







文章目录
- 1、读取指定sheet和指定列的内容
- 2、遍历数据,对两列数据相似度比较
- 3、遍历数据,统计每类分类变量的数量
- 4、遍历数据,删除某列为特定值的数据
- 5、正则去掉字符串左边或者右边的内容
- 6、正则取出固定位置的字符
- 7、正则匹配判断字符串中是否含有中文
- 8、list添加删除连接元素
- 9、函数变量声明
- 10、input对话框获取实时输入
- 11、字符串的换行显示
- 12、常用转义字符
- 13、字符串的连接
- 14、多个空格替换成其他符号
- 15、获取某个字符串左边/右边的内容
- 16、四舍五入和大小比较
- 17、读取某列为指定内容的所有行
- 18、统计作者数量并增加为新的列
- 19、将某一列连续变量虚拟化
- 20、删去某列为指定内容的行
- 21、判断某列中每行的值,并且做出替代
- 22、去掉某列中为空值的行
- 23、删除某列为指定值的行
- 24、对某列进行重命名
- 25、填充某列的空值
- 26、修改某列数据类型
- 27、删除前几列
- 28、合并指定列相同的两个表
- 29、正则替换字符串中的所有数字
1、读取指定sheet和指定列的内容
data = pd.read_excel("data.xlsx",sheet_name="Sheet1",usecols=["year","code1","code2","name","keywords","type",'new'])
2、遍历数据,对两列数据相似度比较
for i in range(0,75065):
if data.loc[i]['code2']!=0:
if data.loc[i]['code1'][:5]==data.loc[i]['code2'][:5]:
data.loc[i,'inter']=0
elif data.loc[i]['code1'][:3]==data.loc[i]['code2'][:3]:
data.loc[i,'inter']=1
elif data.loc[i]['code1'][:1]==data.loc[i]['code2'][:1]:
data.loc[i,'inter']=2
else:
data.loc[i,'inter']=3
3、遍历数据,统计每类分类变量的数量
list= ['fund','year','inter','age','degree','title','institute','economy','gender','type']
for i in range(0,10):
print(data[list[i]].value_counts())
4、遍历数据,删除某列为特定值的数据
df_clear = data.drop(data[data['discipline']=="H"].index)
5、正则去掉字符串左边或者右边的内容
import re
template = "DF','17340','http://www.zgglkx.com','2021','205')"
delete_left = template.lstrip('"DF')
print(delete_left)
delete_right = template.rstrip('205\')')
print(delete_right)
结果:
','17340','http://www.zgglkx.com','2021','205')
DF','17340','http://www.zgglkx.com','2021',
6、正则取出固定位置的字符
template = "DF','17340','http://www.zgglkx.com','2021','205')"
res = re.findall(r"DF','(.*?)',",template)[0]
print(res)
结果:
17340
Process finished with exit code 0
7、正则匹配判断字符串中是否含有中文
import re
Pattern = re.compile(u'[\u4e00-\u9fa5]+')
key='[25] 张初兵,荣喜民.仿射利率模型下确定缴费型养老金的最优投资[J]. 系统工程理论与实践,2012,32(5):1048-1056. Zhang Chubing, Rong Ximin. Optimal investment for DC pension under the affineinterest rate model[J]. Systems Engineering-Theory & Practice, 2012, 32(5):1048-1056.'
match = Pattern.search(key)
if match:
print("存在中文")
8、list添加删除连接元素
在最后添加元素
list.append()
从最后删除元素
a = list.pop()
用#连接列表的元素
'#'.join(list[3:5])
9、函数变量声明
def sum(*args):
a,b,c=args
d = a+b+c
print({f"The sum is {d}.")
输入:
sum(1,2,3)
输出:
The sum is 6.
10、input对话框获取实时输入
age = input("how old qre you: ")
print("I am ",age,"years old")
结果:
how old are you: 2
I am 2 years old
Process finished with exit code 0
11、字符串的换行显示
print('''
I
nned
money
''')
结果:
I
nned
money
Process finished with exit code 0
12、常用转义字符
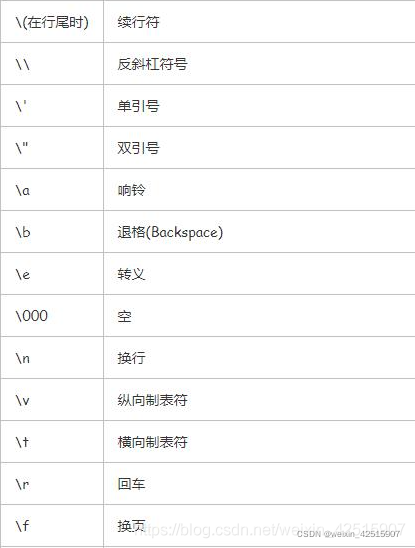
13、字符串的连接
name = 10
height =100
print(f"I am {name} years old and I am {height} cm.")
name = 10
height =100
st = f"I am {name} years old and I am {height} cm."
print(st.format(name,height))
14、多个空格替换成其他符号
import re
str1 = '2020 第一卷 第五期'
str2 = re.sub(' +', ';', str1)
print(str2)
``
结果:
```python
2020;第一卷;第五期
15、获取某个字符串左边/右边的内容
string1 = string[0:string.rfind('[')]
string2 = string[string.rfind('[')+1:]
16、四舍五入和大小比较

math模块的cell函数:
返回大于等于参数的最大整数
def ceil(*args, **kwargs): # real signature unknown
"""
Return the ceiling of x as an Integral.
This is the smallest integer >= x.
"""
pass
floor函数
返回小于等于函数的最大参数
def floor(*args, **kwargs): # real signature unknown
"""
Return the floor of x as an Integral.
This is the largest integer <= x.
"""
pass
17、读取某列为指定内容的所有行
data = data.loc[data["year"]==2016]
18、统计作者数量并增加为新的列
for i in range(2960):
data.loc[i,'author_num']=len(data.loc[i]['AU'].split(";"))
19、将某一列连续变量虚拟化
比if语句快很多很多
data['AP']=data.apply(lambda x:1 if x['DT'] == "Article; Proceedings Paper" else 0,axis=1)
20、删去某列为指定内容的行
data= data.drop(data[data['DT']=="Review"].index)
21、判断某列中每行的值,并且做出替代
data['AP']=data.apply(lambda x:1 if x['DT'] == "Article; Proceedings Paper" else 0,axis=1)
22、去掉某列中为空值的行
data1= data1.dropna(axis=0,subset = ["ID_num"])
23、删除某列为指定值的行
data1 = data1.drop(data1[data1['PG']>100].index)
24、对某列进行重命名
data1 = data1.rename(columns={'Journal Impact Factor': 'JIF'})
25、填充某列的空值
data1['CY2'] = data1['CY2'].fillna(value = 0)
26、修改某列数据类型
data1[["CY2"]] = data1[["CY2"]].astype(int)
27、删除前几列
data1 = data1.drop(data1.columns[[0,1]],axis=1)
28、合并指定列相同的两个表
data3 = pd.merge(data1,data2,on=['TC','JIF','PG','TI_num','Keywords','Ref_num','FU','SI','OA','Year'])
29、正则替换字符串中的所有数字
re.sub(r'\d',',',a)
\d就是找到字符串中的所有数字,a是待处理的字符串,中间的‘,’是想要替换成的内容


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









