







 本文介绍了Hive作为基于Hadoop的数据仓库工具,重点讲解了Hive SQL的基础语法,包括分区表操作、GROUP BY 分类汇总、ORDER BY 排序,以及常用的聚合函数、时间戳转换和字符串函数。同时,还详细阐述了各种表连接(INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN)和UNION ALL的用法,最后总结了SQL执行顺序和常见错误避免。
本文介绍了Hive作为基于Hadoop的数据仓库工具,重点讲解了Hive SQL的基础语法,包括分区表操作、GROUP BY 分类汇总、ORDER BY 排序,以及常用的聚合函数、时间戳转换和字符串函数。同时,还详细阐述了各种表连接(INNER JOIN、LEFT JOIN、RIGHT JOIN、FULL JOIN)和UNION ALL的用法,最后总结了SQL执行顺序和常见错误避免。
1. HIVE
简介: HIVE是基于hadoop的数据仓库。
HivesQL与传统SQL的对比:
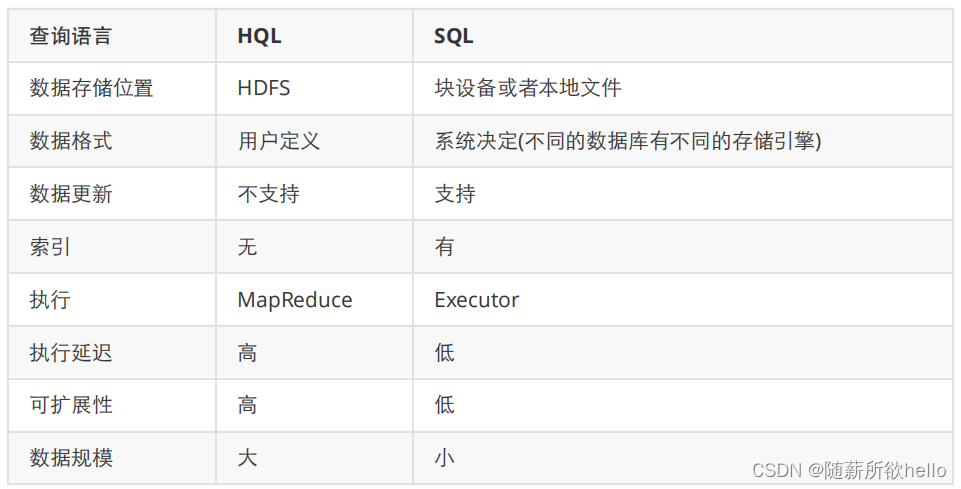
注:块设备是i/o设备中的一类,是将信息存储在固定大小的块中,每个块都有自己的地址,价备的任意位置读取一定长度的数据,例如硬盘,U盘,SD卡等。
2.MapReduce简介
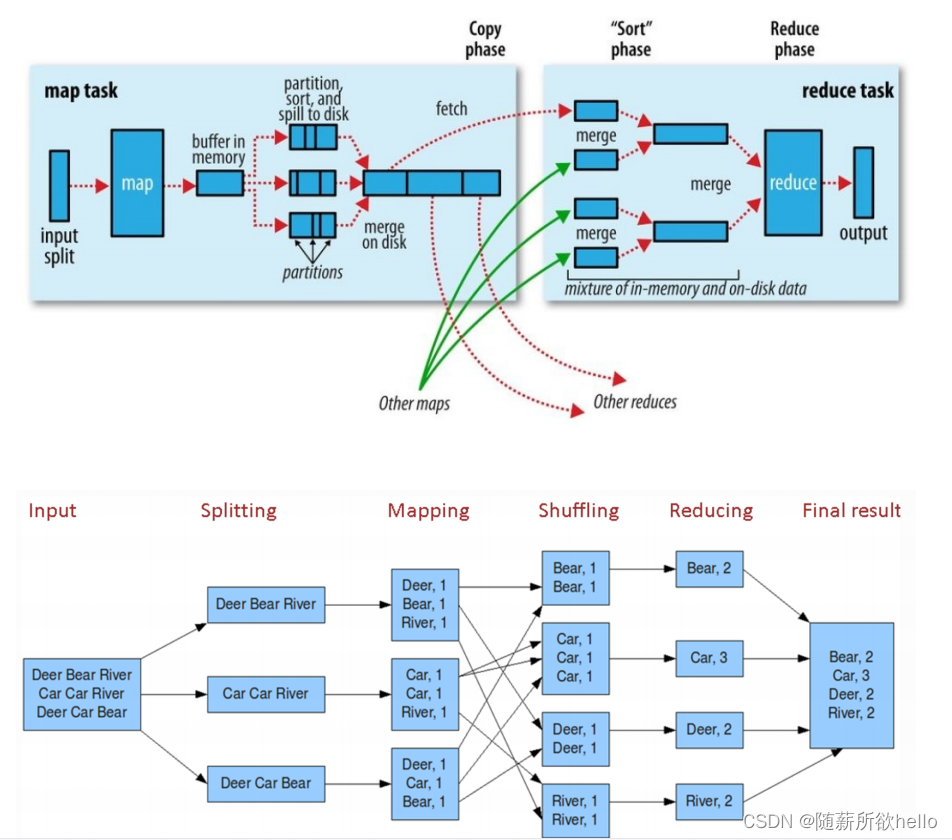
3.基础语法
SELECT A FROM B WHERE C
A:列名
B:表名
C:筛选条件;
例:选出城市在北京,性别为女的10个用户名。
SELECT user_name
FROM user_info
WHERE city='beijing'and sex='female'
limit 10;
3.1 分区表
注: 如果该表是一个分区表,则WHERE条件中必须对分区字段进行限制。
例:选出在2019年4月9日,购买的商品品类是food的用户名、购买数量、支付金额
SELEcT user_name.
piece
pay_amount
FROM user_trade
WHERE dt='2019-04-09 '
and goods_category='food';
注:未对分区进行限制的报错:
SELECT user_name,
piece,
pay_amount
FROM user_trade
WHERE goods_category='food' ;

注意: 分区表必须限制分区字段;
3.2 GROUP BY 分类汇总
例:2019年一月到四月,每个品类有多少人购买,累计金额是多少。
SELECT goods_category,
count(distinct user_name) as user_num,
sum(pay_amount) as total_amount
FROM user_trade
WHERE dt between '2019-01-01' and '2019-04-30'
GROUP BY goods_category;
常用聚合函数
count()计数(count…distinct …)去重计数
sum() 求和
min() 最小值
max() 最大值
avg() 平均值
3.3 GROUP BY …HAVING
HAVING:对GROUP BY的对象进行筛选,仅返回符合HAVING条件的结果。
例:2019年4月,支付金额超过5万元的用户。
SELECT user_name,
sum(pay_amount) as total_amount
FROM user_trade
WHERE dt between '2019-04-01' and '2019-04-30'
GROUP BY user_name
HAVING sum(pay_amount)>50000;
3.4 ORDER BY
例:2019年4月,支付金额最多的TOP5用户。
SELECT user_name,
sum(pay_amount) as total_amount
FROM user_trade
WHERE dt between '2019-04-01' and '2019-04-30'
GROUP BY user_name
ORDER BY total_amount DESC
limit 5;
ASC:升序(默认);
DESC:降序;
对多个字段进行排序:ORDER BY A ASC , B DESC;
3.5 执行顺序
FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY

4常用函数
4.1 时间戳转化为日期 from_unixtime(bigint unixtime, string format)
format:
- yyyy-MM-dd hh:mm:ss
- yyyy-MM-dd hh
- yyyy-MM-dd hh:mm
- yyyyMMdd
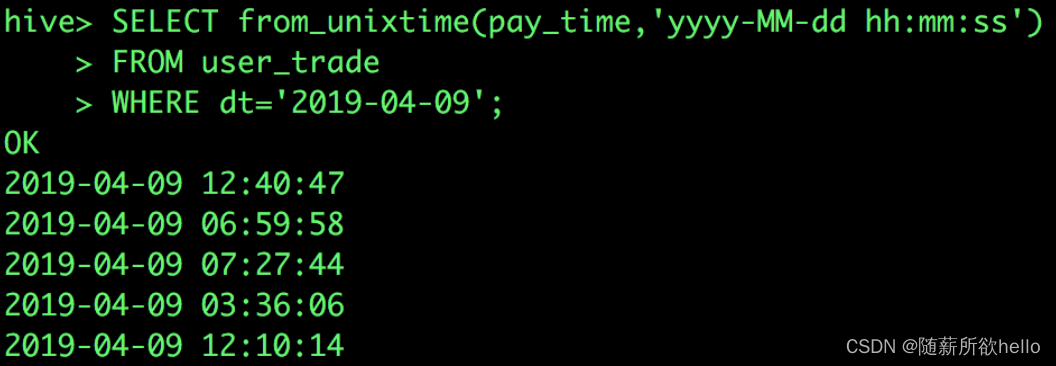
SELECT pay_time,
from_unixtime(pay_time,'yyyy-MM-dd hh:mm:ss')
FROM user_trade
WHERE dt='2019-04-09';
4.2 日期转化为时间戳 unix_timestamp(string date)
4.3 时间间隔 datediff(string enddate, string startdate)
注:datediff(string enddate, string startdate):结束日期-开始日期的天数
例:用户的首次激活时间,与2019年5月1日的时间间隔
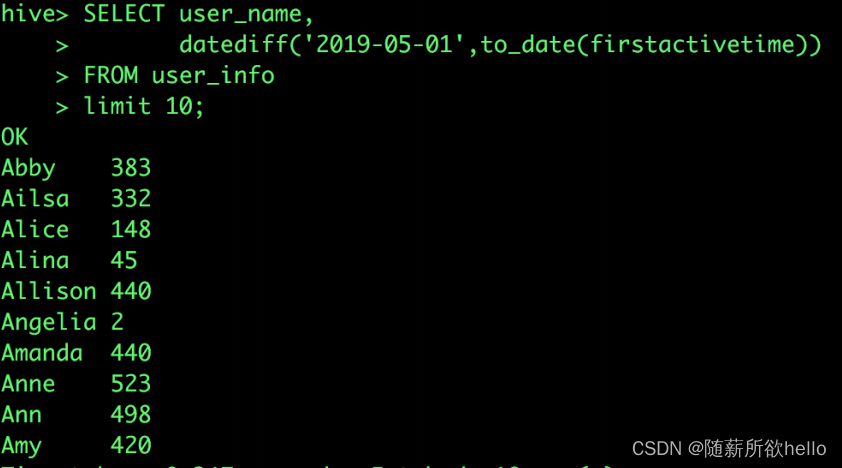
SELECT user_name,
datediff('2019-05-01',to_date(firstactivetime))
FROM user_info
limit 10;
4.4 日期增加函数 date_add(string startdate, int days)
4.5 date_sub (string startdate, int days)
5条件函数
5.1 case when
例:统计四个年龄段20岁以下,20-30岁,30-40岁,40岁以上的用户数
SELECT
case
when age<20 then '20¯# '
when age>=20 and age<30 then '20-30¯ '
when age>=30 and age<40 then '30-40¯ '
else '40岁以上 ' end,
count(distinct user_id) user_num
FROM user_info
GROUP BY
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











