






当GP集群有问题时,使用gprecoverseg恢复时,可能会遇到如下问题:
[CRITICAL]:-gprecoverseg failed. (Reason='FATAL: no pg_hba.conf entry for host "192.168.161.129", user "gpadmin", database "template1", SSL off
20200304:18:24:12:060245 gprecoverseg:cdh1:gpadmin-[INFO]:-2 segment(s) to recover
20200304:18:24:12:060245 gprecoverseg:cdh1:gpadmin-[INFO]:-Ensuring 2 failed segment(s) are stopped
20200304:18:24:13:060245 gprecoverseg:cdh1:gpadmin-[INFO]:-Ensuring that shared memory is cleaned up for stopped segments
20200304:18:24:14:060245 gprecoverseg:cdh1:gpadmin-[INFO]:-Updating configuration with new mirrors
20200304:18:24:14:060245 gprecoverseg:cdh1:gpadmin-[INFO]:-Updating mirrors
20200304:18:24:14:060245 gprecoverseg:cdh1:gpadmin-[INFO]:-Running pg_rewind on required mirrors
20200304:18:24:14:060245 gprecoverseg:cdh1:gpadmin-[CRITICAL]:-gprecoverseg failed. (Reason='FATAL: no pg_hba.conf entry for host "192.168.161.129", user "gpadmin", database "template1", SSL off
') exiting...
在确定各节点hosts文件填写无误后,pg_hba.conf是最有可能出现问题的,可检查pg_hba.conf文件
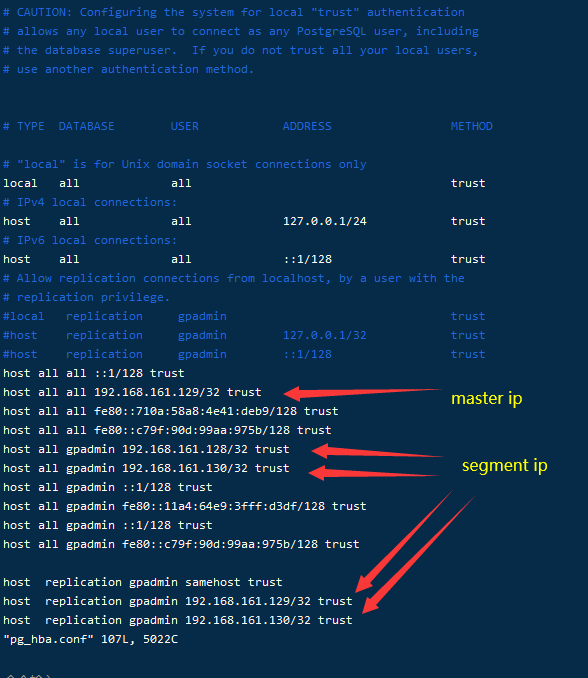
把所有segment节点的pg_hba.conf修改完成后 重启GP数据库
再此使用gprecoverseg恢复时,成功了!
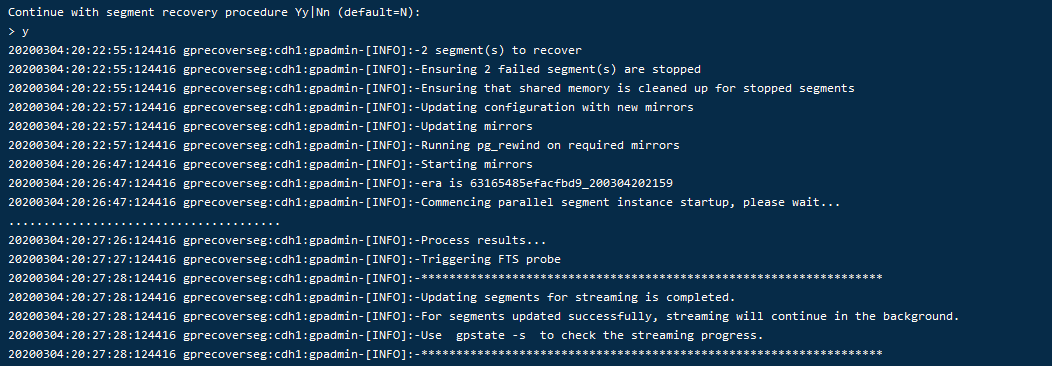
使用gprecoverseg -r 进行角色恢复
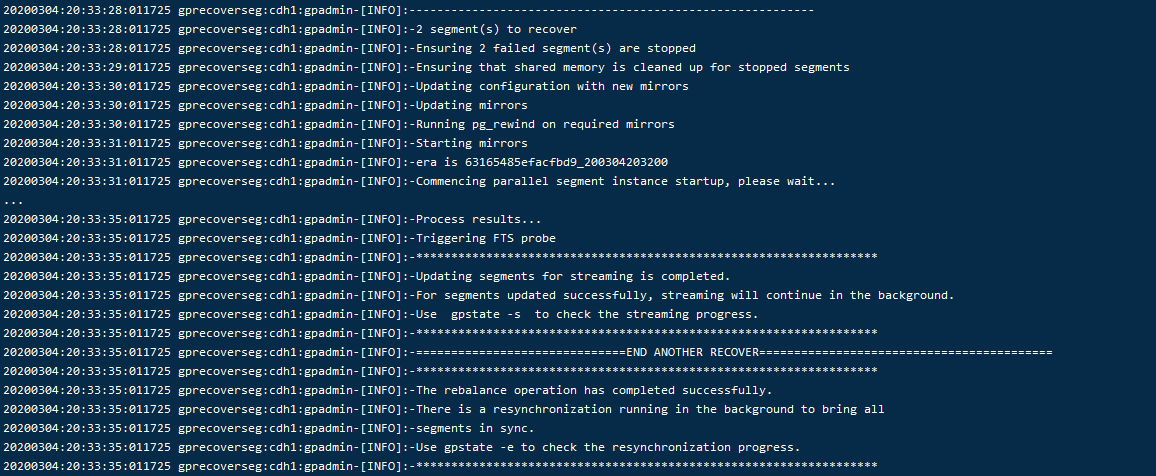
至此集群恢复正常~
(ip改变的话,此问题是比较容易的!)

















 546
546

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









