







简介:本书为Java企业级开发者提供了全面的教程,涉及Struts 2、Hibernate和Spring等核心框架。郑阿奇教授编写的第二版深入浅出地介绍了这些技术的关键概念和高级应用。电子教案以PPT形式呈现,帮助教师和学生更好地消化和理解教材内容。从自定义标签、数据校验到国际化和异常处理,再到ORM框架和Spring整合,本书为读者提供了一个实用的企业级JavaEE开发学习路径。 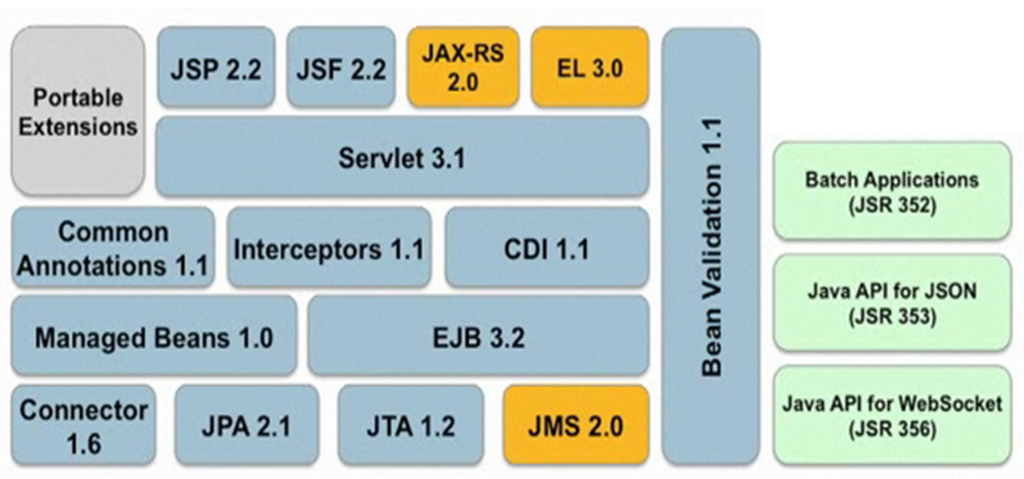
1. JavaEE开发基础与概念
JavaEE(Java Platform, Enterprise Edition)作为企业级应用的开发标准,它建立在JavaSE(Java Platform, Standard Edition)的基础之上,提供了大量用于开发大型、多层、分布式网络应用程序的API和运行时环境。本章将为初学者和有经验的开发者全面介绍JavaEE的核心概念、开发模型和基本结构,为深入学习后续章节打下坚实的基础。
1.1 JavaEE核心概念
JavaEE是Java平台的企业版,它定义了企业级应用开发的规范。与JavaSE相比,JavaEE更侧重于提供可伸缩性、组件化和多层架构的应用开发。JavaEE的核心组件包括Servlet、JSP(Java Server Pages)、EJB(Enterprise JavaBeans)等,这些组件通过JavaEE容器管理,简化了多层应用程序的开发。
1.2 JavaEE开发模型
JavaEE采用多层分布式开发模型,包括客户端层、Web层、业务层和集成层。开发者可以利用JavaEE服务器提供的服务,如事务管理、安全性、连接池和消息服务等,来开发可靠、安全、可扩展的企业级应用。
1.3 JavaEE应用服务器
JavaEE应用服务器是运行JavaEE应用的标准平台,它包括Apache Tomcat、GlassFish、WildFly、WebLogic和WebSphere等。这些服务器支持JavaEE规范,为应用提供了必要的运行时环境和容器服务,是部署JavaEE应用不可或缺的组件。
通过本章的学习,读者将对JavaEE有一个全局的认识,了解其核心组件、开发模型以及应用服务器的作用,为后续章节的深入探讨奠定基础。
2. Struts 2标签库应用与自定义
2.1 Struts 2标签库的使用
2.1.1 内置标签的介绍和使用
Struts 2的内置标签库是提供给开发者的一套丰富的标签集合,用于在JSP页面中实现特定的功能,如显示数据、处理表单等。熟悉这些内置标签能够极大提高开发效率,减少代码冗余。
以 <s:text> 标签为例,它是用于在JSP页面中显示字符串内容的标准标签。使用方法简单,只需要在标签内部包含要显示的文本或变量即可。例如:
<s:text name="greeting" />
这里 greeting 是定义在Struts配置文件中的一个消息,用于显示在页面上。
对于复杂的数据展示,可以使用 <s:iterator> 标签。该标签用于遍历集合或数组,支持对集合中的每一个元素进行操作。例如遍历一个用户列表并显示每个用户的姓名:
<s:iterator value="userList">
<p><s:property value="name"/></p>
</s:iterator>
在上述代码中, userList 是Action中返回的一个用户对象集合, <s:property> 用于显示当前遍历到的元素的某个属性。
内置标签不仅限于数据展示,还包括了表单处理、国际化、逻辑判断等各类实用标签。合理使用这些标签,可以使JSP页面代码更加清晰、易于维护。
2.1.2 自定义标签的创建和使用
尽管内置标签功能强大,但在实际开发中仍可能需要针对特定业务逻辑开发自定义标签。自定义标签扩展了Struts 2框架的功能,允许开发者封装特定的逻辑,然后在JSP页面中以标签的形式简单调用。
创建自定义标签需要编写标签类,并实现 com.opensymphony.xwork2.tag.Tag 接口或继承 com.opensymphony.xwork2.tag.TextSupportTag 类。例如,我们创建一个简单的自定义标签 <my:greet> ,用于在页面上显示特定的问候语:
package com.example.tags;
import com.opensymphony.xwork2.tag.TextSupportTag;
public class GreetTag extends TextSupportTag {
private String name;
public void setName(String name) {
this.name = name;
}
@Override
public int doStartTag() throws javax.servlet.jsp.JspException {
StringBuilder sb = new StringBuilder("Hello, ");
sb.append(name);
this.setBodyContent(sb.toString());
return EVAL_BODY_BUFFERED;
}
}
然后在 struts-tags.tld 文件中声明标签库及其标签:
<struts-tags>
<tag>
<name>greet</name>
<tag-class>com.example.tags.GreetTag</tag-class>
<body-content>empty</body-content>
<attribute>
<name>name</name>
<required>true</required>
<rtexprvalue>true</rtexprvalue>
</attribute>
</tag>
</struts-tags>
最后,在JSP页面中使用自定义标签:
<my:greet name="World" />
这将输出:"Hello, World"。通过这种方式,开发者可以封装复杂的业务逻辑,以简单的标签形式提供给页面使用,从而提高开发效率和代码的可维护性。
通过创建和使用自定义标签,开发团队可以构建自己的标签库,使得前端页面的代码更加模块化和可重用。这不仅有助于保持代码整洁,也有利于团队成员间的知识共享和协作。
2.2 Struts 2标签库的高级应用
2.2.1 标签库的扩展和优化
随着应用程序的增长,对于标签库的扩展和优化需求也会逐渐增加。扩展标签库可以是添加新的自定义标签、改善现有标签的功能或优化标签的性能。优化工作可以包括减少标签执行时的内存消耗、提高处理速度或减少生成的HTML代码量。
实现标签库扩展通常涉及以下几个方面:
- 性能优化: 分析现有标签执行时的性能瓶颈,并进行改进。例如,通过缓存技术减少对数据库的重复查询。
- 功能增强: 根据实际业务需求,开发新的自定义标签,提供更灵活的处理能力。
- 国际化支持: 确保标签库支持多语言环境,使应用能够适用于不同地区的用户。
- 安全性考虑: 确保标签库中的标签不会引入安全漏洞,如XSS攻击、SQL注入等。
例如,考虑一个 <s:url> 标签用于生成动态URL。我们可以扩展其功能,使其能够接受参数,并将参数嵌入到URL中:
<s:url action="myAction" var="myUrl">
<s:param name="id" value="%{myBean.id}"/>
</s:url>
在上面的示例中, <s:param> 标签用于向生成的URL添加名为 id 的查询参数,其值来自ActionContext中的 myBean.id 。
2.2.2 标签库的整合和实践应用
整合标签库意味着将自定义标签和内置标签组合在一起使用,以实现复杂的页面布局和数据处理。有效的整合可以让页面结构更加清晰,并能更好地遵循MVC的设计原则。
为了实现这一点,开发者需要:
- 理解业务需求: 在开始整合前,先明确业务需求,确定需要哪些标签和标签之间的交互方式。
- 设计标签使用策略: 设计一个清晰的策略来决定何时使用自定义标签、何时使用内置标签。
- 编写可维护的代码: 代码应该易于阅读和维护,尽量避免过度复杂的标签嵌套。
例如,一个典型的电商网站可能需要展示产品列表。可以结合 <s:iterator> 标签和自定义的 <my:product> 标签来实现:
<s:iterator value="products">
<my:product product="%{this}" />
</s:iterator>
在上述代码中, <my:product> 是一个自定义标签,负责根据传递的产品信息渲染产品详情。 <s:iterator> 标签负责遍历产品列表。这样,页面布局的逻辑与具体的渲染逻辑分离,提高了代码的可维护性。
整合标签库的成功实践依赖于对标签库的深刻理解和对业务逻辑的恰当把握。通过合理的整合,能够使开发团队快速响应需求变更,提升开发效率,最终构建出更加健壮、易维护的应用程序。
3. Struts 2类型转换与输入校验机制
3.1 Struts 2类型转换机制
3.1.1 类型转换的基本原理和实现
在Web应用中,用户提交的数据往往是字符串格式,而程序内部处理这些数据时需要将其转换为适当的数据类型。Struts 2提供了一套类型转换机制,用于在用户提交的数据与服务器端的数据类型之间进行转换。类型转换器(Type Converter)是这一机制的核心。
Struts 2使用OGNL(Object-Graph Navigation Language)作为默认的表达式语言,因此类型转换也与OGNL密切相关。默认情况下,Struts 2已经提供了基本数据类型的转换器,如将字符串转换为整数、浮点数等。当遇到复杂的数据类型转换时,可以通过实现 TypeConverter 接口来自定义转换逻辑。
类型转换的基本原理是,Struts 2会在处理用户输入的时候,根据目标属性的类型寻找合适的转换器进行转换。如果内置转换器无法满足需求,Struts 2会查找是否注册了自定义的转换器。
代码块示例 :
public class DateConverter implements TypeConverter {
@Override
public <T> T convertFromString(Map context, String[] values, Class<T> toType) {
if (values == null || values.length == 0 || toType != Date.class) {
return null;
}
String dateValue = values[0];
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd");
try {
return (T) dateFormat.parse(dateValue);
} catch (ParseException e) {
e.printStackTrace();
return null;
}
}
}
3.1.2 类型转换的优化和实践应用
在实践中,类型转换可能会遇到各种特殊情况,例如日期格式的多样性、地区差异导致的数字格式问题等。为了优化类型转换并适应不同场景,可以采取以下措施:
- 扩展内置转换器 :可以通过继承内置转换器并覆盖相应方法,来实现特定逻辑。
- 实现自定义转换器 :对于特殊的类型转换需求,如自定义对象的转换,需要实现自定义转换器。
- 配置全局转换器 :在
struts.xml中配置全局转换器,可以应用到所有的属性。 - 使用注解 :Struts 2支持在action类中使用
@Conversion注解来指定字段使用的转换器。
代码块示例 :
<global-convertions>
<conversion-converter type="com.example.DateConverter" conversion-id="customDateConverter"/>
</global-convertions>
通过上述方式,不仅可以解决类型转换过程中遇到的常见问题,还可以提高代码的可维护性和扩展性。
3.2 Struts 2输入校验机制
3.2.1 输入校验的基本原理和实现
输入校验是Web应用中确保数据合法性和安全性的重要环节。Struts 2提供了一套灵活的校验框架,允许开发者在数据提交到后端处理之前,对数据进行检查。
Struts 2的校验分为客户端校验和服务器端校验。客户端校验依赖于JavaScript,而服务器端校验则是必不可少的。Struts 2使用 Validator 框架来实现服务器端的校验逻辑。
校验逻辑通常定义在 validate() 方法中,该方法位于action类中。校验规则通过配置文件(如 validator-rules.xml )和应用特定的校验文件定义。
代码块示例 :
public class MyAction extends ActionSupport {
private String username;
private String password;
@Override
public void validate() {
if (username == null || username.trim().isEmpty()) {
addFieldError("username", "用户名不能为空");
}
if (password == null || password.trim().isEmpty()) {
addFieldError("password", "密码不能为空");
}
}
}
3.2.2 输入校验的优化和实践应用
为了提高校验机制的效率和效果,以下是优化输入校验的一些策略:
- 合理配置校验规则 :在
validator-rules.xml文件中配置通用的校验规则,避免在每个action中重复定义相同的校验逻辑。 - 使用注解进行校验 :Struts 2支持使用校验注解(如
@Required、@Email等)直接在字段上声明校验逻辑,简化代码。 - 组合校验器 :可以通过编写自定义的校验器,将常用的校验逻辑封装起来,实现复用。
- 分组校验 :在复杂的应用中,可以定义不同的校验分组,对应不同的业务场景,提高校验的灵活性。
代码块示例 :
@Action(value = "login", results = {
@Result(name = "success", location = "success.jsp"),
@Result(name = "input", location = "login.jsp")
})
@Validation专家组(RequiredFieldsValidatorGroup.class)
public class LoginAction extends ActionSupport {
@RequiredFieldValidator(message = "用户名是必填项")
private String username;
@RequiredFieldValidator(message = "密码是必填项")
private String password;
// getters and setters
}
通过上述的校验机制和优化策略,可以有效提高Web应用的数据处理能力和安全性。
4. Struts 2高级特性与综合应用案例
Struts 2框架不仅提供了基础的MVC模式实现,还具备一系列高级特性,这些特性可以极大地增强应用的灵活性和可维护性。本章我们将深入探讨Struts 2的高级特性,并通过综合应用案例来展示这些高级特性在实际开发中的运用。
4.1 Struts 2的高级特性
4.1.1 拦截器的应用和实现
拦截器是Struts 2框架中的核心概念之一,它允许开发者在动作方法执行之前或之后插入自定义的逻辑处理。这为开发者提供了一种灵活的方式来处理像权限验证、日志记录和输入校验等常见的横切关注点。
拦截器的工作流程通常遵循以下步骤:
- 用户发送请求到Struts 2框架。
- 框架查找匹配的拦截器栈。
- 拦截器按照栈的顺序执行,每个拦截器可以执行预处理(action执行前)和后处理(action执行后)操作。
- 动作类执行实际的业务逻辑。
- 拦截器再次按照栈的顺序执行后处理操作,但这次是在动作方法执行之后。
- 最终响应返回给用户。
示例代码
下面是一个简单的拦截器示例:
// MyInterceptor.java
import com.opensymphony.xwork2.ActionInvocation;
import com.opensymphony.xwork2.interceptor.Interceptor;
public class MyInterceptor implements Interceptor {
// 预处理操作
public String intercept(ActionInvocation invocation) throws Exception {
// 在动作方法执行前可以添加自定义的逻辑处理
System.out.println("MyInterceptor is intercepting...");
// 继续执行下一个拦截器或动作
String result = invocation.invoke();
// 后处理操作
System.out.println("MyInterceptor is post-processing...");
return result;
}
// 初始化方法(可选)
public void init() {}
// 销毁方法(可选)
public void destroy() {}
}
配置拦截器
拦截器的配置通常在struts.xml中进行:
<struts>
<package name="default" extends="struts-default">
<interceptors>
<interceptor name="myInterceptor" class="com.example.MyInterceptor"/>
<interceptor-stack name="myStack">
<interceptor-ref name="defaultStack"/>
<interceptor-ref name="myInterceptor"/>
</interceptor-stack>
</interceptors>
<action name="myAction" class="com.example.MyAction">
<interceptor-ref name="myStack"/>
<result name="success">/success.jsp</result>
</action>
</package>
</struts>
在这个配置中,我们定义了一个名为 myInterceptor 的拦截器,并将其添加到了一个名为 myStack 的拦截器栈中。这个栈被引用在 myAction 动作中,这意味着当 myAction 被请求时, myInterceptor 将被执行。
4.1.2 文件上传下载的应用和实现
Struts 2提供了一个专门的拦截器 fileUpload 来处理文件上传请求。文件上传功能是Web应用中非常常见的需求,借助这一拦截器,开发者可以轻松实现文件上传的功能。
文件上传实现步骤
- 添加依赖 :确保项目中包含了Apache Commons FileUpload和Apache Commons IO库。
- 配置拦截器 :在struts.xml中添加
fileUpload拦截器。 - 创建上传表单 :在JSP页面中创建一个文件上传表单。
- 编写动作类 :创建一个动作类,该类包含处理上传文件的业务逻辑。
- 处理上传文件 :在动作类中,使用
FileUploadInterceptor提供的ActionContext来获取上传的文件。 - 保存文件 :将获取的文件保存到服务器上指定的位置。
示例代码
// UploadAction.java
import com.opensymphony.xwork2.ActionSupport;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
import org.apache.commons.fileuploadporter.ProgressListener;
import org.apache.commons.io.IOUtils;
import javax.servlet.http.HttpServletRequest;
import java.io.File;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.util.List;
public class UploadAction extends ActionSupport {
private List<FileItem> fileItems;
@Override
public String execute() throws Exception {
if (ServletFileUpload.isMultipartContent(getRequest())) {
// 解析请求中的文件
DiskFileItemFactory factory = new DiskFileItemFactory();
ServletFileUpload upload = new ServletFileUpload(factory);
upload.setFileSizeMax(1024 * 1024 * 30); // 限制上传文件大小为30MB
fileItems = upload.parseRequest(getRequest());
for (FileItem fileItem : fileItems) {
if (!fileItem.isFormField()) {
// 处理文件上传
String fileName = fileItem.getName();
InputStream is = fileItem.getInputStream();
String savePath = "/path/to/save/" + fileName;
// 将文件写入服务器
File uploadedFile = new File(savePath);
if (!uploadedFile.exists()) {
uploadedFile.createNewFile();
}
FileOutputStream fos = new FileOutputStream(uploadedFile);
IOUtils.copy(is, fos);
fos.close();
is.close();
}
}
}
return SUCCESS;
}
}
在实际应用中,文件上传功能需要考虑许多细节问题,例如文件大小的限制、文件类型的校验、上传失败的处理等。在配置文件上传拦截器时,这些都可以通过配置相关属性来实现。
<struts>
<package name="default" extends="struts-default">
<action name="uploadAction" class="com.example.UploadAction">
<interceptor-ref name="defaultStack"/>
<interceptor-ref name="fileUpload">
<param name="maximumSize">31457280</param>
</interceptor-ref>
<result name="success">/upload_success.jsp</result>
</action>
</package>
</struts>
在这段配置中,我们定义了 uploadAction 动作,并引用了默认的拦截器栈以及 fileUpload 拦截器。我们还通过 <param> 标签设置了上传文件的最大大小为30MB。
通过本章节的介绍,我们可以看到Struts 2框架的高级特性为开发者提供了强大的工具来简化开发流程、增强应用功能。在实际项目中,合理利用这些特性可以极大地提高开发效率和应用质量。
5. Hibernate框架基础与会话管理
5.1 Hibernate框架的基础
5.1.1 Hibernate的基本概念和原理
Hibernate是一个强大的、可伸缩的、透明的、跨平台的持久层解决方案,它为数据库编程提供了一个全新的视角。Hibernate不仅对传统的JDBC进行了抽象,还提供了一套对象关系映射(ORM)框架。Hibernate的主要任务是将Java对象映射到数据库表中,以及将数据库表映射到Java对象。它将对象的持久化逻辑从业务逻辑中分离出来,使开发人员可以专注于业务逻辑的实现。
Hibernate通过配置文件或注解的方式定义对象到数据库表的映射关系,并通过HQL(Hibernate Query Language)或Criteria API等查询接口来进行数据的查询和操作。与传统JDBC相比,Hibernate极大地简化了数据持久化操作,减少了代码量,提高了开发效率。
5.1.2 Hibernate的基本操作和应用
Hibernate的基本操作包括对象的保存、更新、删除和查询。这些操作都是通过Hibernate的Session对象来实现的,Session是应用程序与Hibernate之间的交互的主要接口。使用Hibernate时,首先需要配置并启动Hibernate环境,然后打开一个Session来进行数据操作。
实例代码:
// 获取Session工厂
Configuration config = new Configuration().configure();
SessionFactory sessionFactory = config.buildSessionFactory();
Session session = sessionFactory.openSession();
// 开启事务
Transaction tx = session.beginTransaction();
// 对象的保存
User user = new User("username", "password");
session.save(user);
// 对象的更新
user.setPassword("newPassword");
session.update(user);
// 对象的删除
session.delete(user);
// 对象的查询
Criteria criteria = session.createCriteria(User.class);
criteria.add(Restrictions.eq("username", "username"));
User foundUser = (User) criteria.uniqueResult();
// 提交事务
tx.commit();
// 关闭Session
session.close();
参数说明:
-
sessionFactory:代表Hibernate的会话工厂,用于创建会话。 -
session:表示与数据库的会话,所有的CRUD操作都在这个会话中进行。 -
Transaction:代表一个事务,是事务控制的封装。
5.1.3 Hibernate的基本配置
Hibernate的配置一般通过XML文件来实现,该文件定义了数据库连接参数、数据方言、映射文件等信息。配置文件通常命名为 hibernate.cfg.xml ,位于项目的 src 目录下。
配置示例:
<!DOCTYPE hibernate-configuration PUBLIC
"-//Hibernate/Hibernate Configuration DTD 3.0//EN"
"http://www.hibernate.org/dtd/hibernate-configuration-3.0.dtd">
<hibernate-configuration>
<session-factory>
<!-- 数据库连接信息 -->
<property name="connection.driver_class">com.mysql.jdbc.Driver</property>
<property name="connection.url">jdbc:mysql://localhost:3306/testdb</property>
<property name="connection.username">root</property>
<property name="connection.password">123456</property>
<!-- 数据库方言 -->
<property name="dialect">org.hibernate.dialect.MySQLDialect</property>
<!-- 输出SQL语句 -->
<property name="show_sql">true</property>
<!-- 格式化输出SQL -->
<property name="format_sql">true</property>
<!-- 自动创建表结构 -->
<property name="hbm2ddl.auto">create-drop</property>
<!-- 加载映射文件 -->
<mapping resource="User.hbm.xml"/>
</session-factory>
</hibernate-configuration>
参数说明:
-
connection.driver_class:数据库驱动类。 -
connection.url:数据库连接URL。 -
connection.username:数据库连接用户名。 -
connection.password:数据库连接密码。 -
dialect:指定数据库方言,用于生成SQL语句。 -
show_sql:是否输出SQL语句到控制台。 -
format_sql:是否格式化SQL语句。 -
hbm2ddl.auto:数据库结构自动更新策略。 -
mapping:映射文件的位置。
5.2 Hibernate的会话管理
5.2.1 会话的创建和管理
在Hibernate中, Session 是与数据库交互的接口,也是事务的范围。一个 Session 代表一个数据库连接。在应用程序中,我们需要手动管理Session的生命周期。通常,在请求处理或任务执行完成后,应该关闭Session以释放数据库连接。
Session管理规则:
- 通常,Session与请求或任务的生命周期一致。
- 尽量保持Session的打开时间最短,以避免潜在的资源泄露。
- 可以通过ThreadLocal变量来管理当前线程的Session,确保一个线程在任何时候只有一个Session实例。
代码示例:
// 使用ThreadLocal存储当前线程的Session实例
ThreadLocal<Session> threadLocal = new ThreadLocal<Session>();
// 获取当前线程的Session实例
Session session = threadLocal.get();
if (session == null) {
session = sessionFactory.openSession();
threadLocal.set(session);
}
// 执行业务逻辑...
// 任务完成后关闭Session
if (session != null) {
session.close();
threadLocal.remove();
}
5.2.2 会话的高级应用和优化
在实际应用中,仅仅知道如何创建和关闭Session是不够的。Hibernate提供了许多高级特性来进一步优化Session的使用,例如Session的懒加载和缓存管理。
懒加载(Lazy Loading):
懒加载是一种常见的性能优化手段,它允许对象在被访问时才进行加载,而不是在一开始就把关联对象加载进来。Hibernate支持懒加载关联关系,例如一对多、多对一、多对多等。
// 定义一对多的懒加载关系
@Entity
public class User {
@OneToMany(mappedBy="user", fetch=FetchType.LAZY)
private Set<Order> orders;
}
// 查询User对象时,它的订单信息默认不会被加载,而是在访问orders属性时才会触发加载。
缓存管理:
Hibernate内置了两个级别的缓存:Session级别的缓存(第一级缓存)和SessionFactory级别的缓存(第二级缓存)。第一级缓存与Session生命周期一致,而第二级缓存可以跨多个Session共享数据。
// 配置第二级缓存
<property name="cache.use_second_level_cache">true</property>
<property name="cache.region.factory_class">org.hibernate.cache.ehcache.EhCacheRegionFactory</property>
通过合理配置和使用Hibernate的高级特性,可以显著提高应用程序的性能和可维护性。但需要注意的是,这些特性也需要在适当的场景下使用,以避免过度设计和资源的浪费。
6. Hibernate映射机制与关系映射
6.1 Hibernate的映射机制
映射的基本原理和实现
Hibernate的映射机制是连接Java对象和关系数据库表的桥梁。通过配置文件或注解的方式,开发者可以声明对象和数据库表之间的映射关系。映射文件通常以 .hbm.xml 为扩展名,位于项目的资源文件夹中。在映射文件中,开发者可以指定类映射到的数据库表,以及类属性和表字段之间的对应关系。
例如,假设我们有一个 User 实体类,映射到数据库中的 users 表。在 User.hbm.xml 映射文件中,我们会这样配置:
<class name="User" table="users">
<id name="id" column="user_id">
<generator class="native"/>
</id>
<property name="name" column="user_name"/>
<property name="password" column="user_password"/>
<!-- 其他属性映射 -->
</class>
以上配置说明了 User 类的 id 属性对应数据库中的 user_id 字段,并使用数据库的自增长策略来生成主键。 name 和 password 属性则分别对应 user_name 和 user_password 字段。
映射的优化和实践应用
为了提高性能,通常需要对映射关系进行优化。例如,使用懒加载( lazy="true" )来延迟加载关联对象,只在真正访问时才加载它们。另外,对于一对多或多对一关系的映射,可以使用 <set> 或 <many-to-one> 标签来定义集合和关系,这样可以减少数据库查询的次数,提高效率。
在实际应用中,优化映射关系还包括合理利用Hibernate的 <cache> 配置来控制对象的缓存策略,减少数据库的压力,并提升数据访问速度。
6.2 Hibernate的关系映射
关系映射的基本原理和实现
在数据模型中,实体之间往往存在着多种关系,如一对多、多对一、一对一和多对多等。Hibernate提供了丰富的机制来实现这些关系映射。
以一对多关系为例,假设我们有一个 Department 部门类,其中包含多个 User 员工。在 Department.hbm.xml 映射文件中,我们可以这样配置:
<class name="Department" table="departments">
<id name="id" column="department_id">
<generator class="native"/>
</id>
<!-- 其他属性映射 -->
<set name="users" cascade="save-update" inverse="true">
<key column="department_id"/>
<one-to-many class="User"/>
</set>
</class>
这段配置表明, Department 类中有一个名为 users 的 Set 集合,它包含多个 User 实例。通过 <one-to-many> 标签,Hibernate知道一个部门可以有多个用户。 cascade="save-update" 属性表示对父实体的操作会级联到子实体,而 inverse="true" 表示关系的维护责任在对方(即User实体)。
关系映射的优化和实践应用
关系映射是提高应用性能的重要因素。例如,在处理一对多关系时,可以通过 batch-size 属性对集合进行批量抓取,以减少对数据库的访问次数。同时,对于频繁查询的关系,使用 fetch="join" 可以提前加载关联数据,减少N+1查询问题。
在多对多关系映射中,通常需要一个中间表来维护两个实体之间的关系。Hibernate允许通过 <many-to-many> 标签配置这种关系,并可以指定中间表和相关字段。
此外,还应该注意在事务提交前处理所有关系映射,避免在事务中出现缓存和持久化上下文的不一致问题。合理配置关系映射,不仅能够提升应用的性能,还能保证数据的一致性和完整性。
7. Hibernate数据操作与事务管理
Hibernate是一个强大的ORM(对象关系映射)框架,用于在Java应用程序和数据库之间建立一个桥梁。它简化了数据持久化的操作,提供了一个抽象层,让开发者可以以面向对象的方式操作数据库。在本章节中,我们将深入探讨Hibernate的数据操作和事务管理,并介绍如何优化这些操作以提高应用性能。
7.1 Hibernate的数据操作
数据操作是应用程序的核心部分,涉及到对数据库的CRUD(创建、读取、更新、删除)操作。Hibernate为这些操作提供了全面的支持,并通过它的Session接口来执行数据操作。
7.1.1 数据的CRUD操作和实现
在Hibernate中,通过Session接口,我们可以执行所有的数据操作。Session对象代表了一个与数据库连接的线程,并且它是不可重用的。下面是一个简单的数据操作示例:
Session session = sessionFactory.openSession();
Transaction transaction = null;
try {
transaction = session.beginTransaction();
User user = new User("John Doe", 30);
session.save(user); // Create
user.setAge(31);
session.update(user); // Update
session.delete(user); // Delete
transaction.commit();
} catch (Exception e) {
if (transaction != null) {
transaction.rollback();
}
e.printStackTrace();
} finally {
session.close();
}
在这段代码中,首先创建了一个Session对象,然后启动了一个事务。接着,我们创建了一个 User 对象并保存它到数据库(创建操作),然后更新了用户信息(更新操作),最后删除了该用户(删除操作)。整个过程在事务的控制之下,确保了操作的原子性。
7.1.2 数据操作的优化和实践应用
在实际应用中,为了提高数据操作的效率,我们通常会采取一些优化措施:
- 使用批量操作来减少数据库的交互次数。
- 通过合理的缓存策略,如二级缓存,减少数据库的访问频率。
- 在数据操作中合理使用Hibernate的懒加载特性。
下面是一个使用批量插入的示例:
Session session = sessionFactory.openSession();
Transaction transaction = session.beginTransaction();
for (User user : usersList) {
session.save(user);
}
transaction.commit();
session.close();
在这个例子中,我们通过一个循环批量插入了多个用户数据,相比于单条插入,这样的操作可以显著提升性能。
7.2 Hibernate的事务管理
事务管理是保证数据库操作一致性和完整性的关键,Hibernate提供了对事务管理的支持,并允许开发者控制事务的边界。
7.2.1 事务的基本原理和实现
Hibernate的事务由 Transaction 接口表示,可以通过调用 Session 对象的 beginTransaction() 方法来启动一个新的事务。之后,所有的数据操作都将在这个事务的上下文中执行。完成所有操作后,需要调用 commit() 来提交事务,或者在发生异常时调用 rollback() 来回滚事务。
7.2.2 事务的高级应用和优化
在高级应用中,我们可以通过编程方式控制事务,也可以依赖Hibernate提供的声明式事务管理。此外,还可以通过 @Transactional 注解来声明事务边界,这是在Spring框架中管理Hibernate事务的常见方式。
@Transactional
public void updateUserStatus(Integer userId, String status) {
User user = session.get(User.class, userId);
user.setStatus(status);
}
通过使用 @Transactional 注解,开发者可以更加专注于业务逻辑,而不需要显式地管理事务的开启和提交。
综上所述,Hibernate为数据操作和事务管理提供了强大的支持,通过合理的使用和优化,可以大幅度提升应用程序的性能和稳定性。在下一章节,我们将深入探讨Spring框架的核心概念和依赖注入,进一步了解如何利用这些技术提高Java应用的开发效率。
简介:本书为Java企业级开发者提供了全面的教程,涉及Struts 2、Hibernate和Spring等核心框架。郑阿奇教授编写的第二版深入浅出地介绍了这些技术的关键概念和高级应用。电子教案以PPT形式呈现,帮助教师和学生更好地消化和理解教材内容。从自定义标签、数据校验到国际化和异常处理,再到ORM框架和Spring整合,本书为读者提供了一个实用的企业级JavaEE开发学习路径。

















 2060
2060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









