






产品目标:高效的获取信息
需求复杂多变,我们需要从复杂的集合中找到正确的信息
不同用户输入同一query词表达的需求不一致,同一用户在不同场景下输入的query词表达需求也不一样
需求理解:(广义的query词解析)
A)需求明确(例:北京天气) →直接需求理解
B)需求明确,对方案有特殊要求(例:猪肉的最新价格) 机器有一个筛选规则,根据网页的生成时间等
C)需求不明确,需要进行扩展和预测
A1):需求明确
结构简单清晰地query:经过协同处理可进行后续操作(会根据相关度决定词与词之间的紧密程度)(切词处理)
例:黄山火车站订票电话→ 黄山 火车 站 订票 电话
A2)需求明确
口语的query:需要进行纠错,同意转换等语义处理
能、可以、好么、吗?
例:杭州至盐城告诉怎么走? → 杭州 至 盐城 高速 怎么 走?
至→ from ...to.... 怎么走→map →跳转到地铁的建索引擎里 高速:类型
B)需求明确:对答案有特殊要求
除了统一的query词变换外,需要将特定要求转换成搜索引擎可理解的特征
例:猪肉最新价格→资源时效性
PPT素材→可用性&特定格式
猩球崛起迅雷下载→资源可用性
C)需求不明确
需求需要扩展和预测
欢乐颂:欢乐颂视频、剧情介绍、演员表、评价
猩球崛起3:上映前预告片上映时间、上映后介绍票房,下映后介绍评论视频
拓展维度:
上下文数据:搜了欢乐颂之后,用户是否主动更新query词搜欢乐颂视频
类目数据:对于欢乐颂,这种电视剧专名,天然就有视频、剧情等需求,
pm可以提前梳理针对各类目的需求扩展list。
个性化数据:对于特定类目可以。
一个query经过以上分类处理后,会统一成以下这样的输出,来进行接下来的检索
- 需求类目/需求词
- 需求强度
- 待检索term/pattern
- 其他限定特征(地域等)
衡量指标:
A)每个query分析规则的召回率和准确率
B)各需求的召回率和准确率
解决方案 :排序&展现
排序:
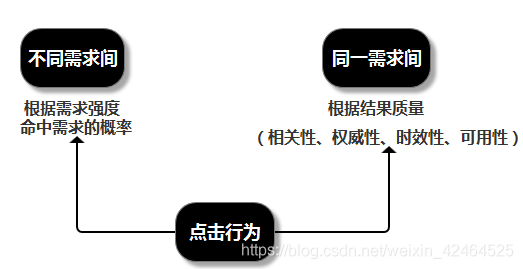
展现:
通用策略:将结果页中与与query相关的信息提取为标题/摘要,进行漂红等处理帮助用户筛选信息。
*对于搜有搜索引擎:都是将搜索对象中用户最关心的内容提前至检索结果列表页,并根据各种情况以强化的样式展现。
细化策略:针对不同的需求,又有如下不同的细化策略
A)对于单一明确信息需求,可以直接将答案信息在摘要中展现
B)对于用户接下来的路径相对收敛的需求,可以将下一步需求前置,缩短步骤
例:网易邮箱(登录),欢乐送视频(集数),凡人歌(播放)
C)对于不同资源类型结果,可以针对优化摘要
例:视频类、图片类、新闻类、地图类等
衡量指标:
A)每个需求打分、质量打分、展现策略的召回率和准确率
B)用户角度的搜索的满足度
基于用户行为的搜索满足度:
A)摘取满足型需求→少/很少点击行为
B)但结果满足型需求→点击集中于首条结果
C)主动变换query比例低
D)翻页比例低等等
基于人为评估的搜索满足度:
A)query前3/5/10结果相关性→基于人为需要判断,当前结果是否能满足;与竞品相比,是否有更好的结果未收录,排序是否更优等
B)session满意度→从用户一个行为片段分析其是否得到满足
资源支撑:
网页收录(spider):
A)保证各网页收录覆盖率
B)保证各类网页收录时效性:根据网页类型定义更新频率,重要或时效性高的资源可选择站长主动提交的方式。
页面分析:对页面类型进行识别,页面中内容解析,为term附权等
衡量指标:
A)对于nlp相关,各类词库、处理策略的准确率,召回率;
B)对于网页收录,收录覆盖率,更新时效性等
C)对于页面分析,各类准确率,召回率等。

















 6223
6223

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









