







简介:ASP.NET StripHtmlCode 是一个C#项目,旨在教授开发者如何使用正则表达式从HTML文档中提取关键元素,例如标题、文本、图片、链接和表格。该项目不仅介绍了正则表达式的使用,还展示了具体的技术实现方法。通过学习这个项目,开发者能够掌握在ASP.NET环境中使用正则表达式高效处理HTML文档的技能,这对于需要从网页抓取数据和进行数据分析的Web开发项目具有重要意义。 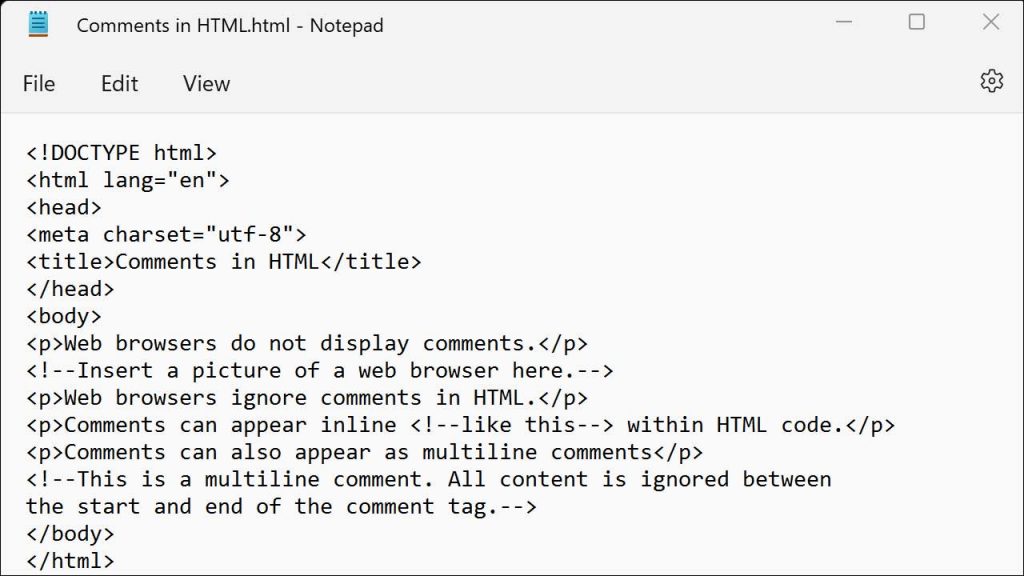
1. ASP.NET中的正则表达式基础
在ASP.NET中,正则表达式是一种强大的文本处理工具,它能够使开发者以模式匹配的方式快速解析和操作字符串。正则表达式不仅简化了复杂的查找和替换任务,而且在数据验证、网页内容提取等方面也发挥着巨大作用。本章节将介绍正则表达式的基本语法及其在ASP.NET中的使用,为后续章节涉及的网页内容提取和数据处理等高级应用打下坚实的基础。
1.1 正则表达式基本概念
正则表达式由一系列字符组成,这些字符包括普通字符(如字母和数字)和元字符(如 . 、 * 、 ? 等)。元字符具有特殊的含义,它们用来构建模式,实现不同的匹配规则。例如,字符 . 表示匹配除换行符以外的任何单个字符,而星号 * 表示匹配前面的子表达式零次或多次。
1.2 正则表达式的组成
正则表达式通常包括以下几个部分:
- 普通字符 :匹配自身,如
a将匹配字母 'a'。 - 特殊字符 :具有特定含义的字符,如
$代表字符串的结束。 - 元字符 :定义了特定的规则,如
*表示匹配前一个字符零次或多次。 - 字符类 :用方括号表示,如
[abc]表示匹配 'a'、'b' 或 'c' 中的任意一个字符。 - 量词 :指定字符重复的次数,如
{n}表示恰好重复 n 次。
掌握正则表达式的这些基本概念和组成,对于理解和使用ASP.NET中的正则表达式至关重要。通过熟悉这些基础知识,我们可以开始探索如何利用正则表达式在ASP.NET应用程序中执行各种文本处理任务。
2. 使用正则表达式提取网页内容
在互联网时代,网页已成为数据的宝库。通过正则表达式从网页中提取信息,可以有效地进行数据分析和信息抓取。本章节将探讨如何使用正则表达式提取网页标题、文本和图片等元素。
2.1 提取网页标题
网页标题通常位于HTML的 <head> 标签内,使用 <title> 标签定义。要正确提取网页标题,需要了解其HTML特征,并通过合适的正则表达式模式进行匹配和提取。
2.1.1 标题的HTML特征
网页标题位于 <title> 标签中,示例如下:
<!DOCTYPE html>
<html>
<head>
<title>这是网页标题</title>
</head>
<body>
<!-- 页面内容 -->
</body>
</html>
2.1.2 正则表达式模式匹配与提取
要使用正则表达式提取标题,可以构造如下的模式:
<title>(.*?)<\/title>
此模式通过 <title> 和 </title> 标签之间的任意字符序列进行匹配,并使用 .*? 进行非贪婪匹配,以确保即使在多个 <title> 标签的情况下,也只提取第一个匹配项。
2.2 提取网页文本
网页文本通常散布在 <body> 标签内,包含多个段落、列表和其他文本元素。为了准确提取所需文本,需要分析其HTML结构,并应用正则表达式的高级技巧。
2.2.1 文本的HTML结构分析
文本内容通常包含在 <p> , <div> , <span> , <li> 等标签内。HTML结构分析示例如下:
<body>
<p>这是一个段落。</p>
<div>
<p>这是一个被div标签包含的段落。</p>
</div>
<ul>
<li>列表项一</li>
<li>列表项二</li>
</ul>
</body>
2.2.2 正则表达式的应用技巧
要提取上述HTML结构中的所有文本,可使用如下正则表达式:
(?:<[^>]+>|)(.+?)(?:<|>)
此模式使用了非捕获组 (?:...) 和正向预查 < 以及负向预查 > 来匹配不包含 > 的任何字符序列。 .+? 表示非贪婪匹配,确保匹配尽可能少的字符,避免遗漏相邻标签内的文本。
2.3 提取网页图片
网页中的图片通常以 <img> 标签的形式存在,包含多个属性,如 src 属性指向图片文件的路径。提取图片链接时,需注意HTML规范并运用合适的正则表达式。
2.3.1 图片标签的HTML规范
一个基本的图片标签如下所示:
<img src="image.jpg" alt="描述文字" />
src 属性包含了图片的URL路径,是我们的目标。
2.3.2 正则表达式的图片链接提取方法
我们可以使用如下正则表达式来提取图片链接:
src="([^"]+)"
这个表达式匹配 src 属性后的等号 = 以及双引号 " 之间的任何字符(不包括双引号),直到遇到另一个双引号为止。 ([^"]+) 捕获组用于提取属性值。
接下来,我们将探讨如何使用正则表达式提取更深层次的网页内容,包括链接和表格数据。
3. 使用正则表达式提取网页深层内容
3.1 提取网页链接
在进行网络爬虫或者数据分析的时候,链接提取是一个非常关键的操作。网页中的链接通常包含在 <a> 标签的 href 属性中。了解这一点,我们可以编写正则表达式来匹配这些链接。
3.1.1 链接在HTML中的表现形式
链接在HTML中通常如下所示:
<a href="https://example.com/page.html">This is a link</a>
链接的URL可以是相对路径或绝对路径。在提取时,我们需要确保正则表达式能够适应不同的情况。
3.1.2 正则表达式链接提取实战
下面给出一个正则表达式的例子,用于匹配上述格式的链接。
using System;
using System.Text.RegularExpressions;
class Program
{
static void Main()
{
string html = @"Visit <a href=""http://example.com"">Example.com</a> now.";
MatchCollection matches = Regex.Matches(html, @"href=""(.*?)""");
foreach (Match match in matches)
{
Console.WriteLine(match.Groups[1].Value);
}
}
}
解释代码逻辑: - Regex.Matches 函数用于查找所有匹配的链接。 - 正则表达式 @"href=""(.*?)""" 中, href="" 定位到链接的开始部分, (.*?) 是一个非贪婪匹配,用来获取链接地址,直到遇到另一个 "" 为止。
3.2 提取网页表格数据
网页表格是信息存储的常用方式之一。表格中的数据通常包含在 <table> 标签内。本节我们将探讨如何使用正则表达式提取表格数据。
3.2.1 表格的HTML结构解析
一个简单的HTML表格结构如下:
<table>
<tr>
<th>Name</th>
<th>Age</th>
</tr>
<tr>
<td>John Doe</td>
<td>30</td>
</tr>
</table>
在表格中, <tr> 标签定义表格行, <th> 用于表头单元格, <td> 用于标准单元格。
3.2.2 正则表达式的表格数据提取技巧
提取表格数据的正则表达式示例:
using System;
using System.Text.RegularExpressions;
class Program
{
static void Main()
{
string html = @"
<table>
<tr>
<th>Name</th>
<th>Age</th>
</tr>
<tr>
<td>John Doe</td>
<td>30</td>
</tr>
</table>";
var pattern = @"<tr>(?:\s*<td>(.*?)</td>\s*)+";
MatchCollection matches = Regex.Matches(html, pattern);
// 创建表格数据结构
string[,] tableData = new string[matches.Count + 1, 2];
for (int i = 0; i < matches.Count; i++)
{
Match match = matches[i];
tableData[i, 0] = match.Groups[1].Value; // Name
tableData[i, 1] = match.Groups[2].Value; // Age
}
// 打印表格数据
for (int i = 0; i < tableData.GetLength(0); i++)
{
Console.WriteLine(tableData[i, 0] + "," + tableData[i, 1]);
}
}
}
解释代码逻辑: - 正则表达式 @"<tr>(?:\s*<td>(.*?)</td>\s*)+" 匹配每一行 <tr> 内的 <td> 标签。 - (?: ... )+ 是非捕获组,表示匹配 <td> 标签的一个或多个实例。 - 每个匹配的 <td> 标签内容存储在 match.Groups[1].Value 和 match.Groups[2].Value 中。
我们创建了一个二维数组 tableData 来存储表格数据,并遍历匹配结果将其填入数组,最后打印出来。
通过这些步骤,我们可以深入提取网页中包含的深层内容,如链接和表格数据。这些操作在数据抓取和网络爬虫任务中极其有用,同时需要强调的是,正确和安全地使用正则表达式是至关重要的,以防止潜在的性能问题或安全漏洞。
4. VB.NET与C#代码实现
4.1 VB.NET实现网页内容提取
4.1.1 VB.NET环境配置
在开始VB.NET编程之前,确保你的开发环境已经正确配置。通常,我们可以使用Visual Studio来创建和管理VB.NET项目。以下是一些基本的环境配置步骤:
- 下载并安装Visual Studio Community版,这是微软提供的免费、全功能的开发环境。
- 在安装过程中,选择安装“.NET桌面开发”工作负载,这将安装VB.NET支持以及相关的开发工具。
- 创建一个新的VB.NET项目,选择“控制台应用程序”或其他适合你需求的项目类型。
- 安装并配置任何必需的库或NuGet包,以便执行网络请求和解析HTML文档。
一旦完成了以上步骤,你的环境就配置好了,可以开始编写VB.NET代码来提取网页内容了。
4.1.2 VB.NET中的正则表达式应用案例
在VB.NET中使用正则表达式提取网页内容,首先需要了解 System.Text.RegularExpressions.Regex 类。这个类为正则表达式提供了强大的支持。以下是一个示例,演示如何使用VB.NET中的正则表达式来提取网页的标题:
Imports System.Text.RegularExpressions
Module WebContentExtractor
Sub Main()
' 假设我们已经有了一个包含HTML的字符串
Dim htmlContent As String = "<html><head><title>Example Title</title></head></html>"
' 创建一个正则表达式来匹配<title>标签内的内容
Dim titleRegex As New Regex("<title>(.*?)</title>")
' 使用正则表达式匹配并提取标题
Dim titleMatch As Match = titleRegex.Match(htmlContent)
If titleMatch.Success Then
Console.WriteLine("The title is: " & titleMatch.Groups(1).Value)
Else
Console.WriteLine("No title found.")
End If
End Sub
End Module
在上面的代码中,我们首先导入了正则表达式相关的命名空间,然后定义了一个字符串 htmlContent 来模拟从网页获取的HTML内容。通过创建一个 Regex 实例并调用 Match 方法,我们就可以查找和提取 <title> 标签内的文本。这种方法可以应用到提取网页中的其他内容,比如链接、图片或任何需要的数据。
4.2 C#实现网页内容提取
4.2.1 C#环境配置
配置C#开发环境和VB.NET相似,只不过在编程语言和一些API调用上有差异。以下是配置C#环境的步骤:
- 同样需要下载并安装Visual Studio Community版。
- 在安装过程中,确保选择“.NET桌面开发”工作负载。
- 创建一个新的C#项目,并选择一个适合你需求的模板,如控制台应用程序。
- 根据需要安装额外的库或NuGet包。
一旦你的开发环境配置完成,你就可以开始利用C#强大的语法和库来实现功能了。
4.2.2 C#中的正则表达式应用案例
和VB.NET一样,C#也提供了强大的正则表达式支持。以下是一个示例,使用C#和正则表达式来提取网页的标题:
using System;
using System.Text.RegularExpressions;
class WebContentExtractor
{
static void Main()
{
// 模拟从网页获取的HTML内容
string htmlContent = "<html><head><title>Example Title</title></head></html>";
// 创建一个正则表达式来匹配<title>标签内的内容
Regex titleRegex = new Regex("<title>(.*?)</title>");
// 使用正则表达式匹配并提取标题
Match titleMatch = titleRegex.Match(htmlContent);
if (titleMatch.Success)
{
Console.WriteLine("The title is: " + titleMatch.Groups[1].Value);
}
else
{
Console.WriteLine("No title found.");
}
}
}
在这个例子中,我们同样使用了 Regex 类和 Match 方法来查找并提取 <title> 标签内的文本。通过这种方式,你可以根据需要提取网页上的任何其他信息,如链接、图片、表格数据等。
在进行网页内容提取时,你可能需要使用到网络请求库,如 HttpClient ,来进行实际的网页下载。之后,你就可以使用正则表达式来解析和提取所需的数据。这种方法不仅适用于简单的网页内容提取,还可以处理更复杂的网页结构解析任务。
5. 正则表达式在ASP.NET中的应用实例
5.1 ASP.NET页面动态内容提取
5.1.1 动态内容的特点与挑战
ASP.NET页面中经常包含动态生成的内容,这些内容由服务器端代码根据用户的请求动态生成。例如,可能根据用户身份显示不同的菜单选项,或者根据数据库查询动态生成商品列表。与静态内容相比,动态内容的特点在于其结构不是固定的,可能会包含各种JavaScript、服务器控件和框架。
这种动态生成的内容对正则表达式提取提出了挑战,因为相同的HTML结构在不同的动态内容中可能会有所不同。例如,一个用户ID可能在一个页面中被嵌入在 <div class="user-id"> 标签内,在另一个页面可能被放在 <span id="userId"> 标签内。这就需要设计更为通用和健壮的正则表达式来提取这些动态变化的内容。
5.1.2 实现动态内容提取的策略
为了有效提取动态内容,开发者可以采取以下策略:
- 分段匹配 :不要试图一次性匹配整个结构,而是分成多个小段进行匹配,这有助于减少因动态内容变化导致的整体匹配失败。
- 通用模式 :采用尽可能通用的模式。例如,如果要匹配数字ID,使用
\d+比特定数字或特定格式的字符串更可靠。 - 异常处理 :在代码中增加异常处理机制,当匹配失败时可以进行适当的错误处理,比如记录日志、跳过错误内容或者发送告警通知。
下面的代码演示了一个简单的ASP.NET页面动态内容提取示例:
using System.Text.RegularExpressions;
using System.Web;
public static string ExtractDynamicContent(string htmlContent, string pattern)
{
// 将HTML内容进行解码,处理服务器端动态生成的HTML特殊字符
string decodedContent = Server.HtmlDecode(htmlContent);
// 使用正则表达式匹配动态内容
MatchCollection matches = Regex.Matches(decodedContent, pattern);
if (matches.Count > 0)
{
// 输出所有匹配结果
foreach (Match match in matches)
{
// 这里可以添加具体的处理逻辑,比如进一步的提取或转换
Console.WriteLine(match.Value);
}
}
else
{
Console.WriteLine("No match found.");
}
}
5.2 正则表达式在数据清洗中的应用
5.2.1 数据清洗的重要性
数据清洗是将原始数据转换为高质量数据的过程。原始数据通常包含许多不一致、重复、错误或不完整的值,这些都需要被修正、删除或补充。数据清洗对于数据分析、数据挖掘和数据存储等任务至关重要,因为不干净的数据会严重影响这些过程的准确性和效率。
5.2.2 正则表达式的清洗规则设计
使用正则表达式可以有效地设计规则来清洗数据:
- 删除不必要字符 :例如,删除字符串前后的空格、特殊符号等。
- 格式统一 :比如将日期格式统一为"yyyy-MM-dd",电话号码格式统一为"XXX-XXXXXXX"等。
- 重复值处理 :使用正则表达式查找并删除重复的数据条目。
- 拼写检查 :检查并纠正拼写错误。
以下是一个使用C#中的正则表达式进行数据清洗的代码示例:
using System.Text.RegularExpressions;
public static string CleanseData(string dirtyData, string pattern, string replacement)
{
// 使用正则表达式替换模式匹配到的内容
string cleansedData = Regex.Replace(dirtyData, pattern, replacement);
return cleansedData;
}
// 示例:清洗掉字符串中的所有数字
string dirtyString = "I have 2 pets, 1 cat and 3 dogs.";
string cleansedString = CleanseData(dirtyString, @"\d+", string.Empty);
Console.WriteLine(cleansedString); // 输出: "I have pets, cat and dogs."
通过上述实例可以看出,正则表达式在动态内容提取和数据清洗方面,提供了强大的灵活性和适用性。合理设计正则表达式模式并结合实际场景进行优化,可以大大提升数据处理的效率和准确性。
6. ASP.NET项目中正则表达式的高级运用
随着网络技术的飞速发展,ASP.NET项目变得越来越复杂,其中数据处理占据了重要位置。正则表达式作为一种强大的文本处理工具,在项目中扮演着不可或缺的角色。在本章节中,我们将探讨如何在ASP.NET项目中高级运用正则表达式,包括提升效率、加强安全性等。
6.1 提升正则表达式的效率
正则表达式的效率对于大型项目至关重要。不当的表达式不仅会导致性能下降,还可能使服务器负担过重,从而影响用户体验。
6.1.1 正则表达式的性能考量
性能问题往往是由于复杂的表达式和大量的文本搜索造成的。为了优化性能,首先需要了解正则表达式的匹配过程,它分为三个阶段:
- 编译阶段 :正则表达式引擎将表达式编译成内部代码,编译效率直接影响到正则表达式的整体性能。
- 匹配阶段 :引擎在目标文本中寻找匹配的位置,此过程可能涉及到回溯,特别是在使用了贪婪匹配和捕获组的情况下。
- 返回结果阶段 :找到匹配后,引擎返回结果。
为了避免不必要的性能开销,我们应该遵循以下原则:
- 尽可能使用简单的表达式 :简单意味着编译快,执行效率高。
- 减少回溯的使用 :回溯是正则表达式中导致性能问题的主要因素之一,使用量词时要小心。
- 避免不必要的捕获组 :每个捕获组都会增加额外的处理时间。
6.1.2 优化正则表达式的方法
优化方法可以从多个角度入手,以下是一些实用技巧:
- 非贪婪匹配 :使用非贪婪量词来减少匹配过程中的回溯。
- 固定宽度的前缀 :使用固定宽度的前缀可以快速排除大部分非匹配情况。
- 使用忽略大小写标志 :当不区分大小写时,明确使用
(?i)标志,以减少引擎的处理时间。 - 使用正向预查和正向后查 :它们可以帮助你跳过不需要检查的文本。
接下来给出一个性能优化的代码示例:
// 示例代码:使用非贪婪匹配减少回溯
string input = "long string with complex data";
// 使用非贪婪量词
string pattern = "^(.+?)(?=<data>)"; // 正则表达式解释:匹配任意字符直到遇到'<data>'标签,但不包括它
Match m = Regex.Match(input, pattern);
if (m.Success)
{
// 输出匹配结果
Console.WriteLine(m.Groups[1].Value); // 输出 'long string with complex'
}
在这个示例中,使用了非贪婪量词 +? 来确保正则表达式引擎尽可能少地回溯,从而提高匹配效率。
6.2 正则表达式在安全中的角色
正则表达式不仅能提升开发效率,还具有强大的安全保护能力。尤其在处理用户输入时,正确的正则表达式可以有效防止注入攻击。
6.2.1 防止注入攻击的正则应用
注入攻击是一种常见的网络攻击方式,它依赖于系统对用户输入的不当处理。以下是一些防止注入攻击的正则应用技巧:
- 验证用户输入 :使用正则表达式验证用户输入,确保它符合预期的格式。
- 禁止特殊字符 :拦截包含SQL、JavaScript等特殊字符的输入,以防止注入。
- 限制输入长度 :对输入数据长度设置限制,这可以有效减少注入攻击的风险。
6.2.2 正则表达式的安全编码实践
编写安全的正则表达式需要考虑多种因素,以下是一些实践建议:
- 避免直接使用用户输入 :不要直接将用户输入用作正则表达式的输入,这可能引起安全漏洞。
- 使用白名单验证 :仅当输入匹配一组预期的模式时才接受,避免黑名单方法,因为攻击者可能找到未列出的漏洞。
- 更新和测试 :定期检查和更新正则表达式,确保它们能够防御最新发现的安全漏洞。
下面是一个防止SQL注入的代码示例:
// 示例代码:防止SQL注入的正则表达式验证
string userInput = "Robert'); DROP TABLE Students;--";
string safeInputPattern = @"^[A-Za-z0-9]+$"; // 只允许字母和数字
if (!Regex.IsMatch(userInput, safeInputPattern))
{
throw new ArgumentException("Invalid input, potential SQL injection attempt.");
}
else
{
// 使用安全的用户输入构造SQL语句
string safeInput = Regex.Replace(userInput, @"[';]", "");
string sql = $"SELECT * FROM Students WHERE name = '{safeInput}'";
}
在这个例子中,正则表达式 ^[A-Za-z0-9]+$ 用于确保用户输入只包含字母和数字,任何特殊字符都会触发异常,从而保护数据库免受注入攻击。
通过上述方法,我们可以有效提升ASP.NET项目中正则表达式的使用效率,同时确保项目安全性。在项目中合理运用正则表达式,既能够加速开发进程,又能保证系统的健壮性和安全性。
7. 总结与展望
ASP.NET中正则表达式使用的总结以及正则表达式未来的发展方向是本章的重点。我们将回顾前面章节中所讨论的关键概念和技巧,并展望正则表达式在未来的可能趋势。
7.1 ASP.NET中正则表达式使用的总结
7.1.1 理论与实践的结合点
在ASP.NET开发中,正则表达式不仅可以用于匹配和提取网页内容,还能优化数据处理流程。结合具体案例,我们已经了解到正则表达式在理论与实践中的结合点。例如,在提取网页链接和图片的场景中,通过理解HTML结构,我们能够设计出有效的正则表达式模式来实现需求。
7.1.2 常见问题与解决策略
正则表达式的学习曲线虽然陡峭,但通过不断的实践与优化,开发者可以掌握其精髓。在使用过程中,我们可能会遇到性能瓶颈或复杂匹配需求。这时,理解正则表达式的高级特性,如懒惰量词、正向和反向查找等,是解决问题的关键。实践中,合理优化正则表达式、使用缓存模式和避免贪婪匹配等技巧,能够有效提升代码效率。
7.2 正则表达式未来的发展方向
7.2.1 新兴技术与正则表达式的融合
随着人工智能、机器学习等新兴技术的发展,正则表达式也可以与其他技术融合,以应对更加复杂和动态的处理场景。比如,可以结合自然语言处理技术,让正则表达式在文本解析上变得更加智能和自适应。
7.2.2 正则表达式的学习资源与社区
正则表达式的知识更新迅速,学习资源和社区交流对于提升技能至关重要。开发者可以通过在线教程、编程社区、专业论坛等途径来不断充实和更新自己的正则表达式知识库。在实际应用中遇到问题时,这些资源和社区提供的支持,可以帮助开发者更加快速地找到解决方案。
graph LR
A[开始学习正则表达式] --> B[掌握基础理论]
B --> C[通过案例实践]
C --> D[遇到问题与挑战]
D --> E[查阅学习资源]
E --> F[社区交流获得帮助]
F --> G[结合新兴技术深化理解]
G --> H[总结经验,形成知识体系]
通过上述流程图,我们可以看到正则表达式学习过程中的几个关键步骤,并理解持续学习和交流对于掌握该技能的重要性。随着技术的演进,正则表达式将不断地与其他领域相融合,开发者的技能也将随之拓展和升级。
简介:ASP.NET StripHtmlCode 是一个C#项目,旨在教授开发者如何使用正则表达式从HTML文档中提取关键元素,例如标题、文本、图片、链接和表格。该项目不仅介绍了正则表达式的使用,还展示了具体的技术实现方法。通过学习这个项目,开发者能够掌握在ASP.NET环境中使用正则表达式高效处理HTML文档的技能,这对于需要从网页抓取数据和进行数据分析的Web开发项目具有重要意义。

















 975
975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









