







 本文介绍如何使用spark-submit命令在本地和YARN集群上执行WordCount程序。详细解释了spark-submit的常用参数,如--master、--driver-memory、--executor-memory和--executor-cores,并演示了如何在不同环境下运行WordCount.py文件。
本文介绍如何使用spark-submit命令在本地和YARN集群上执行WordCount程序。详细解释了spark-submit的常用参数,如--master、--driver-memory、--executor-memory和--executor-cores,并演示了如何在不同环境下运行WordCount.py文件。
将 wordcount.py 文件使用 spark-submit 来执行
1. 本地执行
2. yarn执行
wordcount.py 文件见下一节【 wordcount(pycharm)】
spark-submit 常用参数:
--master yarn-client spark运行环境
--driver-memory 1G driver程序使用的内存
--executor-memory 6G Executor线程的内存
--executor-cores 4 每个Executor线程的CPU core数量
关于master url的指定方法:
local 本地worker线程中运行spark,完全没有并行
local[K] 在本地work线程中启动K个线程运行spark
local[*] 启动与本地work机器的core个数想通的线程数来运行spark
yarn 使用yarn的cluster或者yarn的client模式连接。
--master yarn-client 相当于--master yarn --deploy-mode client
spark://HOST:PORT 连接指定的standalone集群的master,默认7077端口
测试文本:data.txt
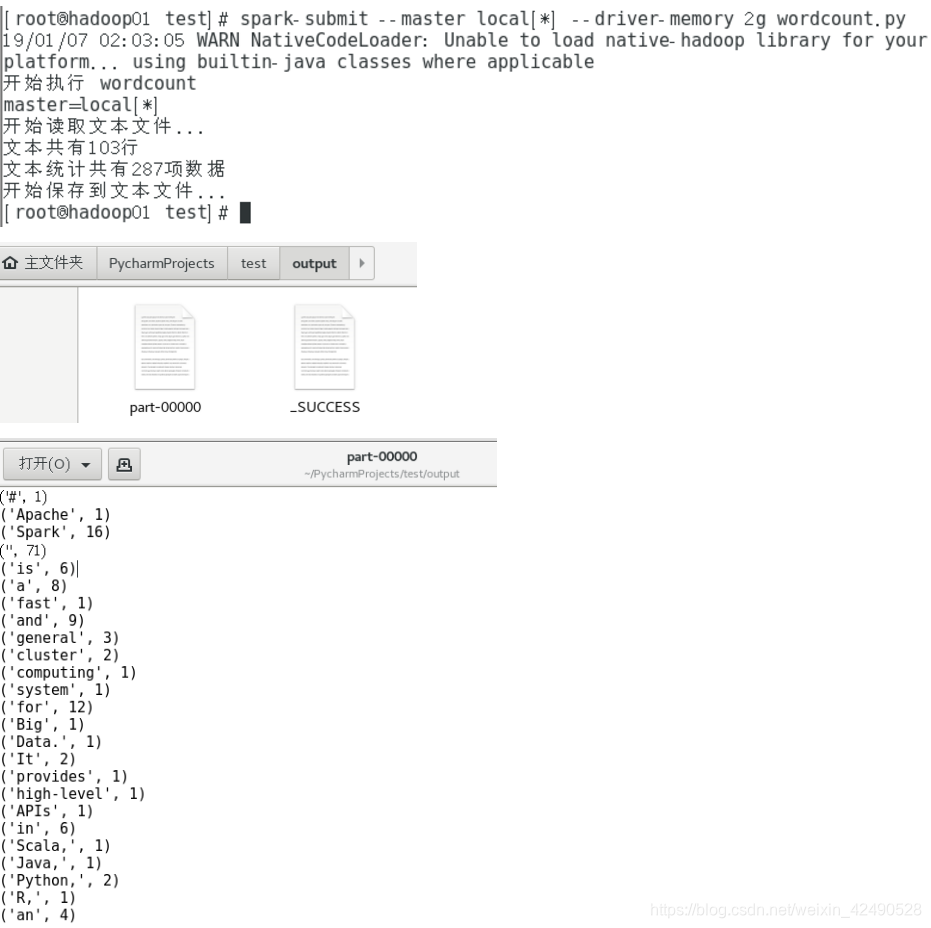
1. local 执行 spark-submit
可以直接:spark-submit wordcount.py
多加几个参数:spark-submit --master local[*] --driver-memory 2g wordcount.py
结果:
2. yarn 执行
spark-submit --master yarn-client wordcount.py
结果:
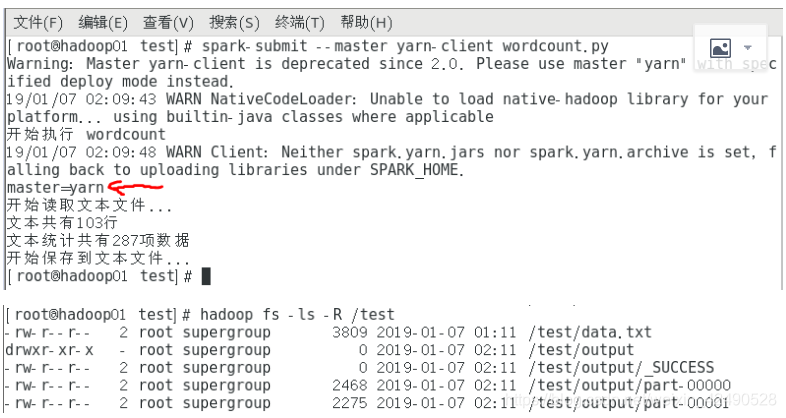
hadoop fs -ls -R 递归查看目录,spark还把结果分成了2份。
删除hdfs目录:hadoop fs -rm -R /test/output
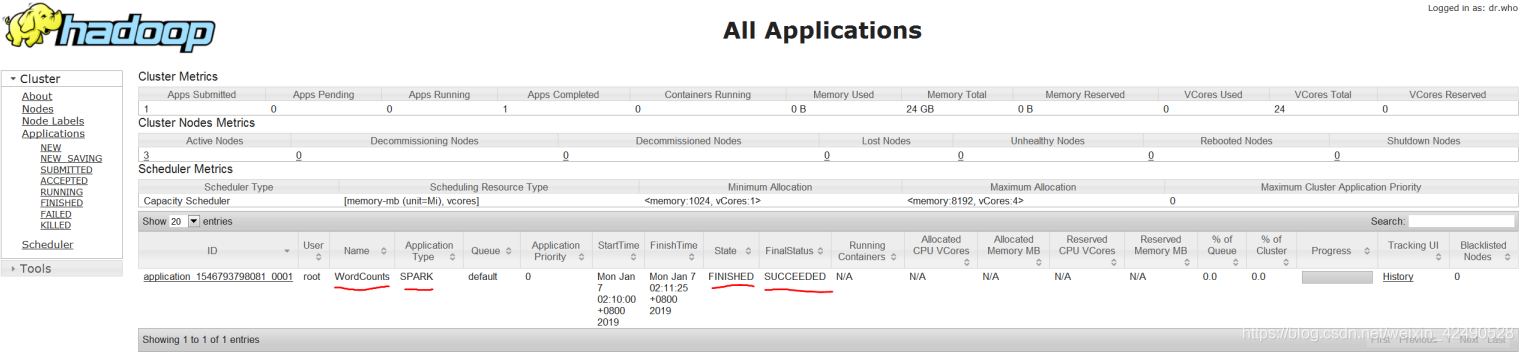
yarn web:192.168.80.139:8088

















 4333
4333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









