






 本文详细介绍Hadoop高可用架构的部署过程,包括环境规划、配置修改、分发配置文件、搭建Zookeeper集群、启动JournalNode及NameNode等关键步骤,并解决配置中常见错误。
本文详细介绍Hadoop高可用架构的部署过程,包括环境规划、配置修改、分发配置文件、搭建Zookeeper集群、启动JournalNode及NameNode等关键步骤,并解决配置中常见错误。
参考文章:https://blog.youkuaiyun.com/weixin_42782897/article/details/89335674



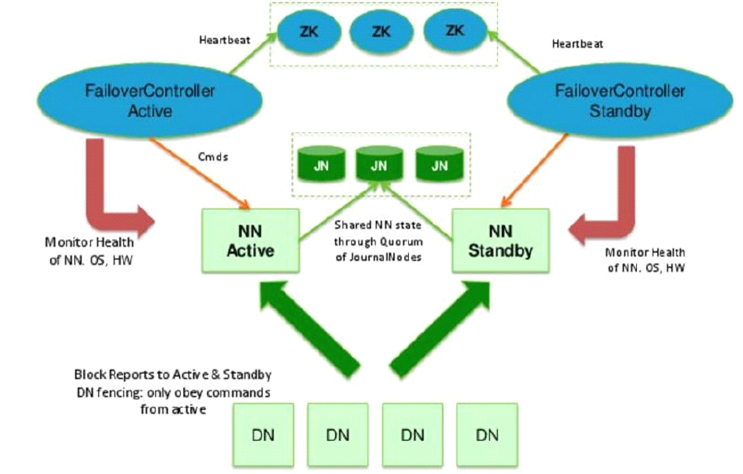
Hadoop高可用架构图

环境规划
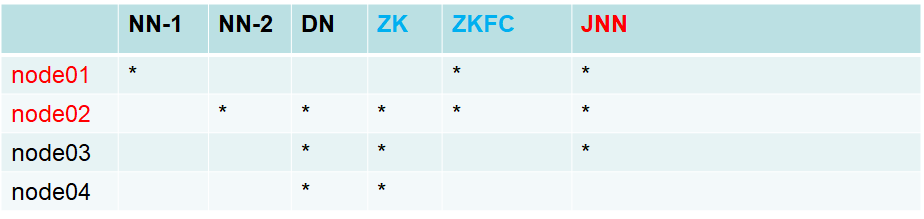
演示环境规划
在node01修改hdfs-site.xml配置
<configuration>
<!-- 配置block副本数-->
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- 逻辑上的NameNodes服务的名称-->
<property>
<name>dfs.nameservices</name>
<value>zhhcluster</value>
</property>
<!-- 逻辑上每个NameNode的唯一标识符,2.X每个名称服务最多只能配置两个NameNode。-->
<property>
<name>dfs.ha.namenodes.zhhcluster</name>
<value>zhh_nn1,zhh_nn2</value>
</property>
<!-- 侦听的每个NameNode的完全限定的RPC地址-->
<property>
<name>dfs.namenode.rpc-address.zhhcluster.zhh_nn1</name>
<value>node01:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.zhhcluster.zhh_nn2</name>
<value>node02:8020</value>
</property>
<!-- 侦听的每个NameNode的完全限定的http地址-->
<property>
<name>dfs.namenode.http-address.zhhcluster.zhh_nn1</name>
<value>node01:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.zhhcluster.zhh_nn2</name>
<value>node02:50070</value>
</property>
<!-- 标识NameNodes将写入/读取编辑的JN组的URI-->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node01:8485;node02:8485;node03:8485/zhhcluster</value>
</property>
<!-- HDFS客户端用于联系Active NameNode的Java类-->
<property>
<name>dfs.client.failover.proxy.provider.zhhcluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- JournalNode本地存储绝对路径-->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/ha/jn</value>
</property>
<!-- 配置Quorum Journal Manager防护方法 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!-- 自动切换主备 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
在node01修改core-site.xml配置
<configuration>
<!-- 配置NN位置-->
<property>
<name>fs.defaultFS</name>
<value>hdfs://zhhcluster</value>
</property>
<!-- 配置数据存储的base目录-->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/ha</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
</configuration>
分发node01的hdfs-site.xml和core-site.xml到其他机器
前提是已经完成了前面几节,其他机器已经有hadoop了
cd $HADOOP_PREFIX/etc/hadoop
scp hdfs-site.xml core-site.xml node02:`pwd`
scp hdfs-site.xml core-site.xml node03:`pwd`
scp hdfs-site.xml core-site.xml node04:`pwd`
在node02开启对其他三台机器免秘钥
参考前面分布式搭建章节
在node02,node03,node04搭建zookeeper集群
- 复制zoo_sample.conf,命名为zoo.conf,作如下配置
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/var/zk
clientPort=2181
server.1=192.168.80.12:2888:3888 -
server.2=192.168.80.13:2888:3888
server.3=192.168.80.14:2888:3888
- 往dataDir目录写入一个myid文件,跟配置文件的序号对应1,2,3
echo 1 > /var/zk/myid
- 启动zookeeper集群
zkServer.sh start || zkServer.sh status
在node01,node02,node03启动journalNode
[root@node01 ~]# hadoop-daemon.sh start journalnode
starting journalnode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-journalnode-node01.out
[root@node01 ~]# jps
21238 JournalNode
21289 Jps
在node01格式化nameNode
hdfs namenode –format
单独启动node01的nameNode
hadoop-deamon.sh start namenode
standby机器node02的nameNode
hdfs namenode -bootstrapStandby
格式化zkfc
hdfs zkfc -formatZK
启动start-hdfs.sh
[root@node01 ~]# start-dfs.sh
Starting namenodes on [node01 node02]
node01: starting namenode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-namenode-node01.out
node02: starting namenode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-namenode-node02.out
node04: starting datanode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-datanode-node04.out
node03: starting datanode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-datanode-node03.out
node02: starting datanode, logging to /opt/hadoop-2.9.2/logs/hadoop-root-datanode-node02.out
Starting journal nodes [node01 node02 node03]
node03: journalnode running as process 8526. Stop it first.
node01: journalnode running as process 21238. Stop it first.
node02: journalnode running as process 9295. Stop it first.
Starting ZK Failover Controllers on NN hosts [node01 node02]
node02: starting zkfc, logging to /opt/hadoop-2.9.2/logs/hadoop-root-zkfc-node02.out
node01: starting zkfc, logging to /opt/hadoop-2.9.2/logs/hadoop-root-zkfc-node01.out
遇到的问题
- 配置dfs.journalnode.edits.dir时<value>多了一个'>',导致启动JN时,用jps看不到启动后的进程,实际是启动失败了,可以到logs目录查看报错


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









