




 本文详细介绍了Java Class文件的结构,包括编译过程中的词法分析、语法分析、注解语义分析和字节码生成。Class文件包含常量池和方法字节码,是Java程序在JVM上运行的基础。通过javap命令可以解析Class文件以理解其内容。
本文详细介绍了Java Class文件的结构,包括编译过程中的词法分析、语法分析、注解语义分析和字节码生成。Class文件包含常量池和方法字节码,是Java程序在JVM上运行的基础。通过javap命令可以解析Class文件以理解其内容。
Class文件是个啥?
为啥需要编译?
大家都知道Java是一门静态语言,java文件会通过编译生成class文件,运行时jvm直接加载运行class文件。jvm面向字节码而不是机器码,个人理解有以下几个好处:
- java虚拟机在机器和java程序之间抽象出来一个统一的接口,使得编译出来的同一份字节码文件可以在不同的平台上运行;
- 提前把源码的校验、编译等耗时操作放到编译过程,加快程序执行效率;
- java可以认为是一种半解释性语言(jvm通过实时解释class文件生成机器码运行),即拥有解释性语言可移植的特性,也兼顾了执行效率(对1,2点的总结);
- 编译期优化,编译过程可以加入对源码的优化,提高程序执行效率;
- jvm是面向字节码的,因此当有新的java语法糖出现时,只需要在编译器层面进行适配生成对应的字节码即可;
- 编译后的文件只保留关键信息,体积更小,方便传输;
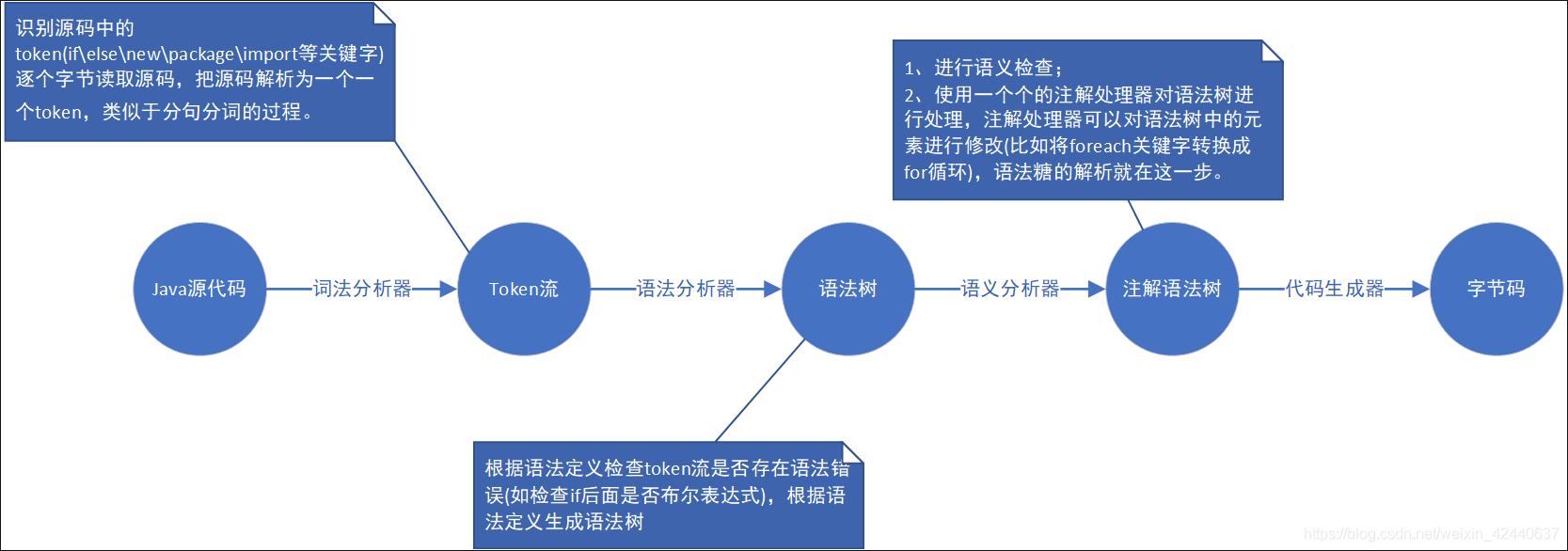
- 词法分析
输入:java源代码
输出:Token流
过程:根据java定义的关键字把源代码片段切分为一句句的执行命令(Token,字符串为单位),并为Token打上标记。词法分析器通常不会关心标记之间的关系(属于语法分析的范畴),举例来说:词法分析器能够将括号识别为标记,但并不保证括号是否匹配。 - 语法分析
输入:Token流
输出:语法树
过程:
a. 检查Token是否存在语法错误,比如 if(a=b){…},在语法分析阶段会报错。
b. 生成语法树
此阶段会对单个token进行语法分析,不能保证token的上下文语义信息是否正确。 - 注解语义分析
输入:语法树
输出:注解语法树
过程:
a. 对语法树进行语义检查。比如定义了常量final int a=0;若后面对a进行赋值,则会报错;
b. 使用不同的注解解析器对语法树进行修改,比如对java语法糖的支持,把foreache关键字转化为for循环基础操作
c. 去除无用的代码
d. 对代码进行重排优化等(c,d可以理解为b的具体操作) - 生成代码
输入:注解语法树
输出:.class字节码文件
过程:根据注解语法树,和字节码文件的规则生成字节码文件。
字节码文件是什么?
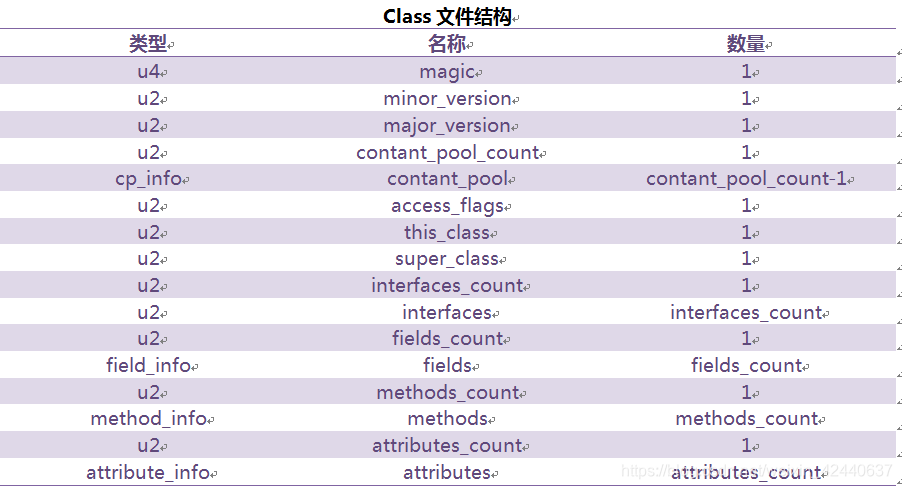
编译后的字节码文件格式主要分为两部分:常量池和方法字节码。
常量池记录的是代码出现过的字面量(文本字符串、八种基本类型的值、被声明为final的常量等)以及符号引用(类和方法的全限定名、字段的名称和描述符、方法的名称和描述符);
方法字节码中放的是各个方法的字节码(依赖操作数栈和局部变量表,由JVM解释执行)
文件结构:
下面根据一个简单的例子分析一下:
public class HelloWorld {
public void main(String args[]){
System.out.println("hello world");
}
}
先看一下反编译结果:
public class HelloWorld {
public HelloWorld() {
}
public void main(String[] args) {
System.out.println("hello world");
}
}
再看一下字节码文件:
CA FE BA BE 00 00 00 34 00 22 0A 00 06 00 14 09 00 15 00 16 08 00 17 0A 00 18 00 19 07 00 1A 07
00 1B 01 00 06 3C 69 6E 69 74 3E 01 00  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









