







之前MDP框架我们总体上介绍了MDP的大致概念,现在来说说实现这个框架的细节概念。
我们知道一个智能体如果要到达指定的目标,在规划路径的时候,我们可以使用MDP最大化累计回报的方法来获取最优的线路。我们来看一个例子:
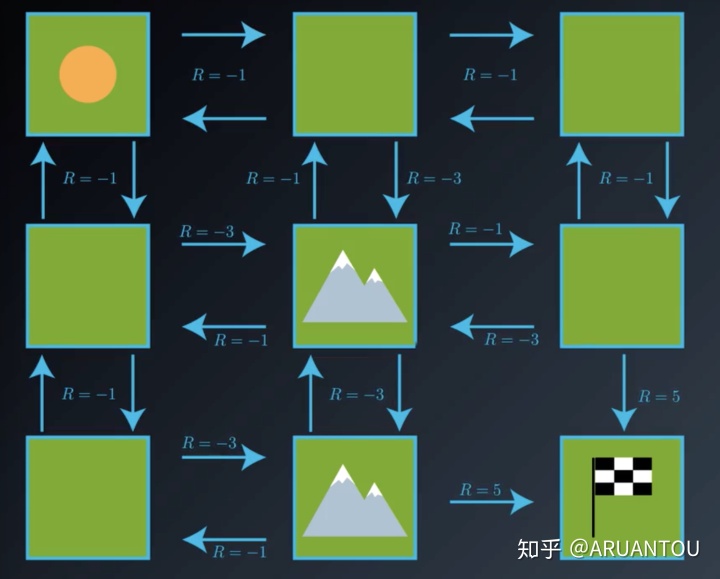
在这个网格世界,智能体想从左上角移动到右下角的目标位置,R代表的是从每一个位置移动懂下个位置的回报值。
好了,先来介绍第一个概念:
1.状态值函数
简单的说就是一定的策略下,在t时刻状态S下未来的累计回报值,
如果我们以一个非常傻逼的路径去到达目标,如下图,那么在起点处的状态值函数就是(-1 + -1 + -1 + -1 + -3 + -1 + -1 + -3 + 5)= -6
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3107
3107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









