



**强大的爬虫利器scrapy(介绍与安装)!
scrapy简介:
scrapy是一个爬取较高水平网站的数据抓框架,用于爬取网站跟从它们的页面提取数据,并且用途范围很广,从数据挖掘到数据监控再到自动化测试。
scrapy各部分及其功能:
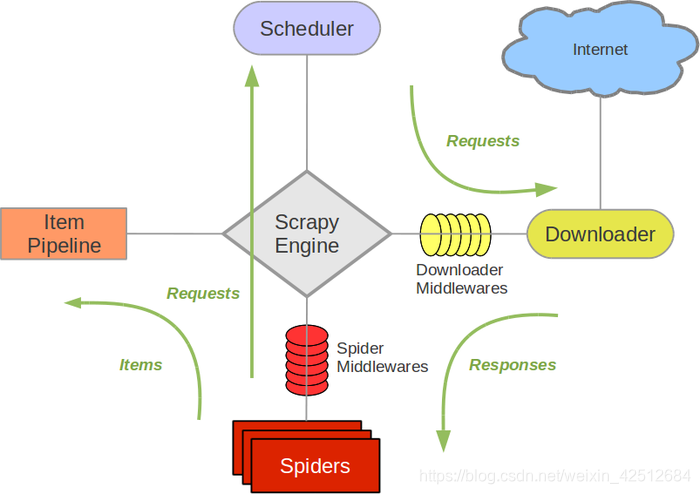
Scrapy engine(引擎):框架中最为核心的部分,负责Scheduler,Downloader、Item Pipeline、Spiders 等各部分的数据之间的传递协调功能;
Scheduler(调度器):将engine中的请求放入队列中,引擎需要时再传递给它;
Downloader(下载器):负责将数据下载下来,然后再通过engine传递给Spiders;
Spiders(爬虫):用来编写提取页面item数据的核心代码,处理response,将需要请求的url传递给engine中进行处理;
Item Pipeline(类别管道):用于将数据分类为各items
,将数据分类,存储,过滤等操作的地方;
额外两个:
**Downloader Middlewares(下载中间件)跟Spider Middlewares(爬虫中间件)**是两个自定义的扩充组件,根据自己爬虫需要可以自定义创建需要的组件;
(例如我需要一个有ip代理更换的功能,就可以通过在Middlewares中怎加一个代理类中间件,然后再setting中激活,就能达到全局更换ip的功能。)
scrapy的安装与遇到的坑:
scrapy框架的使用需要依赖几个python库,所以scrapy的安装需要提前安装以下几个库:
1,wheel, 可以用在命令行中输入pip install wheel的方法之间安装,(前提是pip已经配置到环境变量中了)
2,lxml,也可以利用pip 安装;
以下的三个库当利用pip方法安装失败的时候,就需要把去python库的网站中下载其whl文件于本地,再利用pip进行安装:
pip install xxx(xxx为你所需要安装库的安装路经加文件名称)
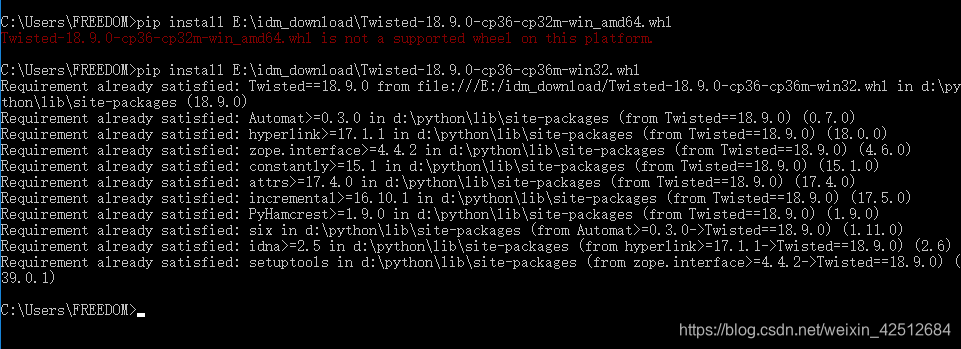
备注:在以下三种库用第二种方法安装过程可能会出现一种报错:xxx is not a supported wheel on this plartform (xxx库的版本不支持,,,)
此时就需要在自己的python编译器中中打印出来当前
pip 所支持库的安装版本,然后对库的名称进行修改;
代码如下:
import pip._internet
print(pip_internet.pep .pep425tags.get_supported( ))
例如我的pip所支持库的版本:

而我下载的文件为:

因为(cp36,cp36m,win32)跟我下载文件中的(cp36,cp32m,win_amd64)的不一样,这时候我就需要更改一下文件的名称使其以致,然后再进行安装
例如我安装twisted时:
3,Pyopenssl库的安装
下载地址:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#Pyopenssl
4,pywin32 库的安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pywin32
5,Twisted库的安装
https://www.lfd.uci.edu/~gohlke/pythonlibs/#Twisted
以上的库都安装完毕之后就可以用 pip install scrapy 的命令行,scrapy就会成功的安装上我们的电脑上。
总结:
以上就是关于scrapy框架的介绍以及整个安装过程,接下来的的文章呢,就是关于scrapy 框架的基本使用。
个人公众号:zeroing说
喜欢,分享,让我们一起成长!


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











