








 HBase是一种高可靠性、高性能、面向列的分布式存储数据库,运行于HDFS之上,使用Zookeeper作为协调工具。本文对比了HBase与关系型数据库在数据类型、操作、存储模式、索引、维护和扩展方面的区别,并介绍了HBase的访问接口、数据模型和功能组件。
HBase是一种高可靠性、高性能、面向列的分布式存储数据库,运行于HDFS之上,使用Zookeeper作为协调工具。本文对比了HBase与关系型数据库在数据类型、操作、存储模式、索引、维护和扩展方面的区别,并介绍了HBase的访问接口、数据模型和功能组件。
hbase:高可靠型、高性能、面向列、可伸缩的分布式存储数据库,
hbase运行于hdfs之上,使用zookeeper作为协调工具。
与关系型数据库对比:
1.数据类型方面
关系型数据库有很多数据类型(int,char等),hbase只有字符串。
2.数据操作方面
关系型数据库定义了非常多的操作。
如表间的连接操作,关系型数据库效率很低;而hbase存在一张表中不需要连接,提升了效率。
3.存储模式方面
关系数据库基于行存储,hbase基于列存储。
如果企业事务型操作比较多,按行存储比较好,因为经常要插入一条条数据;
如何企业以分析型为主,那么按列存储比较好。
比如分析超市购物表的年龄分布,按行存储的表要扫描所有的行,再拿到年龄列的值;
而按列存储的表直接拿出年龄那一列即可。
4.数据索引方面
关系数据库可以构建很多索引,行索引、列索引,精准定位。
hbase在原始设计上只支持对行的简单索引。
5.数据维护方面
更新数据时,关系型数据库旧值会被新值覆盖,hbase都会保留着。
6.扩展方面
关系型数据库很难水平扩展;最多提升机器性能(增加磁盘等)来纵向扩展。
hbase基于集群、hdfs,水平扩展性能非常好。
hbase访问接口:
1.java接口:最常规和高效的方式,适合mapreduce批处理表数据
2.shell接口:命令行工具,最简单的接口
3.sql接口:hive的类sql语言、pig的Latin流式编程语言
4.其他:Thrift Gateway、REST Gateway等
hbase数据模型:
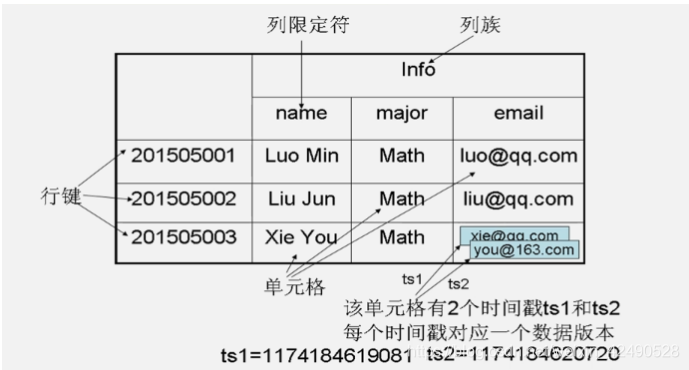
行键RowKey(行)、列限定符Column(列)、列族Column Family
(列族是hbase存储的基本单元,包含多个列)
单元格内的值都是字符串类型,需要我们自己解析(如解析成整形)
时间戳Timestamp(64位整数,标识新旧版本的)
通过行键、列族、列、时间戳四个维度来定位数据。
逻辑数据模型:
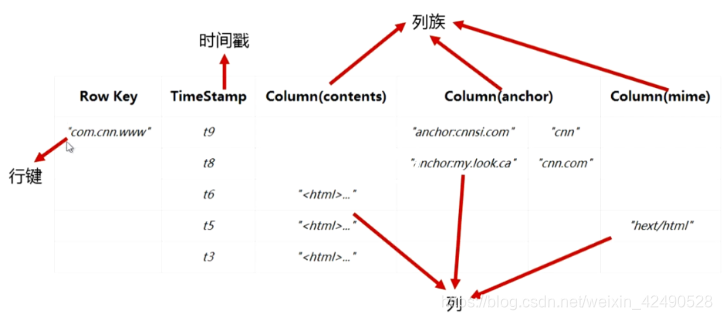
物理模型:

hbase功能组件:
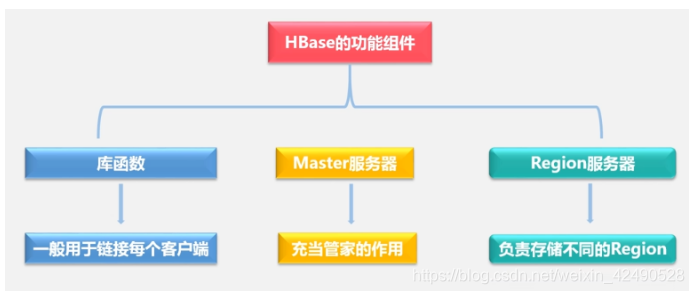
库函数:用于链接客户端,客户端通过库函数访问hbase数据库
Master服务器:管理Region服务器
1.对分区信息进行维护和管理
2.Master中有region服务器列表,可以看到有哪些region服务器在工作,哪些故障。
3.负责对region进行分配
如一个表进行分区,分成多个region,每个region分到哪个region服务器
4.负责负责均衡
比如有一个region服务器负载很重,另一个很轻,把他们均衡一下
Region服务器:负责存储表的每个不同region
表和region:
表越来越大就需要分区,分成多个region
region大小最佳为1G到2G,取决于机器性能
对于同一个region,它是绝不会比拆分到不同的region服务器上去的。
表region的定位:
通过三层架构来寻址:zookeeper文件、ROOT表、META表
zookeeper记录ROOT表的位置信息;(ROOT表只有一个分区)
ROOT表记录了META表的相关region信息;(META表是分区的,有多个分区)
META表记录了用户数据表的region信息;(我们自己的表也是分区的,有多个分区)
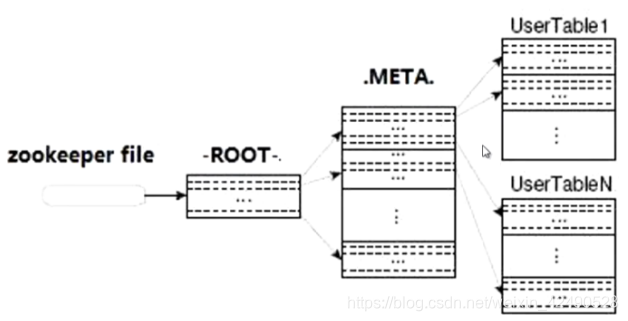
hbase运行机制:
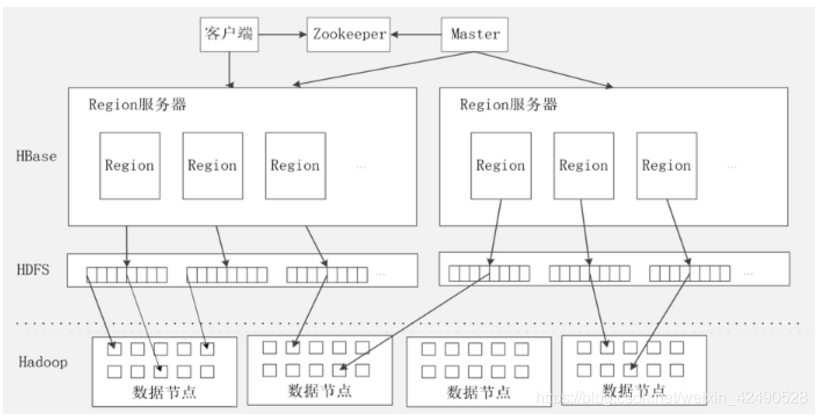
客户端:访问hbase,直接跟region服务器打交道
客户端缓存着已访问过的regin服务器地址,方便下次访问,cache。
region服务器:我们的表很大,会分区,region服务器存放表的分区region
master服务器:管理region服务器
master可以启动多个HMaster,通过zookeeper的选举机制只运行一个。
zookeeper服务器:协同管理
zookeeper在hbase中提供管家的功能,维护和管理整个hbase集群,
zookeeper存储ROOT表来定位region;
zookeeper保证只有一个master运行hmaster,监视HLog,出现故障通知master。
region服务器(详细):
一个region服务器中存放多个region,每个region又会存放多个列族store,
(hbase存储数据以列族为单位,按列族切分,每个列族构成一个store)
列族store中的数据先写入缓存MemStore,缓存满了再写入磁盘StoreFile,
StoreFile是hbase的表示形式,借助Hdfs来存储,也就是hdfs文件HFile。
所有region公用一个日志HLog,zookeeper监视它。

















 1239
1239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









