






 本文探讨了三种不同的树结构在数据库索引中的应用,包括二叉排序树、B树和B+树,其中B+树是MySQL数据库常用的索引结构。B+树的特点在于数据集中在叶子节点,能有效支持范围查找。此外,文章还对比了MyISAM和InnoDB两种存储引擎的差异,InnoDB由于其聚集索引特性,在查找效率上更优。对于InnoDB表,建议使用int类型自增主键以优化B+树的构建。最后,文章提到了hash索引的局限性,不适用于范围查找和全表扫描场景。
本文探讨了三种不同的树结构在数据库索引中的应用,包括二叉排序树、B树和B+树,其中B+树是MySQL数据库常用的索引结构。B+树的特点在于数据集中在叶子节点,能有效支持范围查找。此外,文章还对比了MyISAM和InnoDB两种存储引擎的差异,InnoDB由于其聚集索引特性,在查找效率上更优。对于InnoDB表,建议使用int类型自增主键以优化B+树的构建。最后,文章提到了hash索引的局限性,不适用于范围查找和全表扫描场景。
1.首先介绍一下树三棵树
1)二叉排序树
找个例子来说,输入:
4 3 7 5 6 10 9
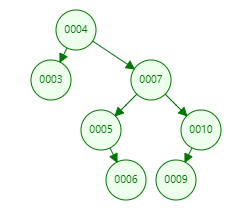
产生这样的搜索结构的话,当我们查找9,只用查找4次
会出现极端状态:如按序输入1-8
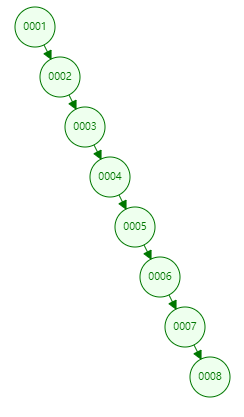
可见,使用二叉树当索引结构并不合适,I/O次数太多
2)B树(又叫B-树)
当我们想减少I/O次数,那就得减少树的高度,但是数据量恒定的情况下,高度减少意味着宽度得增加,从而引入B树的概念
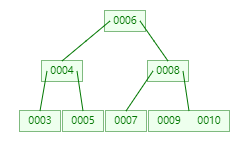
以这个B树来看,节点可以容纳多个元素,高度为3,也就是最多I/O三次,从而找到想要的数据
3)B+树(MySql数据库索引使用的是B+树)
B+树是B树的一个变形,且数据都保存在叶子节点,其余节点仅保存地址
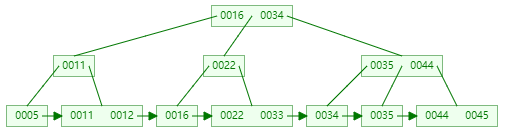
这是数据库索引使用的结构
以Mysql来说,一个节点默认可以存 16384b
而节点里面一个元素的大小为:14b=8b索引(如0016)+6b地址(箭头)
也就是说,一个地址节点可以存:16384/14=1170个元素
当数的高度为4,就能支持百万、千万的数据量
2.Mysql存储引擎
存储引擎是指定到表的
1)MyISAM:使用非聚集索引,索引文件和数据文件是分离的
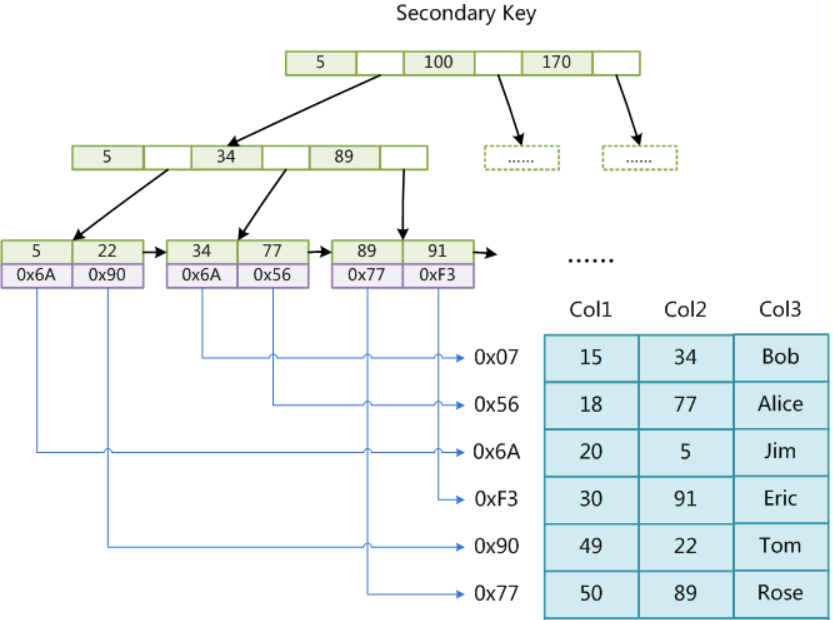
2)InnoDB:使用聚集索引,索引文件和数据文件放在一起
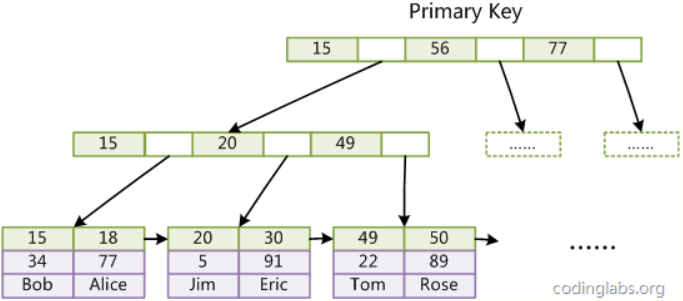
总结:
InnoDB在叶子节点就可以直接取到数据,
MyISAM在叶子节点取到数据的地址,然后还要进行一个I/O操作,才能取到数据
因此,InnoDB的执行效率会高一点
3.常见面试题
1)为什么InnoDB表必须要有主键,我没设置主键也能新增成功呀?
InnoDB表需要组建B+树,当没有指定唯一索引的时候,会从左到右依次找,找到一列满足唯一索引条件的,用这一列来组建B+树;当没有符合条件的列的时候,会自己生成一个隐藏列,用来构建B+树;因此,InnoDB表最好自己指定主键。
2)为什么InnoDB表主键推荐使用int自增主键?
int类型容易比较大小。
举个反例:如果使用UUID当主键,那很难去比较大小,构造B+树很困难,而且会占用更多的空间
自增是为了让叶子节点从左到右依次递增,这样可以避免已经存满的叶子节点去列分,从而产生性能和空间的消耗。
3)为什么基本不用hash索引?
Mysql索引分为【B+树索引】和【hash索引】
B+树索引上面介绍了,这里聊聊hash索引,hash索引是把索引列经过hash算法进行关联,这里把col1当初索引列吧
select * from table where col1=1
hash是通过hash算法快速定位数据的,这里会把col1=1通过hash算法进行定位,所以时间复杂度是O(1),效率非常高。
那么问题来了,为什么效率这么高却没人使用,主要是:
select * from table where col1>1
出现这种范围查找,hash就跪了
还有hash不能避免全表扫描,数据量大检索效率低等问题
4)B+树是怎么实现范围查找的
B+树的叶子节点是从左到右依次递增的,而且各节点之间存在双向指针,可以很好的支持范围查找

















 3633
3633

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









