




2019-CVPR-Graph Convolutional Label Noise Cleaner: Train a Plug-and-play Action Classifier for Anomaly Detection
图卷积标签噪声清洁器:训练即插即用的动作分类器
摘要
在以往的工作中,弱标签下的视频异常检测被表述为一个典型的多实例学习问题。在本文中,我们提供了一个新的视角,即噪声标签下的监督学习任务。在这样的观点下,只要清除标签噪声,我们就可以直接将完全监督的动作分类器应用于弱监督的异常检测,并最大限度地利用这些成熟的分类器。为此,我们设计了一个图卷积网络来纠正噪声标签。基于特征相似性和时间一致性,我们的网络将监督信号从高置信度片段传播到低置信度片段。以这种方式,网络能够为动作分类器提供干净的监督。在测试阶段,我们只需要从动作分类器中获得片段预测,无需任何额外的后处理。使用 2 种类型的动作分类器对 3 个不同规模的数据集进行的大量实验证明了我们方法的有效性。值得注意的是,我们在 UCF-Crime 上获得了 82.12% 的帧级 AUC 分数。
1. 引言
长期以来,人们一直在研究视频中的异常检测,因为它在现实场景中无处不在,例如智能监控、暴力警报、证据调查等。由于异常事件在常见环境中很少出现,因此异常通常被定义为与以往工作模式不同的行为或外观模式 [6、1、13]。基于这个定义,一种流行的异常检测范例是单类分类 [66、11](也称为一元分类),即仅使用正常训练样本对通常模式进行编码。然后将独特的编码模式检测为异常。但是,不可能在数据集中收集所有正常行为。因此,一些正常事件可能会偏离编码模式,并可能导致误报。近年来,对新兴的二元分类范式进行了一些研究 [20、22、58]:训练数据包含异常视频和正常视频。
遵循二元分类范式,我们试图解决弱监督异常检测问题,在该问题上,训练数据中只有视频级异常标签可用。在这个问题中,考虑到人力成本,既没有修剪异常片段也没有时间注释。
弱监督异常检测问题在之前的工作中被视为多实例学习(MIL)任务 [20、22、58]。他们将一段视频(或一组片段)视为一个包,其中包含被视为实例的片段(或帧),并通过包级注释学习实例级异常标签。在本文中,我们从一个新的角度解决了这个问题,将其表述为噪声标签下的监督学习任务。噪声标签是指异常视频中正常片段的错误注释,因为标记为 “异常” 的视频可能包含相当多的正常片段。在这样的观点下,一旦噪声标签被清除,我们就可以直接训练完全监督的动作分类器。
我们的噪声标记视角在训练和测试阶段都有明显的优势。我们的动作分类器参与了整个学习过程,而不是简单地为 MIL 模型提取离线特征。在训练过程中,动作分类器和完全监督更新之间的唯一区别是输入标签。因此,我们保留了这些动作分类器的所有优点,例如精心设计的结构、可迁移的预训练权重、即用型源代码等。至于测试,训练有素的分类器可以直接进行预测,无需任何后期加工。由于特征提取和异常判定无缝集成到单个模型中,因此非常方便且高效。
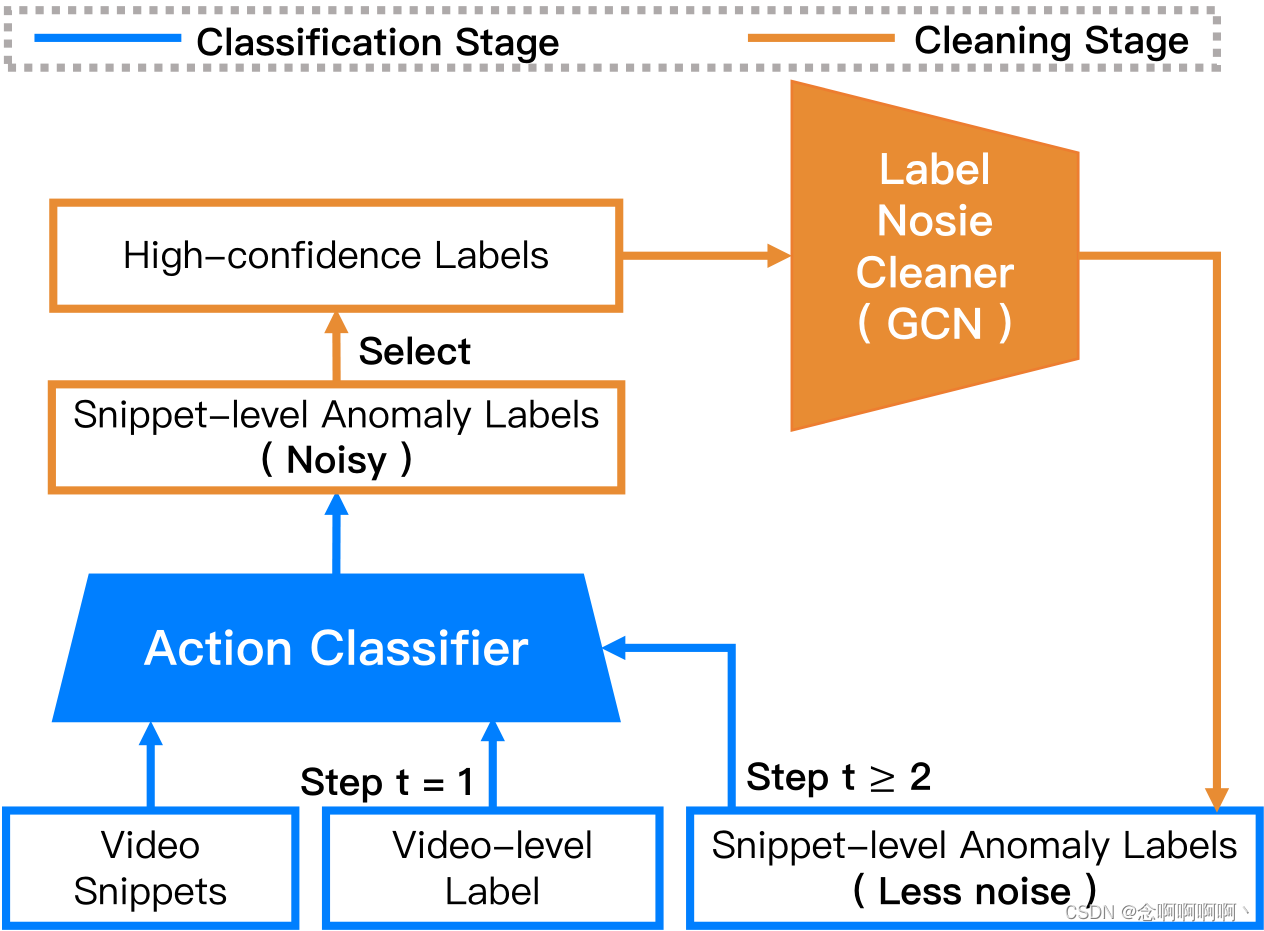
直观地说,训练有素的分类器会产生噪声较少的预测,而清洁后的标签反过来有助于训练更好的分类器。为此,我们设计了另一种训练程序,如图 1 所示。它由两个交替阶段组成,即清洁和分类。在清洁阶段,我们训练清洁器来纠正从分类器获得的噪声预测,清洁器提供噪声更少的精细标签。在分类阶段,动作分类器使用清理过的标签进行再训练,并生成更可靠的预测。如此循环操作多次,直至收敛。我们清洁器的主要思想是通过高置信度预测消除低置信度预测的噪声。我们设计了一个图卷积网络(GCN)来建立高置信度片段和低置信度片段之间的关系。在图中,片段被抽象为顶点,异常信息通过边传播。在测试期间,我们不再需要清洁器并直接从训练有素的分类器中获取片段异常结果。为了验证我们模型的普遍适用性,我们对两种主流动作分类器进行了广泛的实验:3D-conv 网络 C3D [59] 和双流结构 TSN [62]。此外,我们在 3 个不同规模的数据集上评估了所提出的方法,即 UCF-Crime [58]、ShanghaiTech [43] 和 UCSD-Peds [35]。实验结果表明,我们的模型提高了弱监督异常检测的最新性能。
简而言之,本文的贡献有三个方面:
- 我们将弱标签异常检测问题制定为噪声标注下的监督学习任务,并提出了替代训练框架来优化动作分类器。
- 我们提出了一个 GCN 来清理噪声标签。据我们所知,这是第一项在视频分析领域应用 GCN 来校正标签噪声的工作。
- 我们使用两种类型的动作分类器对 3 个不同规模的异常检测数据集进行了实验,其中最先进的性能验证了我们方法的有效性。源代码可在 https://github.com/jx-zhong-for-academicpurpose/GCN-Anomaly-Detection 获得。
2. 相关工作
Anomaly detection。作为最具挑战性的问题之一,视频中的异常检测已被广泛研究多年 [30、67、65、19、34、3、47、35]。大多数研究都是在异常罕见或看不见的假设下解决这个问题,并且偏离正常模式的行为应该是异常的。他们试图通过各种统计模型对规则模式进行编码,例如社会力模型 [45],纹理上动态模型的混合 [35],视频卷上的隐马尔可夫模型 [21、30],时空域上的马尔可夫随机场 [28],高斯过程建模 [49、11],并将异常识别为异常值。稀疏重建 [41、31、13、67] 也是通常模式建模的另一种流行方法。他们利用稀疏表示为正常行为构建字典,并将异常检测为具有高重构误差的异常。最近,随着深度学习的巨大成功,一些研究人员设计了用于异常检测的抽象特征学习 [19、12、42] 或视频预测学习 [40] 的深度神经网络。与仅在正常行为上建立检测模型的工作相反,有研究 [2、20、58] 使用通常和不寻常的数据来建立模型。其中,MIL 用于弱监督设置下的运动模式建模 [20、58]。Sultani 等人 [58] 提出了一种基于 MIL 的分类器来检测异常,其中深度异常排名模型预测异常分数。与他们不同,我们将弱标签的异常检测问题表述为噪声标签下的监督学习,并设计了一种替代训练程序来逐步提高动作分类器的辨别能力。
Action analysis。动作分类是计算机视觉领域中一个长期存在的问题,已经出现了大量的研究工作 [61、59、62、10、26、63]。大多数现代方法都引入了深度架构模型 [10、59、57、62],包括最流行的双流网络 [57]、C3D [59] 及其变体 [62、15、53、10]。到目前为止,基于深度学习的方法已经取得了最先进的性能。除了动作分类,一些研究人员最近还关注时间动作定位 [68、38、69、56、16]。时间动作检测和异常检测的性能指标有很大不同:动作检测旨在找到尽可能多地与地面实况重叠的时间间隔,而异常检测旨在在各种鉴别阈值下具有稳健的帧级性能。在本文中,我们尝试利用强大的动作分类器以简单可行的方式检测异常。
Learning under noisy labels。解决噪声标签问题的研究工作 [33、48、51、17] 一般可分为两类:降噪和损失校正。在降噪的情况下,他们旨在通过显式或隐式地制定噪声模型来纠正噪声标签,例如条件随机场(CRF)[60]、知识图 [37]。后一组的方法被开发用于直接学习标签噪声,利用校正方法进行损失调整。Azadi 等人 [4] 通过对损失函数施加正则化项来主动选择训练特征。与这些一般方法不同,我们的 GCN 适用于视频并利用基于视频的特性。
Graph convolutional neural network。近年来,大量图卷积网络 [50、29、52、36、18] 被提出来处理图结构数据。这些工作的一个重要方向是利用谱图理论 [8、14],它在谱域上分解图信号并定义一系列用于卷积的参数化滤波器。许多研究人员提出了谱卷积的改进,从而提高了节点分类和推荐系统等任务的性能。我们的标签噪声清除器的目标是在高置信度注释的监督下对图形(整个视频)中的节点(视频片段)进行分类。
3. 问题概述
给定一个视频 V = { v i } i = 1 N V=\left\{v_i\right\}_{i=1}^N V={vi}i=1N 和 N N N 个片段,可观察到的标签 Y ∈ { 1 , 0 } Y\in\left\{1,\ 0\right\} Y∈{1, 0} 表示该视频是否包含异常片段。请注意,训练数据中未提供时间注释。异常检测的目标是在异常出现在测试视频中时查明异常的时间位置。
Sabato 和 Tishby [54] 提供了一种理论分析,其中 MIL 任务可以被视为在片面(one-sided)标签噪声下的学习。在一些先前的工作 [20、22、58] 中,弱监督信号下的异常检测被描述为典型的 MIL 问题。因此,我们很自然地将异常检测从 MIL 公式转移到噪声标签设置。
MIL 公式。在这个公式中,每个片段 v i v_i vi 被视为一个实例,其中异常标签 y i y_i yi 不可用。这些片段根据给定的视频级异常标签 Y Y Y 组成正/负包:正包( Y = 1 Y=1 Y=1)至少包含一个异常片段,而负包( Y = 0 Y=0 Y=0)完全由正常片段组成。因此,异常检测被建模为 MIL 下的关键实例检测 [39],以搜索 y i = 1 y_i=1 yi=1 正实例 v i v_i vi。此 MIL 设置允许在包级监督下学习实例级标签,以及一组方法 [20、22、58] 由此而来。
带有噪声标记的学习公式。很明显,标签 Y = 0 Y=0 Y=0 是无噪声的,因为这意味着视频 V V V 中的所有片段 v i v_i vi 都是正常的:
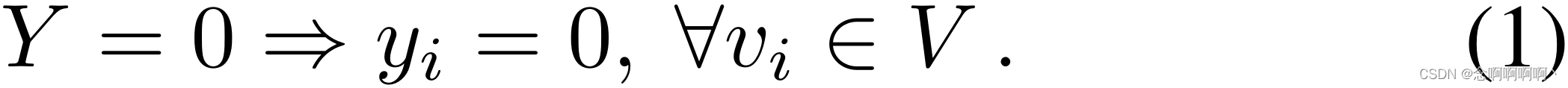
然而, Y = 1 Y=1 Y=1 是有噪声的,因为在这种情况下,视频 V V V 部分由异常片段组成:
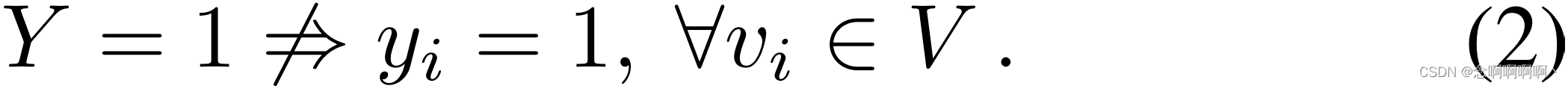
这被称为单侧标签噪声 [7、9、55],因为噪声仅与 Y = 1 Y=1 Y=1 起出现。只要适当地处理标签噪声 w . r . t . Y = 1 w.r.t.\ Y=1 w.r.t. Y=1,我们能够轻松地将各种成熟的动作分类器应用于异常检测。
4. 图卷积标签噪声清洁器
与许多带噪声标签的学习方法类似,我们的方法采用了类似 EM 的优化机制:交替训练动作分类器和噪声清除器。在噪声清除器的每个训练步骤中,我们从动作分类器中获得了粗略的片段异常概率,我们的噪声清除器的目标是通过高置信度异常分数来纠正低置信度异常分数。
与其他一般的噪声标记学习算法不同,我们的清洁器是专门为视频设计的。据我们所知,这是第一个在噪声标记视频中部署 GCN 的工作。在图卷积网络中,我们利用视频的两个特征来校正标签噪声,即特征相似性和时间一致性。直观上,特征相似性意味着异常片段具有一些相似的特征,而时间一致性意味着异常片段可能出现在彼此的时间接近处。
4.1. 特征相似度图模块
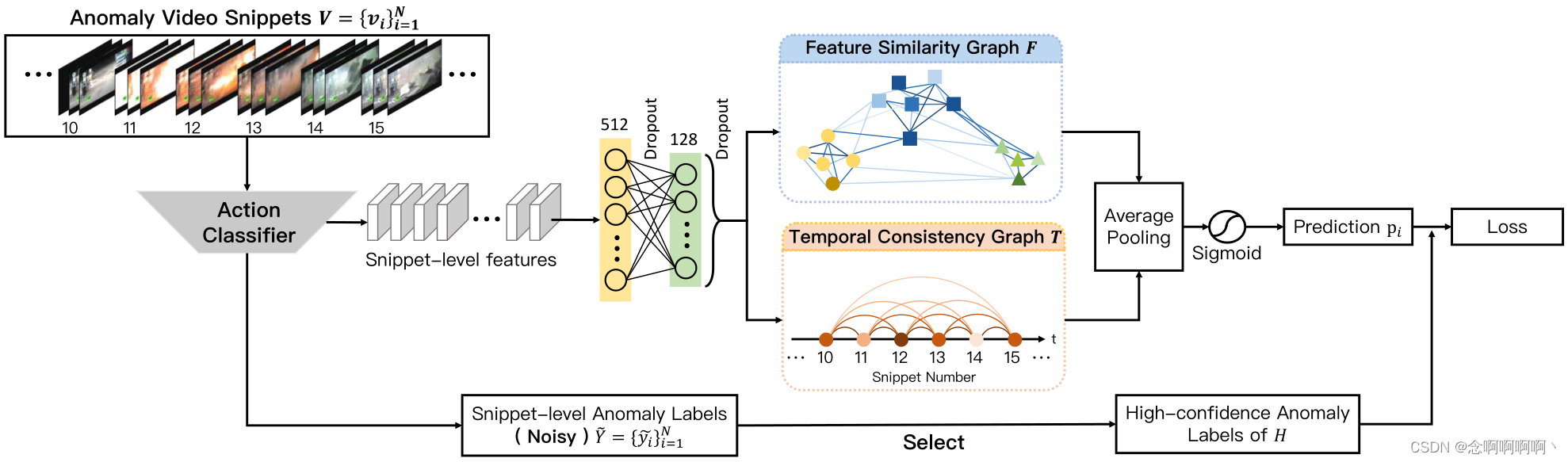
如图 2 所示,来自动作分类器的特征首先用两个完全连接的层进行压缩,以减轻维数灾难 [5]。我们使用属性图(attributed graph)[52]
F
=
(
V
,
E
,
X
)
F=(V,\ E,\ \mathbf{X})
F=(V, E, X) 对特征进行类似建模,其中
V
V
V 是顶点集,
E
E
E 是边集,
X
\mathbf{X}
X 是顶点的属性。特别地,
V
V
V 是第 3 节中定义的视频,
E
E
E 描述了片段之间的特征相似性,
X
∈
R
N
×
d
\mathbf{X}\in\mathbb{R}^{\mathbf{N}\times\mathbf{d}}
X∈RN×d 表示这
N
N
N 个片段的
d
d
d 维特征。
F
F
F 的邻接矩阵
A
F
∈
R
N
×
N
A^F\in\mathbb{R}^{N\times N}
AF∈RN×N 定义为:
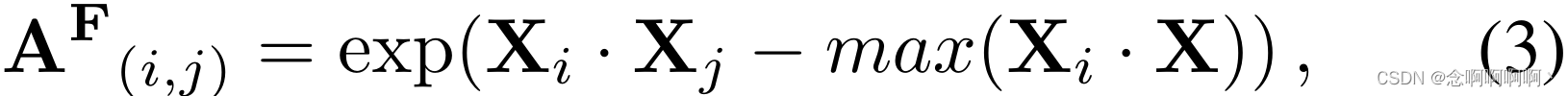
其中元素 A ( i , j ) F \mathbf{A}_{(i,j)}^\mathbf{F} A(i,j)F 在第 i i i 个和第 j j j 个片段之间测量相似的特征。由于邻接矩阵应该是非负的,我们使用归一化指数函数将相似性限制在范围 ( 0 , 1 ] (0,\ 1] (0, 1] 内。基于图 F F F,具有相似特征的片段紧密相连,标签分配根据不同的邻接值进行不同的传播。
通过图-拉普拉斯(graph-Laplacian)运算,使相邻顶点具有相同的异常标签。继 Kipf 和 Welling [29] 之后,我们使用重归一化技巧来近似图-拉普拉斯算子:
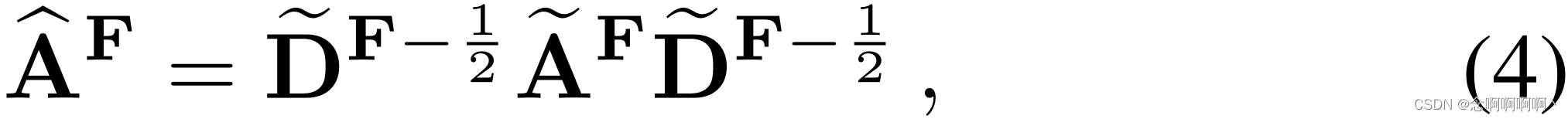
其中自环邻接矩阵(self-loop adjacency matrix)
A
~
F
=
A
F
+
I
n
,
I
n
∈
R
N
×
N
{\widetilde{\mathbf{A}}}^\mathbf{F}=\mathbf{A}^\mathbf{F}+\mathbf{I}_\mathbf{n}, \mathbf{I}_\mathbf{n}\in\mathbb{R}^{N\times N}
A
F=AF+In,In∈RN×N 为单位矩阵;
D
~
(
i
,
i
)
F
=
∑
j
A
~
(
i
,
j
)
F
{\widetilde{\mathbf{D}}}_{(i,i)}^\mathbf{F}=\sum_{j}{\widetilde{\mathbf{A}}}_{(i,j)}^\mathbf{F}
D
(i,i)F=∑jA
(i,j)F 是对应的度矩阵。最后,特征相似度图模块层的输出计算如下:
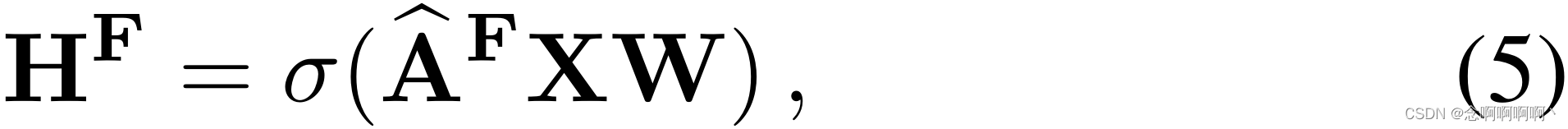
其中 W \mathbf{W} W 是可训练的参数矩阵, σ \sigma σ 是激活函数。由于整个计算过程是可微分的,我们的特征相似度图模块可以以端到端的方式进行训练。因此,神经网络能够无缝地结合单个或多个堆叠模块。尽管上述过程包含一些逐元素计算,但我们在附录中提供了高效的矢量化实现。
最近,Wang 和 Gupta [63] 也建立了相似度图来分析视频。尽管如此,目标和方法都与我们的完全不同:它们旨在捕获具有相关对象 / 区域相似性关系的长期依赖性,而我们试图传播具有整个片段 / 帧相似度的监督信号。
4.2. 时间一致性图模块
正如 [24、46、64] 中指出的那样,时间一致性对许多基于视频的任务都是有利的。时间一致性图 T T T 直接建立在视频的时间结构之上。它的邻接矩阵 A T ∈ R N × N \mathbf{A}^\mathbf{T}\in\mathbb{R}^{N\times N} AT∈RN×N 只依赖于第 i i i 个和第 j j j 个片段的时间位置:
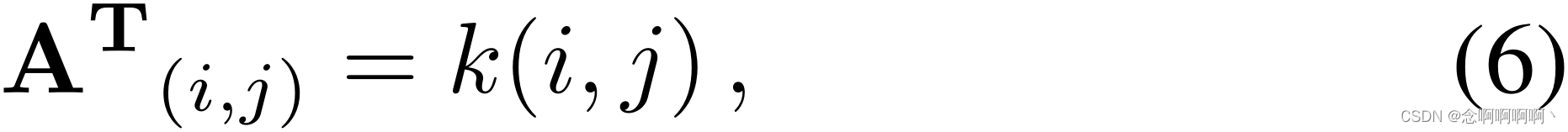
其中
k
k
k 是非负核函数。考虑到内核应该区分各种时间距离并紧密连接附近的片段。在实践中,我们使用在
(
0
,
1
]
(0,\ 1]
(0, 1] 内整齐划界的指数核(也称为拉普拉斯核):
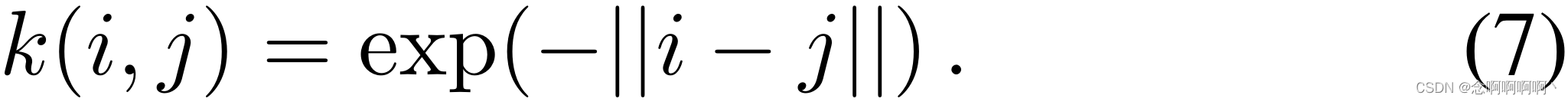
同样,我们得到重新归一化的邻接矩阵
A
^
T
{\hat{\mathbf{A}}}^\mathbf{T}
A^T 作为图拉普拉斯近似如等式 4 所示,并且该模块的前向结果计算为:
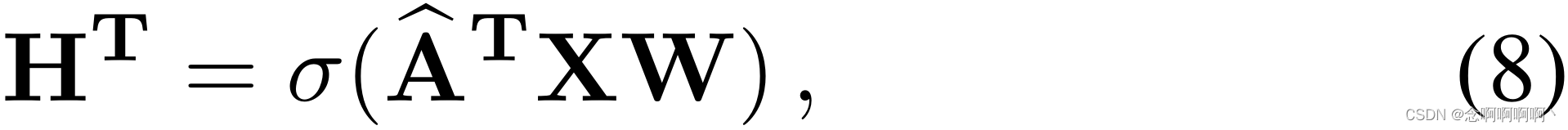
其中 W \mathbf{W} W 是可训练参数矩阵, σ \sigma σ 是激活函数, X \mathbf{X} X 是输入特征矩阵。堆叠的时间一致性图层也可以方便地包含在神经网络中。
4.3. 损失函数
最后,将上述两个模块的输出与一个平均池化层融合,并由一个 Sigmoid 函数激活,使图中每个顶点的概率预测
p
i
p_i
pi 对应于我们的噪声清洁器
w
.
r
.
t
.
w.r.t.
w.r.t. 的异常概率。第
i
i
i 个片段。损失函数
L
L
L 基于两种类型的监督:

其中
L
D
\mathcal{L}_D
LD 和
L
I
\mathcal{L}_I
LI 分别在直接和间接监督下计算。给定来自动作分类器的粗略片段异常概率
Y
~
=
{
y
~
i
}
i
=
1
N
\widetilde{Y}=\left\{{\widetilde{y}}_i\right\}_{i=1}^N
Y
={y
i}i=1N。直接监督下的损失项被定义为高置信度片段的交叉熵损失:
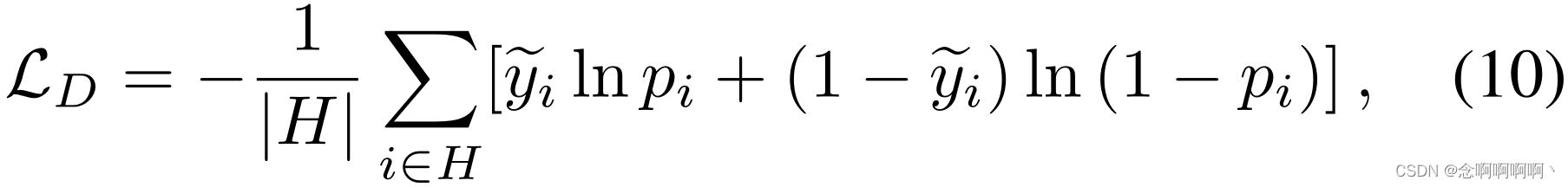
其中 H H H 是一组高置信度的片段。我们使用 “10-crop” 增强对每个视频帧进行过采样,并计算平均异常概率 y ~ i {\widetilde{y}}_i y i 以及动作分类器的预测方差。正如 Kendall 和 Gal [27] 所指出的,方差衡量预测的不确定性。换句话说,方差越小表示置信度越高。这种置信度标准在概念上很简单,但实际上很有效。
间接监督项是一种时间集成策略 [32],可进一步利用少量标记数据,因为高置信度预测仅来自整个视频的一部分。它的主要思想是平滑所有片段在不同训练步骤的网络预测:
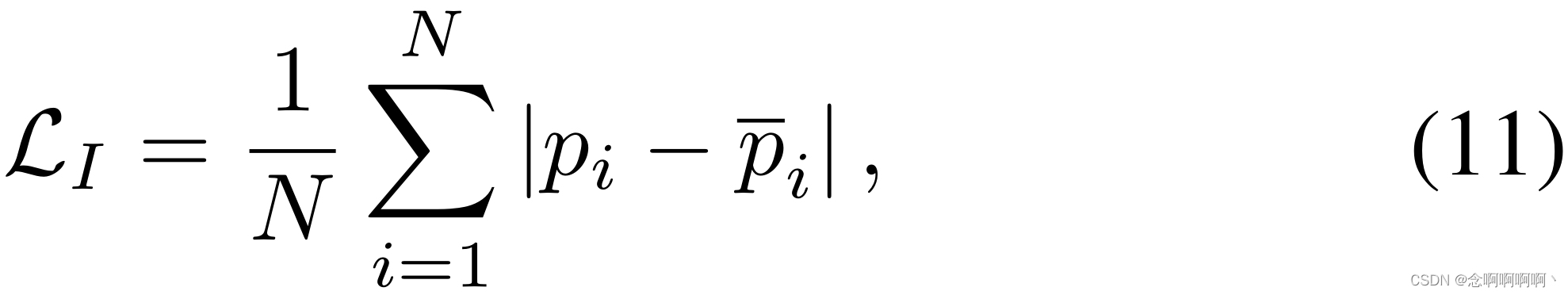
其中
p
ˉ
i
{\bar{p}}_i
pˉi 是我们的噪声清洁器在不同训练时期的折扣加权平均预测。最初的 “酷启动(cool start)” 初始化与我们在附录中解释的实现之间有一个主要的区别,因为我们已经从动作分类器中获得了一组粗略的预测。
4.4. 交替优化
我们的噪声清除器的训练过程只是替代优化的一部分。另一部分,即我们的分类器的训练过程,与常见的完全监督更新完全相同,除了标签是来自我们训练有素的清洁器的片段预测。在重复多次这样的交替优化后,最终的异常检测结果直接由最后训练的分类器预测。显然,在训练或测试阶段几乎不需要改变动作分类器。因此,我们可以方便地在弱标签下训练完全监督的动作分类器,并直接将其部署用于异常检测,而无需所有花里胡哨的东西。
5. 实验
5.1. 数据集和评估指标
我们在三个不同规模的数据集上进行实验,即 UCF-Crime [58]、ShanghaiTech [43] 和 UCSD-Peds [35]。
UCF-Crime 是真实世界监控视频的大规模数据集。它有 13 种类型的异常和 1,900 个未修剪的长视频,其中包括 1,610 个训练视频和 290 个测试视频。
ShanghaiTech 是一个包含 437 个视频的中等规模数据集,包括 13 个场景的 130 个异常事件。在标准协议 [43] 中,所有训练视频都是正常的,此设置不适合二元分类任务。因此,我们通过随机选择异常测试视频到训练数据中来重组数据集,反之亦然。同时,训练视频和测试视频都涵盖了所有 13 个场景。这个新的数据集拆分将可用于后续比较。附录中提供了更多详细信息。
UCSD-Peds 是一个由两个子集组成的小型数据集:Peds1 有 70 个视频,Peds2 有 28 个视频。由于前者更频繁地用于逐像素异常检测 [66],我们只对后者进行实验,如 [43]。同样,默认训练集不包含异常视频。跟随 He 等人 [20],UCSD-Peds2 上的 6 个异常视频和 4 个正常视频被随机包含在训练数据中,其余视频构成测试集。我们还将此过程重复 10 次并报告平均性能。
评估指标。根据之前的工作 [43、20、58],我们绘制了帧级接收器操作特性(ROC)曲线并计算曲线下面积(AUC)作为评估指标。在时间异常检测任务中,较大的帧级 AUC 意味着较高的诊断能力,以及在各种鉴别阈值下的鲁棒性能。
5.2. 实现细节
动作分类器。为了验证我们模型的普遍适用性,我们在实验中使用了两种主流的动作分类器结构。C3D [59] 是一个 3D 卷积网络。该模型在 Sports-1M [26] 数据集上进行了预训练。在训练过程中,我们将其 fc7 层的特征输入到我们的标签噪声清除器中。时间段网络(TSN)[62] 是一种双流架构。我们选择在 Kinetics-400 [10] 上预训练的 BN-Inception [23] 作为主干,并从其全局池层中提取特征来训练我们的噪声清洁器。动作分类器都在 Caffe [25] 平台上实现,具有与 [62] 相同的视频采样和数据增强设置。在所有的实验中,如果没有特别指定,我们保持默认设置。
标签噪声清洁器。在我们的 camera-ready 版本中添加了 author list 和 acknowledgement 部分后,由于篇幅有限,这部分需要移到附录中。请参考我们的 Github 页面和附录。
5.3. UCF-Crime 实验
在视频级别的监督下,我们用 18,000 次迭代训练 C3D。至于 TSN,两个流的初始迭代次数都是 20,000。在每个重新训练步骤中,我们在 4,000 次迭代时停止更新过程。
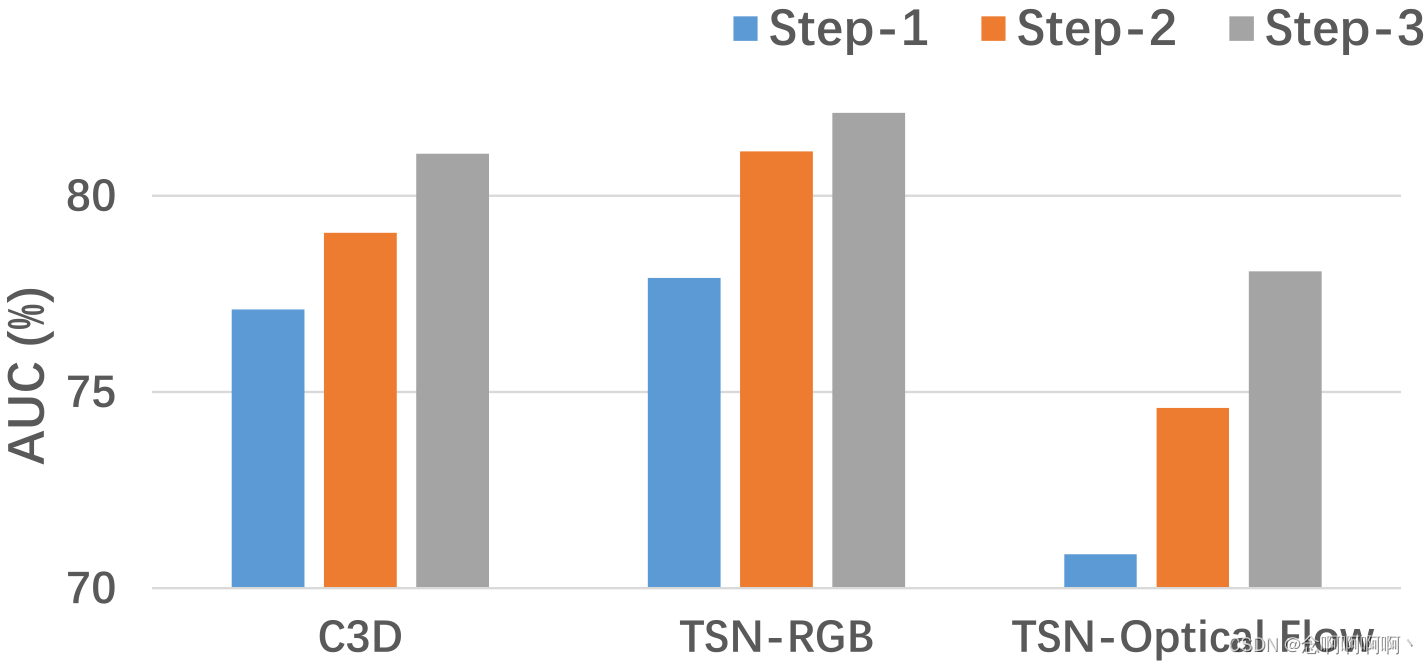
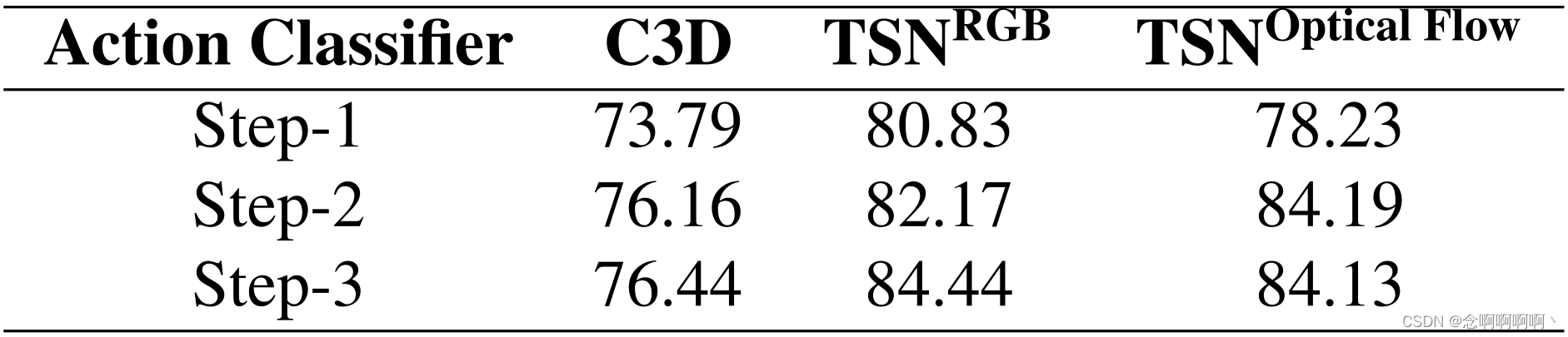
逐步的结果。如图 3 所示,我们报告每个步骤的 AUC 性能以评估我们的替代训练机制的有效性。即使只给定视频级别标签,C3D 和 TSN 的 RGB 分支也可以在 Step-1 实现下降性能。在训练过程中引入动作分类器是我们明智的选择。然而,TSN 的光流远不能令人满意,这反映了我们噪声清洁器的必要性。在以下步骤中,所提出的方法显着提高了所有动作分类器的检测性能。面对初始预测中的大部分噪声,我们的光流分支的 AUC 性能仍然从 70.87% 提高到 78.08%,相对增益为 10.2%。
间接监督。我们对 TSN 的光流模式进行消融研究。首先,我们从损失中排除间接监督项以验证其有效性。如表 1 的第 2 行所示,性能从 74.60% 略微下降到 73.79%,但与 Step-1 的结果相比,增益仍然相当可观。在以下消融中,我们删除了间接监督项以消除干扰。
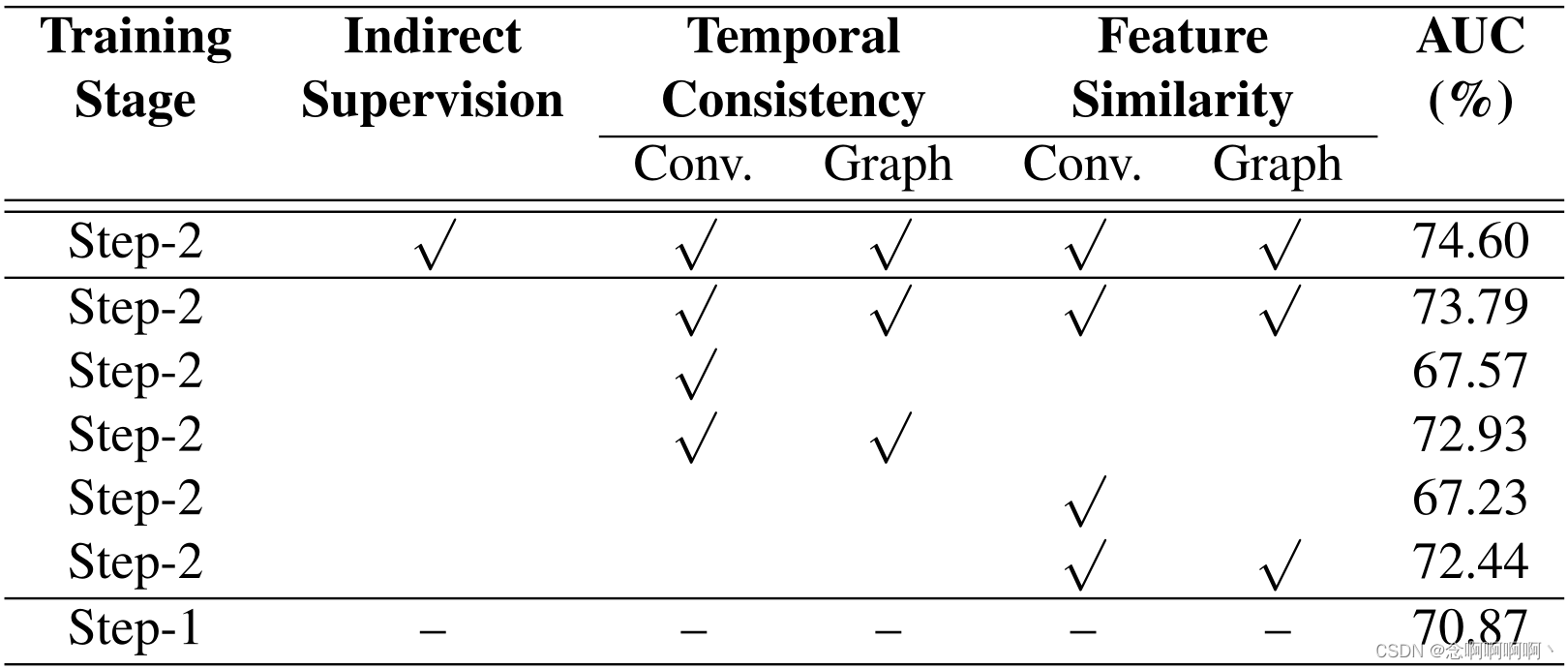
时间一致性。我们想探讨两个问题:时间信息有用吗? 我们的图卷积可以利用这些信息吗? 排除其他干扰因素,只有时间一致性模块。为了删除时间信息图,我们用 0.5(其边界的中值)填充等式 6 中的 A T \mathbf{A}^\mathbf{T} AT,并重现替代训练过程。如表 1 的第 3 行所示,没有时间图的性能比 Step-1 差,在这种情况下,GCN 仅记住高置信度预测的模式而忽略其他片段。至于图卷积的消融,我们观察到独立的时间一致性模块将 AUC 提高到表 1 第 4 行的 72.93%,这表明我们的图卷积确实利用了时间信息。
特征相似性。同样,我们只保留特征相似度模块来研究相似度图和我们的卷积运算的功效。我们首先通过将邻接矩阵的所有元素设置为中值来破坏特征相似度图。如表 1 的第 5 行,AUC 值在没有图表的情况下下降到 67.23%。恢复原始特征相似度图后,单个特征相似度模块可以将 AUC 值从 70.87% 提高到 72.44%,如表 1 第 6 行所示。这说明相似度图和卷积都有助于清除噪声标签。
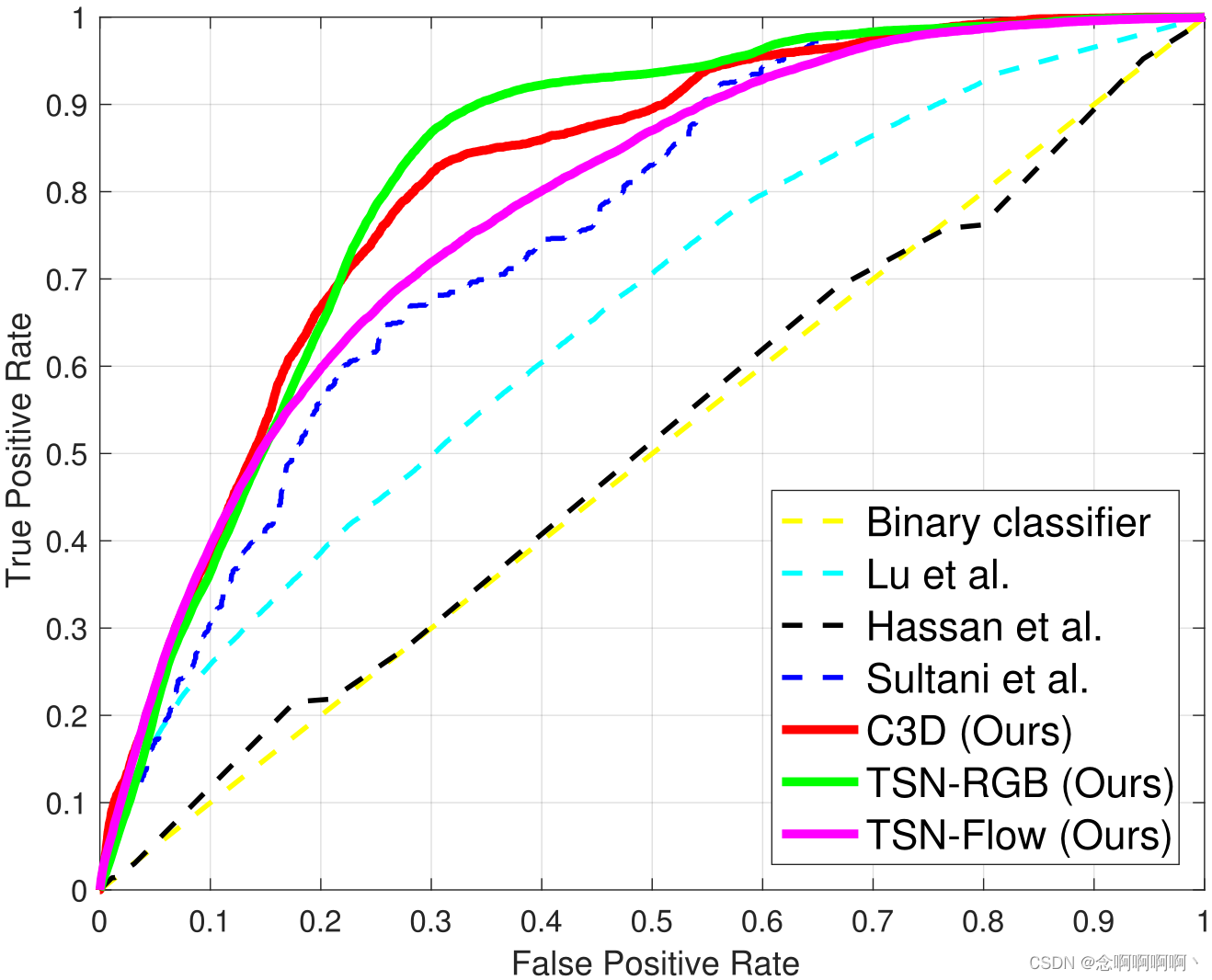
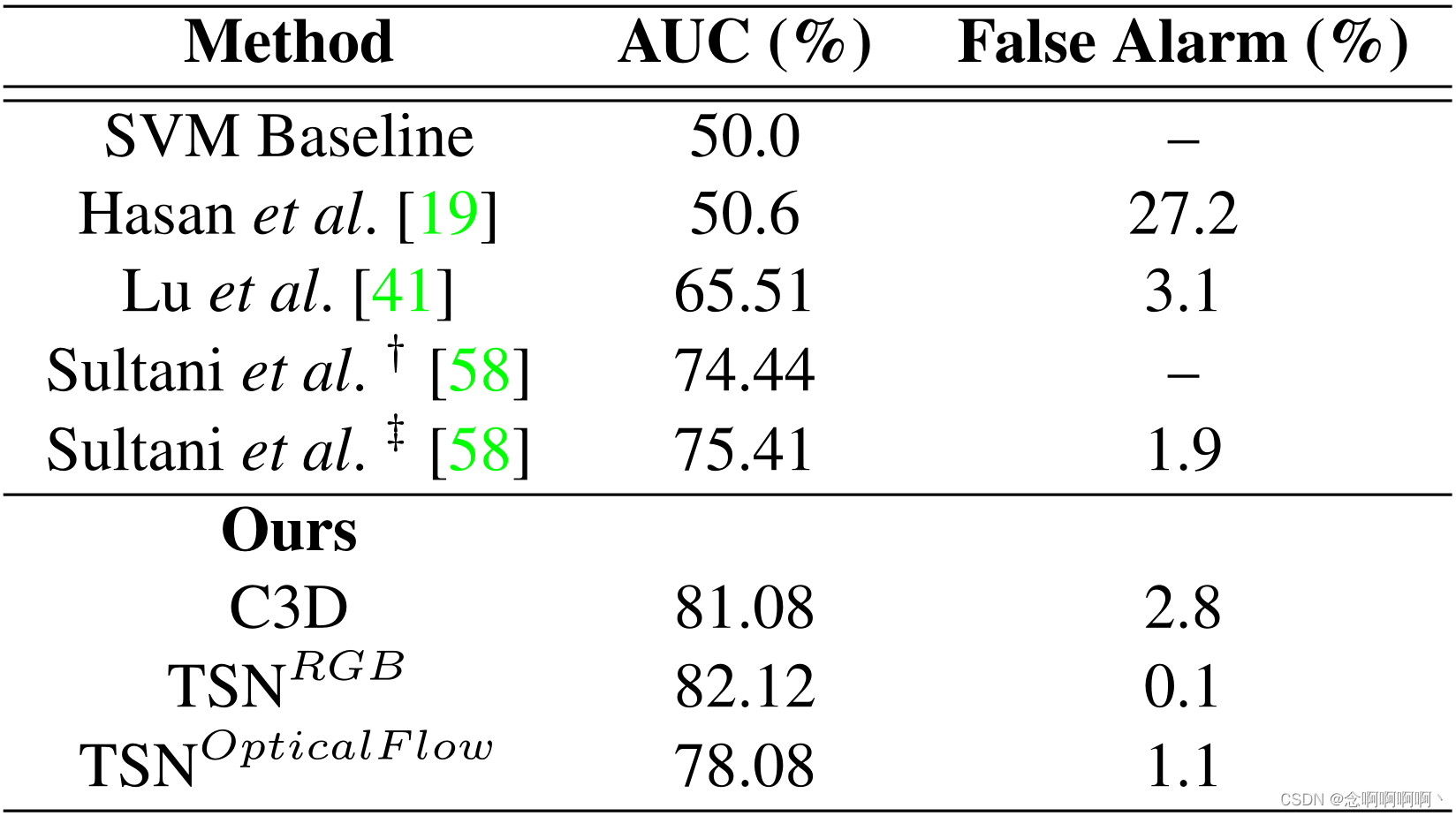
定量比较。我们根据 3 个指标(即 ROC 曲线、AUC 和误报率)将我们的方法与最先进的模型进行比较。如图 4 所示,我们所有动作分类器的曲线几乎完全包围其他分类器,这意味着它们在各种阈值上始终优于竞争对手。三个曲线的平滑度显示了我们提出的方法的高稳定性。如表 2 所示,我们最多将 AUC 值提高到 82.12%。至于 0.5 检测分数的误报率,C3D 略逊于 Sultani 等人,而其他两个分类器相当令人满意,如表 2 所示。值得注意的是,TSN 的 RGB 分支将误报率降低到 0.1%, 迄今为止最佳结果的近 1/20。
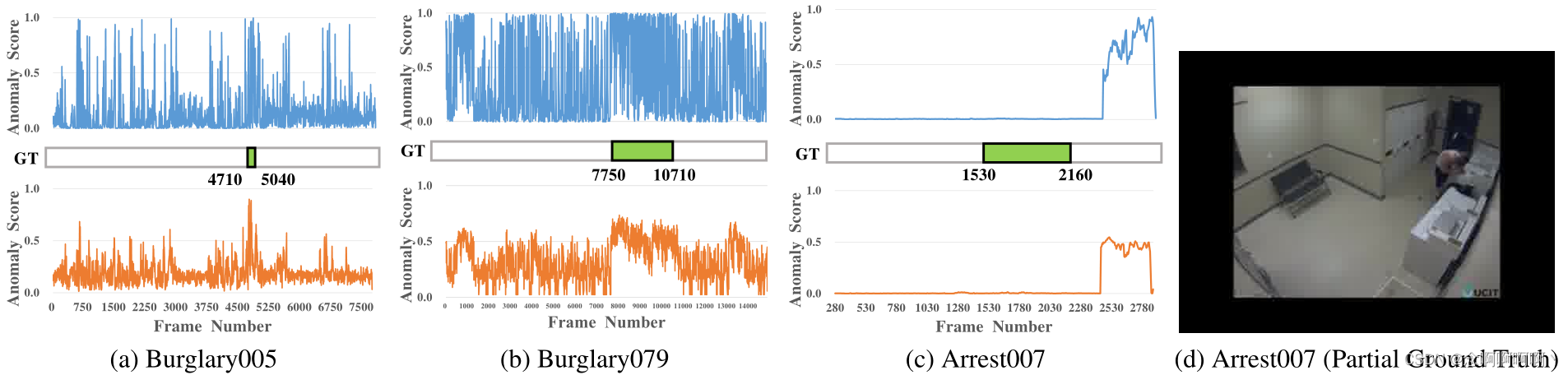
对测试集进行定性分析。为了观察我们模型的影响,我们可视化了动作分类器预测的前后变化。如图 5 所示,我们的去噪过程大大减轻了正常和异常片段中动作分类器的预测噪声。有趣的是,分类器未能从头到尾检测到 “Arrest007” 视频中的异常事件,如图 5c 所示。看完 “逮捕” 类的所有视频后,我们终于发现了可能的原因:训练数据中不存在该测试视频中的相似场景。在此视频中,一名男子因破坏洗衣机而在自助洗衣店被捕,如图 5d 所示,而 “逮捕” 事件发生在高速公路上或训练数据中的收银台。这意味着在通用场景中检测异常事件对于当前模型有限的泛化能力仍然是一个巨大的挑战。
5.4. ShanghaiTech 的实验
逐步的结果。如表 3 所示,在交替训练 w . r . t w.r.t w.r.t 后,性能有所提高。所有的动作分类器。TSN 的光流分支在步骤 3 的结果反映了过多的迭代可能会降低检测性能。尽管如此,我们的方法表现稳健,因为 AUC 值仅略有下降。
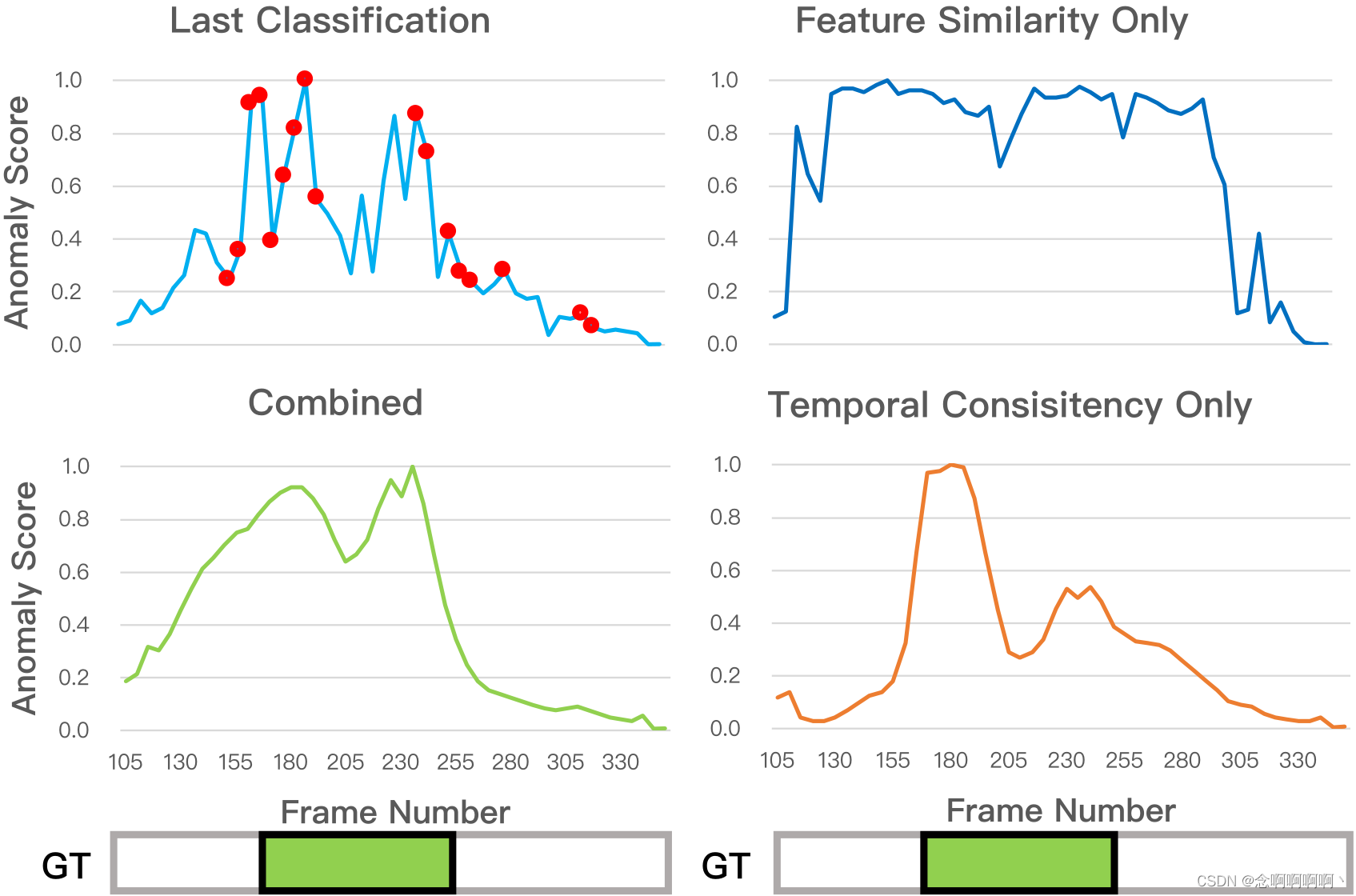
定性分析。与 UCF-Crime 不同的是,ShanghaiTech 新拆分中的训练数据具有时间上的基本事实。基于此,可以直观的理解我们 GCN 的工作原理。图 6 中的异常事件是学生跳过铁轨,如图 7 所示。时间一致性模块(右上角)倾向于平滑原始的高置信度预测(左上角的橙色点)。因此,它使用密集的高置信度预测正确地注释了第 150 到第 200 帧,但忽略了剩余的基本事实,因为高置信度输入不足。特征相似度模块(右下角)倾向于通过相似度传播信息。它标记了一段很长的片段间隔,包括学生之前的助跑和随后的减速动作,可能是因为它们在光流上具有类似的 “沿同一方向快速移动” 的表示。结合这两个模块的整个 GCN(左下)可以做出更精准的标签。

5.5. UCSD-Peds 实验
在 UCSD-Peds 中,一些 ground truth 只有 4 帧,而 C3D 的预测单元达到了 16 帧的长度。因此,我们用 TSN 进行了实验。为了将输入维度与 RGB 分支相匹配,将原始灰度帧复制到 3 个原色通道中。
逐步的结果。重复实验 10 次后,我们得到了图 8 中的箱线图。第一步的平均结果已经足够好了,所以我们开始将前 90% 的高置信度预测输入 GCN。我们观察到所提出的方法不仅提高了检测性能,而且稳定了 10 次重复实验的预测。
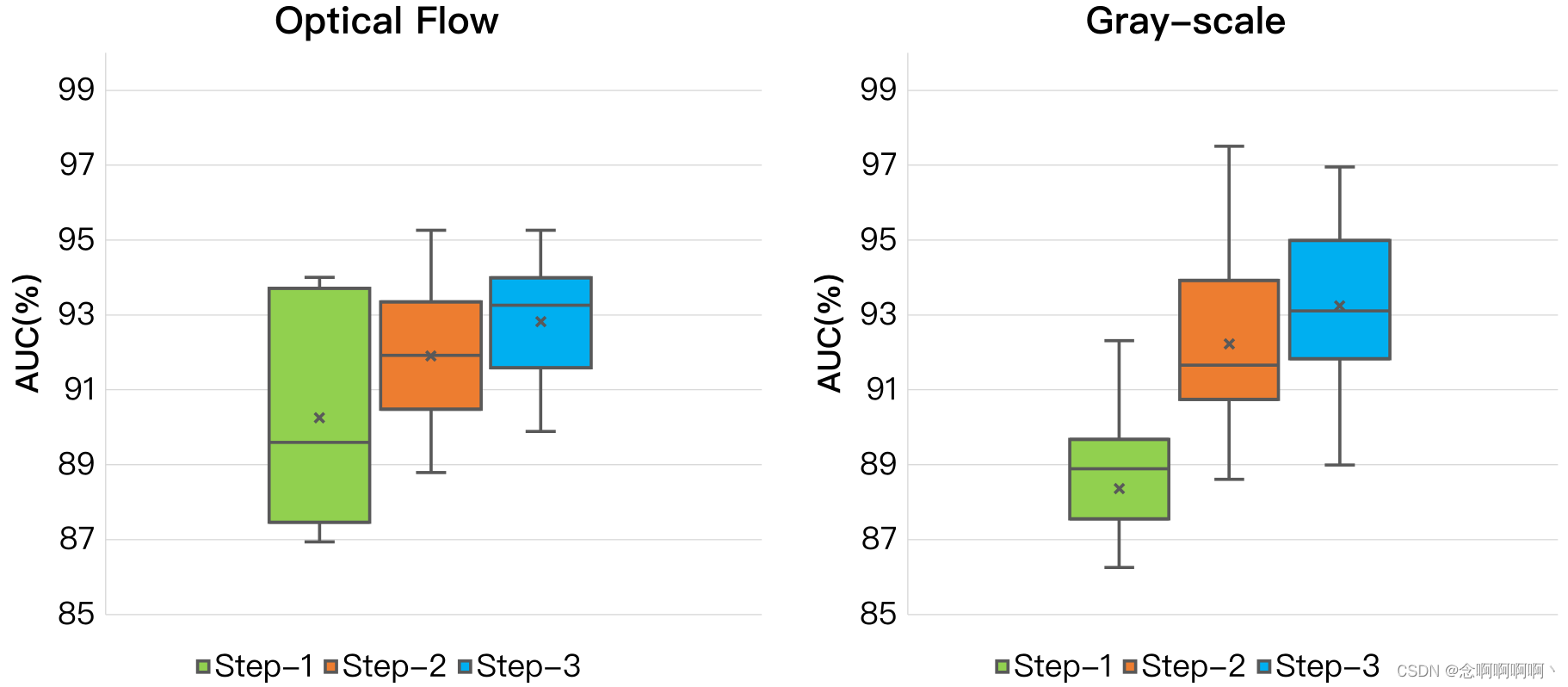
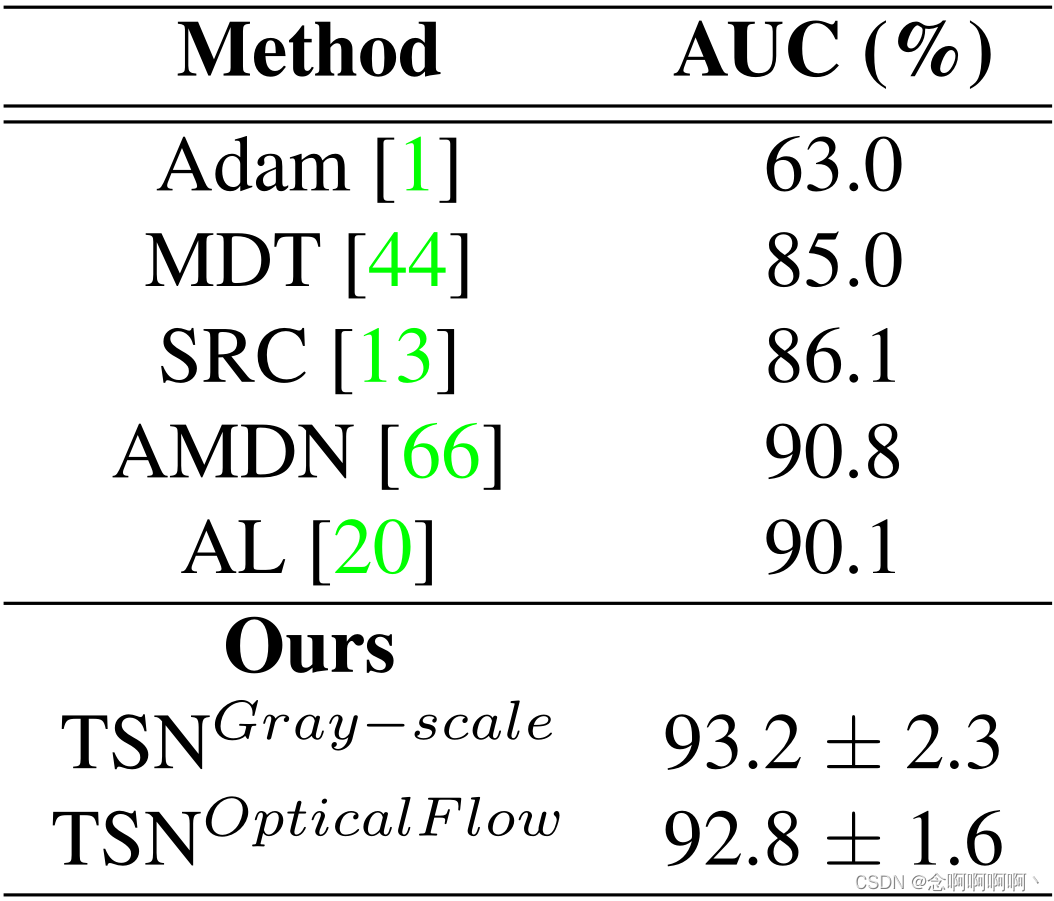
定量比较。我们报告了 AUC 的 “平均值 ± 标准差”,并在与 [20] 相同的拆分协议下与其他方法进行了比较。我们的方法在两种输入方式上都优于其他方法,如表 4 所示。
6. 结论
在本文中,我们从一个新的角度解决了弱监督异常检测问题,将其转化为噪声标签下的监督学习任务。与之前工作中的 MIL 公式相比,这种观点在两个方面具有明显的优点:a)它直接继承了成熟的动作分类器的所有优点;b)异常检测是通过一个完整的端到端模型完成的,非常方便。此外,我们利用 GCN 清理标签来训练动作分类器。在交替优化过程中,GCN 通过将异常信息从高置信度预测传播到低置信度预测来减少噪声。我们在具有 2 种类型的动作分类网络的 3 个不同规模的数据集上验证了所提出的检测模型,其中卓越的性能证明了其有效性和通用性。
参考文献
[1] A. Adam, E. Rivlin, I. Shimshoni, and D. Reinitz. Robust real-time unusual event detection using multiple fixed location monitors. IEEE Transactions on Pattern Analysis and Machine Intelligence, 30:555–560, 2008. 1, 7
[2] K. Adhiya, S. Kolhe, and S. Patil. Tracking and identification of suspicious and abnormal behaviors using supervised machine learning technique. In Proceedings of the International Conference on Advances in Computing, Communication and Control, pages 96–99, 2009. 2
[3] B. Anti and B. Ommer. Video parsing for abnormality detection. In CVPR, pages 2415–2422, Nov. 2011. 2
[4] S. Azadi, J. Feng, S. Jegelka, and T. Darrell. Auxiliary image regularization for deep cnns with noisy labels. In ICLR, 2016. 3
[5] Richard Bellman. Dynamic Programming. Princeton University Press, Princeton, NJ, USA, 1 edition, 1957. 3
[6] Y . Benezeth, P . Jodoin, V . Saligrama, and C. Rosenberger. Abnormal events detection based on spatio-temporal cooccurences. In CVPR, pages 2548–2465, 2009. 1
[7] Avrim Blum and Adam Kalai. A note on learning from multiple-instance examples. Machine Learning, 30(1):23– 29, Jan 1998. 3
[8] J. Bruna, W. Zaremba, A. Szlam, and Y . LeCun. Spectral networks and locally connected networks on graphs. In ICLR, 2014. 3
[9] Marc-Andr Carbonneau, V eronika Cheplygina, Eric Granger, and Ghyslain Gagnon. Multiple instance learning: A survey of problem characteristics and applications. Pattern Recognition, 77:329 – 353, 2018. 3
[10] Joao Carreira and Andrew Zisserman. Quo vadis, action recognition? a new model and the kinetics dataset. In CVPR, pages 4724–4733. IEEE, 2017. 2, 6
[11] Kai-Wen Cheng, Yie-Tarng Chen, and Wen-Hsien Fang. Video anomaly detection and localization using hierarchical feature representation and gaussian process regression. In CVPR, June 2015. 1, 2
[12] Y . S. Chong and Y . H. Tay. Abnormal event detection in videos using spatiotemporal autoencoder. In International Symposium on Neural Networks, pages 189–196, June 2017. 2
[13] Y . Cong, J. Y uan, and J. Liu. Sparse reconstruction cost for abnormal event detection. In CVPR, pages 3449–3456, 2011. 1, 2, 7
[14] M. Defferrard, X. Bresson, and P . V andergheynst. Convolutional neural networks on graphs with fast localized spectral filtering. In NIPS, 2016. 3
[15] C. Feichtenhofer, A. Pinz, and A. Zisserman. Convolutional two-stream network fusion for video action recognition. In CVPR, pages 1933–1941, 2016. 2
[16] Jiyang Gao, Zhenheng Y ang, and Ram Nevatia. Cascaded boundary regression for temporal action detection. In BMVC, 2017. 3
[17] J. Goldberger and E. Ben-Reuven. Training deep neuralnetworks using a noise adaptation layer. In ICLR, 2017. 3
[18] A. Grover and J. Leskovec. Node2vec: Scalable feature learning for networks. In KDD, 2016. 3
[19] M. Hasan, J. Choi, J. Neumann, A. K. Roy-Chowdhury, and L. S. Davis. Learning temporal regularity in video sequences. In CVPR, pages 733–742, June 2016. 2, 6
[20] Chengkun He, Jie Shao, and Jiayu Sun. An anomalyintroduced learning method for abnormal event detection. Multimedia Tools and Applications, 77(22):29573–29588, Nov 2018. 1, 2, 3, 5, 7, 8
[21] T. Hospedales, S. Gong, and T. Xiang. A markov clustering topic model for mining behaviour in video. In ICCV, pages 1165–1172, Sep. 2009. 2
[22] Jing Huo, Y ang Gao, Wanqi Y ang, and Hujun Yin. Abnormal event detection via multi-instance dictionary learning. In Hujun Yin, José A. F. Costa, and Guilherme Barreto, editors, Intelligent Data Engineering and Automated Learning - IDEAL 2012, pages 76–83, Berlin, Heidelberg, 2012. Springer Berlin Heidelberg. 1, 3
[23] Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In International Conference on Machine Learning, pages 448–456, 2015. 5
[24] Dinesh Jayaraman and Kristen Grauman. Slow and steady feature analysis: higher order temporal coherence in video. In CVPR, pages 3852–3861, 2016. 4
[25] Y angqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. Caffe: Convolutional architecture for fast feature embedding. In ACM Multimedia, MM ’14, pages 675–678, New Y ork, NY , USA, 2014. ACM. 6
[26] Andrej Karpathy, George Toderici, Sanketh Shetty, Thomas Leung, Rahul Sukthankar, and Li Fei-Fei. Large-scale video classification with convolutional neural networks. In CVPR, pages 1725–1732, 2014. 2, 5
[27] Alex Kendall and Y arin Gal. What uncertainties do we need in bayesian deep learning for computer vision? In I. Guyon, U. V . Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, and R. Garnett, editors, NIPS, pages 5574–5584. Curran Associates, Inc., 2017. 5
[28] J. Kim and K. Grauman. Observe locally, infer globally: A space-time mrf for detecting abnormal activities with incremental updates. In CVPR, pages 2921–2928, June 2009. 2
[29] Thomas N Kipf and Max Welling. Semi-supervised classification with graph convolutional networks. In Proceedings of the International Conference on Learning Representations (ICLR), 2017. 3, 4
[30] L. Kratz and K. Nishino. Anomaly detection in extremely crowded scenes using spatio-temporal motion pattern models. In CVPR, pages 1446–1453, 2009. 2
[31] W. L, W. Liu, and S. Gao. A revisit of sparse coding based anomaly detection in stacked rnn framework. In ICCV, Oct. 2017. 2
[32] Samuli Laine and Timo Aila. Temporal ensembling for semisupervised learning. In Proceedings of the International Conference on Learning Representations (ICLR), 2017. 5
[33] J. Larsen, L. Nonboe, M. Hintz-Madsen, and L. K. Hansen. Design of robust neural network classifiers. In ICASSP, 1998. 3
[34] N. Li, H. Guo, D. Xu, and X. Wu. Multi-scale analysis of contextual information within spatio-temporal video volumes for anomaly detection. In The IEEE Conference on Image Processing (ICIP), pages 2363–2367, Oct. 2014. 2
[35] W. Li, V . Mahadevan, and N. V asconcelos. Anomaly detection and localization in crowded scenes. IEEE Transactions on Pattern Analysis and Machine Intelligence, 36:18– 32, 2014. 2, 5
[36] Y . Li, D. Tarlow, M. Brockschmidt, and R. Zemel. Gated graph sequence neural networks. In ICLR, 2015. 3
[37] Y . Li, J. Y ang, Y . Song, L. Cao, J. Luo, and J. Li. Learning from noisy labels with distillation. In ICCV, 2017. 3
[38] Tianwei Lin, Xu Zhao, and Zheng Shou. Single shot temporal action detection. In ACM Multimedia, pages 988–996, 2017. 3
[39] Guoqing Liu, Jianxin Wu, and Z-H Zhou. Key instance detection in multi-instance learning. In Asian Conference on Machine Learning, pages 253–268, 2012. 3
[40] W. Liu, W. Luo, D. Lian, and S. Gao. Future frame prediction for anomaly detection a new baseline. In CVPR, June 2018. 2
[41] C. Lu, J. Shi, and J. Jia. Abnormal event detection at 150 fps in matlab. In CVPR, pages 2720–2727, Dec. 2013. 2, 6
[42] W. Luo, W. Liu, and S. Gao. Remembering history with convolutional lstm for anomaly detection. In IEEE International Conference on Multimedia and Expo, pages 439–444, July. 2
[43] Weixin Luo, Wen Liu, and Shenghua Gao. A revisit of sparse coding based anomaly detection in stacked rnn framework. In ICCV, Oct 2017. 2, 5
[44] Vijay Mahadevan, Weixin Li, Viral Bhalodia, and Nuno V asconcelos. Anomaly detection in crowded scenes. In CVPR, pages 1975–1981. IEEE, 2010. 7
[45] R. Mehran, A. Oyama, and M. Shah. Abnormal crowd behavior detection using social force model. In CVPR, pages 935–942, June 2009. 2
[46] Hossein Mobahi, Ronan Collobert, and Jason Weston. Deep learning from temporal coherence in video. In NIPS, pages 737–744. ACM, 2009. 4
[47] S. Mohammadi, A. Perina, H. Kiani, and M. Vittorio. Angry crowds: Detecting violent events in videos. In ECCV, pages 3–18, Oct. 2016. 2
[48] N. Natarajan, I. S. Dhillon, P . Ravikumar, and A. Tewari. Learning with noisy labels. In NIPS, 2013. 3
[49] N.Li, X. Wu, H. Guo, D. Xu, Y . O, and Y . Chen. Anomaly detection in video surveillance via gaussian process. International Journal of Pattern Recognition and Artificial Intelligence, 29:1555011, 2015. 2
[50] M. Ou, P . Cui, J. Pei, Z. Zhang, and W. Zhu. Asymmetric transitivity preserving graph embedding. In KDD, 2016. 3
[51] G. Patrini, A. Rozza, A. Krishna Menon, R. Nock, and L. Qu. Making deep neural networks robust to label noise: A loss correction approach. In CVPR, 2017. 3
[52] Joseph J. Pfeiffer, III, Sebastian Moreno, Timothy La Fond, Jennifer Neville, and Brian Gallagher. Attributed graph models: Modeling network structure with correlated attributes. In ACM WWW, pages 831–842, 2014. 3
[53] Zhaofan Qiu, Ting Y ao, and Tao Mei. Learning spatiotemporal representation with pseudo-3d residual networks. In ICCV, pages 5534–5542. IEEE, 2017. 2
[54] Sivan Sabato and Naftali Tishby. Multi-instance learning with any hypothesis class. Journal of Machine Learning Research, 13(1):2999–3039, Oct. 2012. 3
[55] Clayton Scott, Gilles Blanchard, and Gregory Handy. Classification with asymmetric label noise: Consistency and maximal denoising. In Proceedings of the 26th Annual Conference on Learning Theory, volume 30 of Proceedings of Machine Learning Research, pages 489–511, Princeton, NJ, USA, 12–14 Jun 2013. PMLR. 3
[56] Zheng Shou, Hang Gao, Lei Zhang, Kazuyuki Miyazawa, and Shih-Fu Chang. Autoloc: Weakly-supervised temporal action localization in untrimmed videos. In ECCV, 2018. 3
[57] K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. In NIPS, pages 568–576, 2014. 2
[58] Waqas Sultani, Chen Chen, and Mubarak Shah. Real-world anomaly detection in surveillance videos. In CVPR, June 2018. 1, 2, 3, 5, 6
[59] Du Tran, Lubomir Bourdev, Rob Fergus, Lorenzo Torresani, and Manohar Paluri. Learning spatiotemporal features with 3d convolutional networks. In CVPR, pages 4489–4497, 2015. 2, 5
[60] A. V ahdat. Toward robustness against label noise in training deep discriminative neural networks. In NIPS, 2017. 3
[61] H. Wang and C. Schmid. Action recognition with improved trajectories. In CVPR, pages 3551–3558, 2013. 2
[62] Limin Wang, Y uanjun Xiong, Zhe Wang, Y u Qiao, Dahua Lin, Xiaoou Tang, and Luc V an Gool. Temporal segment networks for action recognition in videos. IEEE Transactions on Pattern Analysis and Machine Intelligence, pages 1–1, 2018. 2, 5, 6
[63] Xiaolong Wang and Abhinav Gupta. Videos as space-time region graphs. In ECCV, September 2018. 2, 4
[64] Laurenz Wiskott and Terrence J Sejnowski. Slow feature analysis: Unsupervised learning of invariances. Neural computation, 14(4):715–770, 2002. 4
[65] S. Wu, B. E. Moore, and M. Shah. Chaotic invariants of lagrangian particle trajectories for anomaly detection in crowded scenes. In CVPR, pages 2054–2060, June 2010. 2
[66] Dan Xu, Y an Y an, Elisa Ricci, and Nicu Sebe. Detecting anomalous events in videos by learning deep representations of appearance and motion. Computer Vision and Image Understanding, 156:117 – 127, 2017. 1, 5, 7
[67] B. Zhao, F. Li, and E. P . Xing. Online detection of unusual events in videos via dynamic sparse coding. In CVPR, pages 3313–3320, June 2011. 2
[68] Y . Zhao, Y . Xiong, L. Wang, Z. Wu, X. Tang, and D. Lin. Temporal action detection with structured segment networks. In ICCV, Oct. 2017. 3
[69] Jia-Xing Zhong, Nannan Li, Weijie Kong, Tao Zhang, Thomas H. Li, and Ge Li. Step-by-step erasion, one-by-one collection: A weakly supervised temporal action detector. In ACM Multimedia, pages 35–44, 2018. 3


















 139
139

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









