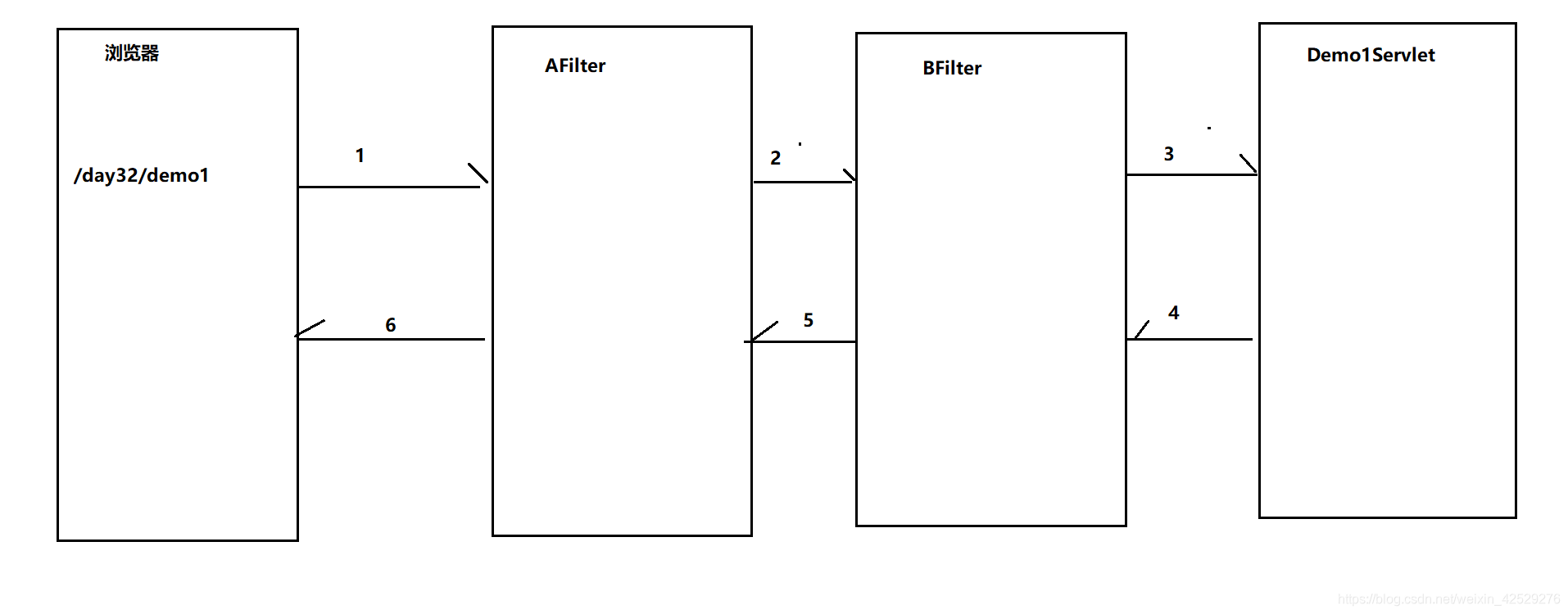
- 注意实现:
(1) 如果访问一个资源需要经过多个过滤器,则过滤器的执行顺序取决于Filter的类名的字符串顺序,与filterName无关(不推荐)
(2) 把filter的信息配置在web.xml文件上,执行顺序按照web.xml的先后配置执行(推荐)
配置过程:
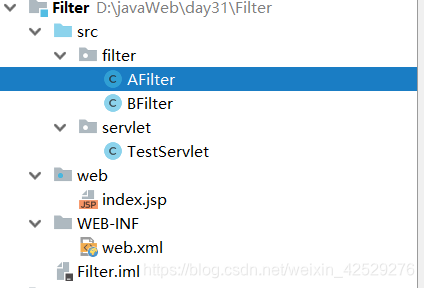
项目中存在的文件
AB过滤器都要过滤TestServlet
在web.xml文件中配置过滤器的映射路径,先配置哪个过滤器哪个就先执行
<?xml version="1.0" encoding="UTF-8"?>
<web-app xmlns="http://xmlns.jcp.org/xml/ns/javaee"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://xmlns.jcp.org/xml/ns/javaee http://xmlns.jcp.org/xml/ns/javaee/web-app_3_1.xsd"
version="3.1">
<!-- 先配置哪个过滤器哪个过滤器则先执行 -->
<!--先配置了B过滤器所以先执行B过滤器-->
<!-- 配置Filter的基本信息 -->
<filter>
<!--别名-->
<filter-name>BFilter</filter-name>
<!--完整类名-->
<filter-class>filter.BFilter</filter-class>
</filter>
<!--映射信息-->
<filter-mapping>
<!--别名-->
<filter-name>BFilter</filter-name>
<!--映射路径-->
<url-pattern>/demo01</url-pattern>
</filter-mapping>
<filter>
<filter-name>AFilter</filter-name>
<filter-class>filter.AFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>AFilter</filter-name>
<url-pattern>/demo01</url-pattern>
</filter-mapping>
</web-app>
运行结果

执行顺序:B->A->servlet->A->B
案例一
- 需求:过滤言论,屏蔽不文明词汇,将不文明词汇变成*
- 代码
package filter;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import java.io.*;
import java.util.ArrayList;
import java.util.List;
//检测言语
@WebFilter(filterName = "TalkFilter",urlPatterns = "/talk")
public class TalkFilter implements Filter {
private List<String> list = new ArrayList<>();
public void init(FilterConfig config) throws ServletException {
//加载配置文件,将内容存入集合中
try {
//1.得到配置文件的流对象
InputStream resourceAsStream = TalkFilter.class.getResourceAsStream("/improper/improperLanguage.txt");
//2. 将字节流转成字符流,InputStreamReader流默认编码方式为gbk,所以需要指定编码方式为utf-8
InputStreamReader reader = new InputStreamReader(resourceAsStream,"utf-8");
//3. 得到BufferedReader对象,从而可以是用该类的readLine()方法
BufferedReader bufferedReader = new BufferedReader(reader);
//4. 开始存储数据
String line = null;
while((line = bufferedReader.readLine()) != null){
list.add(line);
}
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
}
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException {
//解决中文输出乱码问题
resp.setContentType("text/html;charset=utf-8");
PrintWriter out = resp.getWriter();
//拦截言论
//1. 得到用户输入的言论
String content = req.getParameter("talk");
boolean key = false;
//2. 开始检测
for (String con : list) {
if(content.contains(con)){
key = true;
content = replaceImproperChar(content,con);
}
}
if(key){
out.write(content);
return;
}else{
//放行
chain.doFilter(req, resp);
}
}
public void destroy() {
}
private String replaceImproperChar(String content, String replaceStr){
//得到首字母所在的索引
int index = 0;
do {
index = content.indexOf(replaceStr);
if(index >= 0){
//转成char类型数组
char[] contentCharArray = content.toCharArray();
//开始替换
for(int i = 0; i < replaceStr.length(); i++){
contentCharArray[index + i] = '*';
}
content = new String(contentCharArray);
}
}while(index >= 0);
return content;
}
}
案例二
- 需求:解决全站的中文输出乱码问题和post请求接受中文乱码问题
- 代码
package filter;
import javax.servlet.*;
import javax.servlet.annotation.WebFilter;
import javax.servlet.http.HttpServletRequest;
import java.io.IOException;
//解决全站的乱码问题和post请求接受中文乱码问题
@WebFilter(filterName = "CharacterFilter", urlPatterns = "/*")
public class CharacterFilter implements Filter {
public void destroy() {
}
public void doFilter(ServletRequest req, ServletResponse resp, FilterChain chain) throws ServletException, IOException {
//解决全站乱码问题
resp.setContentType("text/html;charset=utf-8");
//解决post请求接受乱码问题
//1. 强制类型转换,ServletRequest是HttpServletRequest的父类
HttpServletRequest request = (HttpServletRequest) req;
//2. 调用getMethod方法得到请求方式
String method = request.getMethod();
//3. 判断,如果是post方法则将编码方式设置为utf-8
if("post".equalsIgnoreCase(method)){
request.setCharacterEncoding("utf-8");
}
chain.doFilter(req, resp);
}
public void init(FilterConfig config) throws ServletException {
}
}

















 9846
9846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









