







 本文详细介绍MySQL数据库的基本操作,包括连接服务器、创建与删除数据库、表的增删改查、备份与恢复、SQL语句优化等。此外,还介绍了索引、事务处理及权限管理等内容。
本文详细介绍MySQL数据库的基本操作,包括连接服务器、创建与删除数据库、表的增删改查、备份与恢复、SQL语句优化等。此外,还介绍了索引、事务处理及权限管理等内容。
x连接到mysql服务器:
mysql -h IP -P 端口号 -u root -p通过java程序操作数据库:
创建删除数据库:
utf8_bin 区分大小写
utf8_general_ci 不区分大小写
#创建一个数据库
CREATE DATABASE hsp_db01;
#删除数据库----慎用
DROP DATABASE hsp_db01;
#创建一个带utf8的数据库
CREATE DATABASE hsp_db02 CHARACTER SET utf8
#创建一个带utf8的数据库并带校对规则
CREATE DATABASE hsp_db03 CHARACTER SET utf8 COLLATE utf8_bin基础查询
SELECT * FROM t1 WHERE NAME = 'tom'显示数据库语句:
SHOW DATABASES #显示所有数据库
SHOW CREATE DATABASE hsp_db02 #查看数据库的创建方法备份数据库:在DOS命令行进行
mysqldump -u root -p -B 数据库1 数据库2 > D:\\beifen.sql备份单独的表:
mysqldump -u root -p 数据库1 表1 表2 数据库2 表2 > D:\\beifen.sql恢复数据库:在mysql里面
source d:\\beifen.sql创建表:
create table `user`(
id int,
`name` varchar(255),
`password` varchar(255),
`birthday` date)
character set utf8 collate utf8_bin engine innodb;修改表:
在resume后面添加列:
ALTER TABLE `emp`
ADD image VARCHAR(3) NOT NULL DEFAULT " "
AFTER RESUME
修改job列,使其长度为60
ALTER TABLE `emp`
modify job varchar(60) not null default ""删除sex列:
ALTER TABLE `emp`
DROP sex修改表名:
RENAME TABLE `emp` TO employee修改列名字:
ALTER TABLE `emp`
CHANGE NAME user_name VARCHAR(32) DEFAULT NOT NULL ''增删改查:
往表中添加数据:insert into
INSERT INTO `emp` VALUES(100,"小妖怪","男",2022)INSERT INTO `goods` (id,goods_name,price)
VALUES(10,"huawei",2000)查看表所有数据:
SELECT * FROM goodsupdate语句:把所有人的工资改成5000----慎用不带where的
UPDATE employee SET sal = 5000将bobo的工资改成5000
UPDATE `employee`
SET sal = 5000
WHERE user_name = "bobo"加薪水:将波波的工资加1000
UPDATE `employee`
SET sal = sal + 1000,job="出主意的"
WHERE user_name = "bobo"删除波波相关的所有信息:
DELETE FROM emp
WHERE user_name = "bobo"删除所有记录:不要where,,慎用
删除表:慎用
drop table employeeSELECT语句:
查询表中所有的学生:
SELECT * FROM students查询表中所有学生的姓名和对应的英语成绩:
SELECT `name`,`english` FROM students去掉重复数据:
SELECT DISTINCT `name`,`english` FROM students 用select对列进行运算:
统计每个学生的总分:
SELECT `name`,(chinese+english+math) AS `all` FROM students把所有学生的总分加10:
select `name`,(chinese+english+math+10) as `all` from students求出所有总分>100的同学:
SELECT * FROM students
WHERE (chinese+english+math) AS `all` > 100名字以韩开头的----LIKE
SELECT * FROM students
WHERE (chinese+english+math) AS `all` > 100
AND `name` LIKE "韩%"排序:order by asc|desc升序和降序
按数学成绩排序:
select * from students
order by math降序排序:
select * from students
order by math descSELECT `name`,(chinese+english+math) AS `all` FROM students
ORDER BY `all` DESC合计/统计函数count
统计学生总数:
SELECT COUNT(*) FROM students数学成绩大学90的学生总数
select count(*) from students
where math>90count(*)和count(列)----忽略空 的区别:
统计函数sum
统计一个班数学总成绩:
select sum(math) from students各科总成绩:
SELECT SUM(math),SUM(english) FROM students统计所有语文成绩平均分:
select sum(math)/count(*) from studentsavg求一个班的数学平均分:
select AVG(math) from students总分平均分:
select AVG(math+english) from students最大值:max,最小值min
select max(math) from students分组统计:group by
按部门查询工资:
SELECT AVG(sal),MAX(sal),deptno
FROM emp GROUP BY deptno每个部门,每个岗位的平均工资:
SELECT AVG(sal),MAX(sal),deptno,job
FROM emp GROUP BY deptno,job平均工资小于2000的
select AVG(sal),max(sal),deptno
from emp group by deptno
HAVING AVG(sal)<2000字符串相关函数的使用:
字符编码:
SELECT CHARSET(ename) FROM emp字符串拼接:
SELECT CONCAT(ename,"工作是",job) FROM emp首字母小写取出值:
SELECT CONCAT LCASE SUBSTRING(ename,1,1),SUBSTRING(ename,2)
FROM emp或者
SELECT CONCAT LCASE LEFT(ename,1),SUBSTRING(ename,2)
FROM emp流程控制语句:
#流程控制语句
SELECT IF(TRUE,"北京","上海") FROM DUAL
SELECT ename,IF(comm IS NULL,0.0,comm)
FROM emp流程控制语句2:
SELECT ename,(SELECT CASE
WHEN job="clerk" THEN "职员"
WHEN job="manger" THEN "经理"
ELSE job END) AS job
FROM emp单表增强:
查询加强,先按部门排序,在按工资降序:
SELECT * FROM emp
ORDER BY dep ASC,sal DESC查询加强, 分页查询:
SELECT * FROM emp
ORDER BY id_num
LIMIT 0,3
#第一页
SELECT * FROM emp
ORDER BY id_num
LIMIT 3,3
#第二页
#语法:limit start,rows
#语法:limit 每页显示记录数*(第几页-1),每页显示记录数#显示各个岗位的雇员总数,平均工资
#显示各个岗位的雇员总数,平均工资
SELECT COUNT(*),AVG(sal),job
FROM emp
GROUP BY job统计没有获得补助的雇员数:
SELECT COUNT(*),COUNT(*)-COUNT(comm)
FROM emp统计去重:
SELECT COUNT(DISTINCT mgr)
FROM emp多子句查询:
SELECT dept,AVG(sal) AS avg_sal
FROM emp
GROUP BY dept
HAVING avg_sal > 1000
ORDER BY avg_sal DESC
LIMIT 0,2多表查询:
写sql先写简单的,然后加入过滤条件
关键是要分析出过滤条件:
SELECT ename,sal,emp.dname FROM emp,dept
WHERE emp.deptno = dept.deptno AND dept.deptno = 10显示员工的姓名,工资和工资级别:
SELECT ename,sal,grade
FROM emp,salgrade
WHERE sal BETWEEN losal AND histal自连接:显示公司员工和他上级的名字:
一定要取别名,表取别名,可以不加as
SELECT worker.ename AS "职员名",boss.ename AS "上司名"
FROM emp AS emp01,emp AS emp02
WHERE worker.mgr=boss.empno多行子查询:先找出过滤条件,
SELECT *
FROM emp
WHERE deptno=(
SELECT deptno
FROM emp
WHERE ename="smith"
)多行子查询2:
SELECT *
FROM emp
WHERE job IN (
SELECT DISTINCT job
FROM emp
WHERE deptno=10
)AND deptno !=10子查询临时表:
表复制:
INSERT INTO mytab_01
(id,`name`,sal,job,deptno)
SELECT empno,ename,sal,job,deptno FROM emp自我复制:表复制(蠕虫复制)
INSERT INTO mytab_01
SELECT * FROM mytab_01表去重:1.先创建一张新表tab_02,让tab_02有重复的记录
#创建一个新表
CREATE TABLE table_02 LIKE emp
#新表插入数据
INSERT INTO my_table02
SELECT * FROM emp
#数据去重,思路:
#1)先创建一个新表my_temp
CREATE TABLE my_temp LIKE my_table02
#2)通过关键字distinct处理,把数据记录到my_temp
INSERT INTO my_temp
SELECT DISTINCT * FROM my_table02
#3)清除my_table02的所有记录
DELETE FROM my_table02
#4)把my_temp的记录复制到mytable_02
INSERT INTO my_table02
SELECT * FROM my temp
#5)drop掉临时表my_temp
DROP TABLE my_temp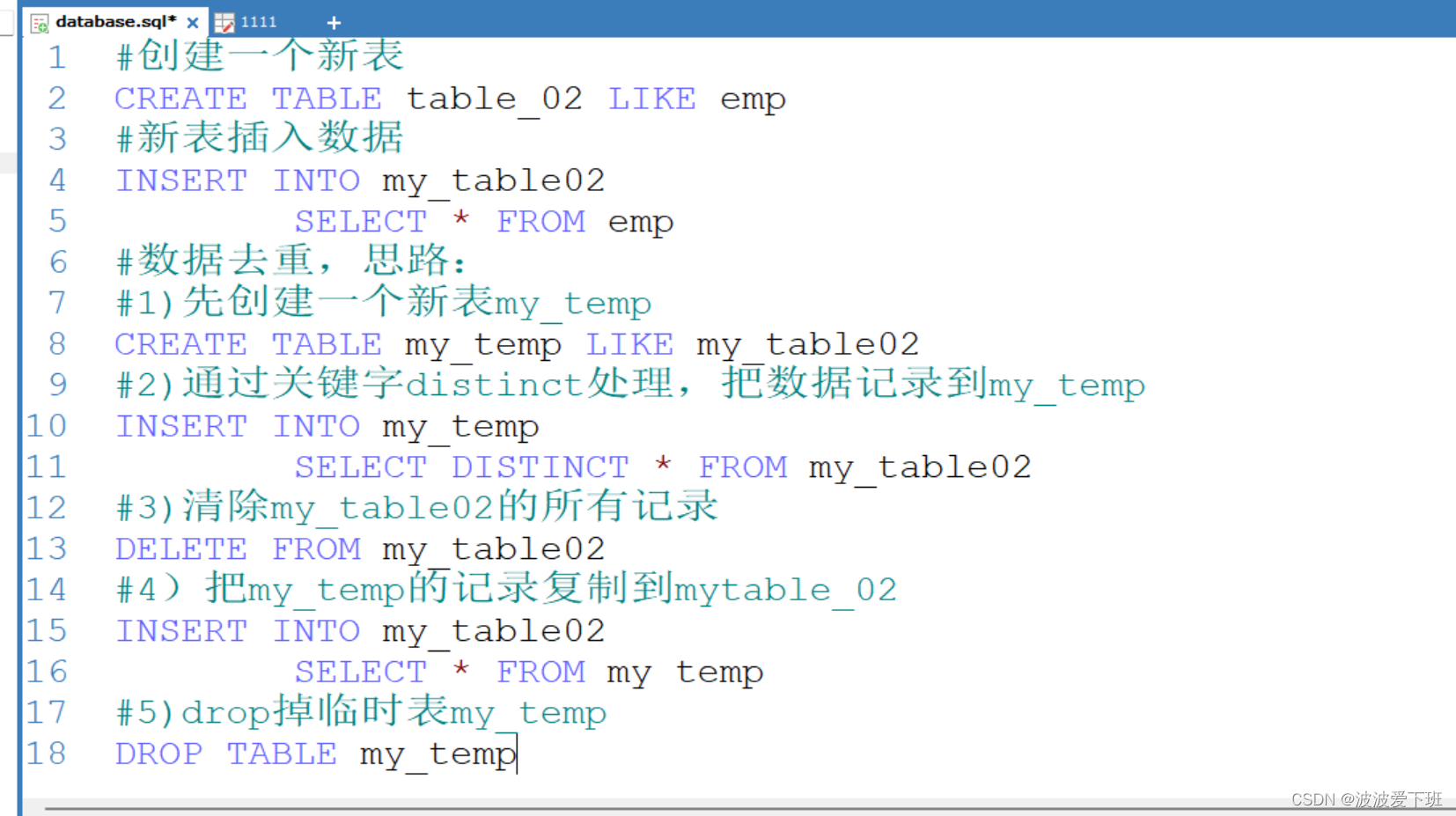
合并查询:union 去重 union all不去重
表的外连接:显示所有人的成绩,如果没有成绩,也要显示姓名和id
左外连接,右外连接
#原来的方式,不会显示没匹配到的
SELECT `name`,stu.id,grade
FROM stu ,exam
WHERE stu.id=exam.id
#改成左外连接
SELECT `name`,stu.id,grade
FROM stu LEFT JOIN exam
ON stu.id=exam.id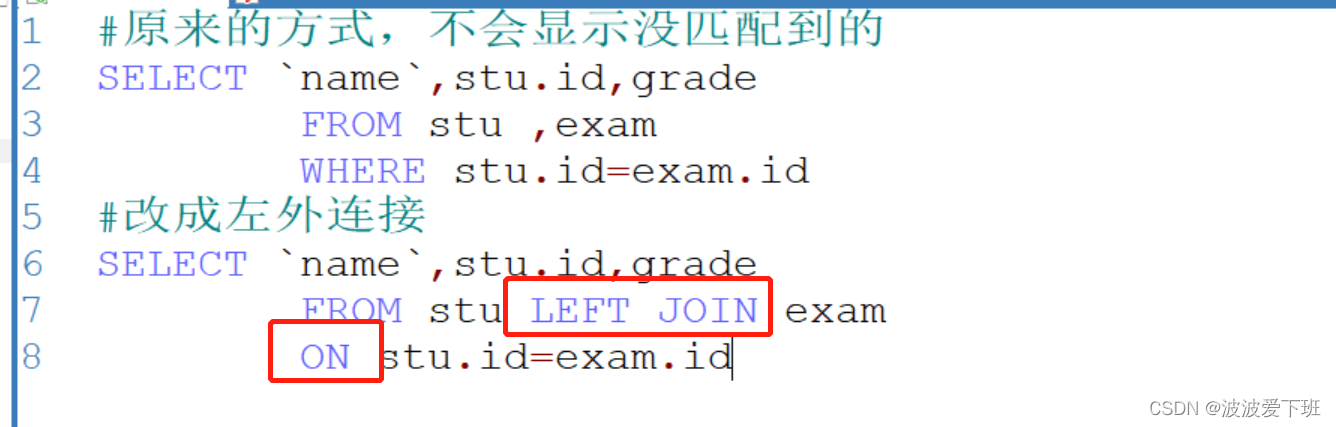
此时,stu就是左表,exam就是右表
mysql约束:主键primary key, 混合主键
定义主键约束后,主键列值不能重复
unique约束,表示该列不可重复
外键约束:FOREIGN KEY 希望某个id(或者别的)必须存在,先创建主表
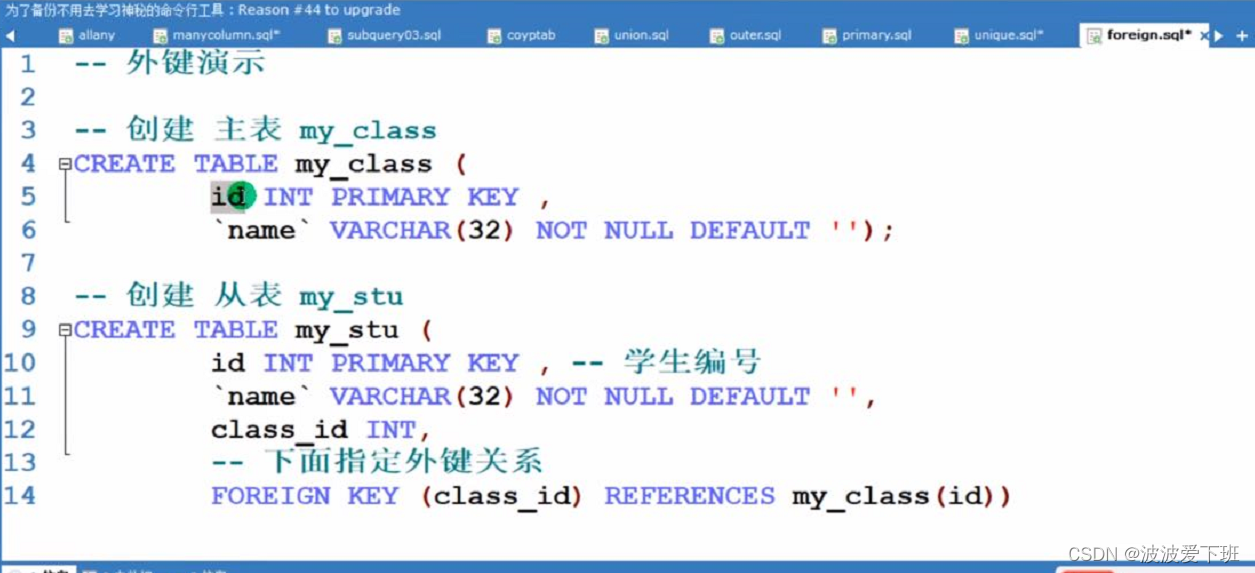
外键注意点:主表必须是主键或者unique,不能随意删除,可否添加空看主键约束,长度可以不一致,表的类型是innodb
自增长:AUTO_INCREMENT
一般搭配主键使用,也可以搭配unique使用,一般用于整型,默认值为1
修改自增长的值:
ALTER TABLE t25 AUTO_INCREMENT = 100索引:体验索引优化,需要的每一列创建一个索引
#创建 索引 索引名 在 哪个表(哪个列)
CREATE INDEX empno_index ON emp(empno)索引本身会占用磁盘空间,创建索引后再次查询。快得飞起
SELECT * FROM emp
WHERE empno=123456创建索引只对创建了的列有效
索引的原理:没有索引时,全表扫描,效率低
有索引时,建立二叉树
索引带来的问题,1空间变大 2不利于数据的修改(数据结构的改变__维护索引)
主键同时也是索引,unique也是索引,普通索引,全文索引(文章里找字段)solr 和 ES
创建索引:添加索引
#创建 索引 索引名 在 哪个表(哪个列)
CREATE INDEX empno_index ON emp(empno)
#添加唯一索引
CREATE UNIQUE INDEX id_index ON t25 (id)
#添加普通索引:
CREATE INDEX id_index ON t25 (id)
#添加普通索引2:
ALTER TABLE t25 ADD INDEX id_index (id)
#添加主键索引:
ALTER TABLE t25 ADD PRIMARY KEY (id)
#删除索引:
DROP INDEX id_index ON t25
#删除主键索引
ALTER TABLE t26 DROP PRIMARY KEY
#修改索引,先删除在添加
#查询索引:
SHOW INDEX FROM t24
SHOW INDEXES FROM t24
SHOW KEYS FROM t24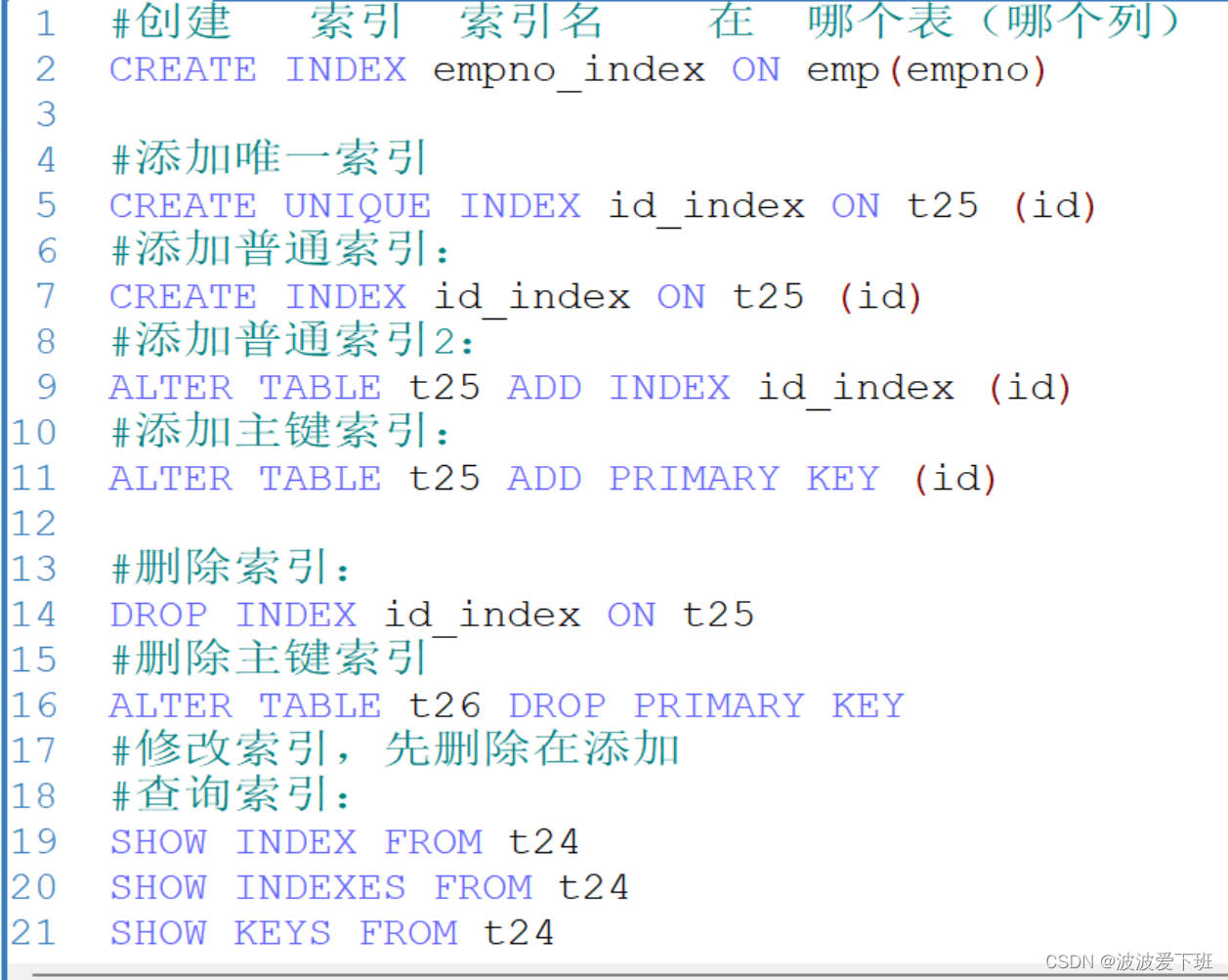
查看某个表是否有索引:
SHOW INDEXES FROM t25哪些适合创建索引:1.重复查询 2.标识符的唯一性
事务:保证数据的唯一性,要么全部是成功,要么全部失败,比如转账
#1.创建表
#2.开始事务
START TRANSACTION
#3.设置保存点
SAVEPOINT a
#4.执行dml操作
INSERT INTO t27 VALUES(100,"tom")
#5.设置保存点
SAVEPOINT b
#6.执行dml操作
INSERT INTO t27 VALUES(101,"tom2")
#7.回退到b保存点
ROLLBACK TO b
#8.回退到a保存点
ROLLBACK TO a
#9.回退到事务开始状态
ROLLBACK
#10.提交事务,一切生效,不在更改
用户密码操作:
#1.创建新的用户
CREATE USER 'hsp_edu' @ 'localhost' IDENTIFIED BY '123456'
#2.删除用户
DROP USER 'hsp_edu' @ 'localhost'
#3.登录
#4.修改密码(自己的) (别人的)
SET PASSWORD=PASSWORD("abcdef")
#(别人的)
SET PASSWORD FOR 'hsp_edu' @ 'localhost' = PASSWORD('123456')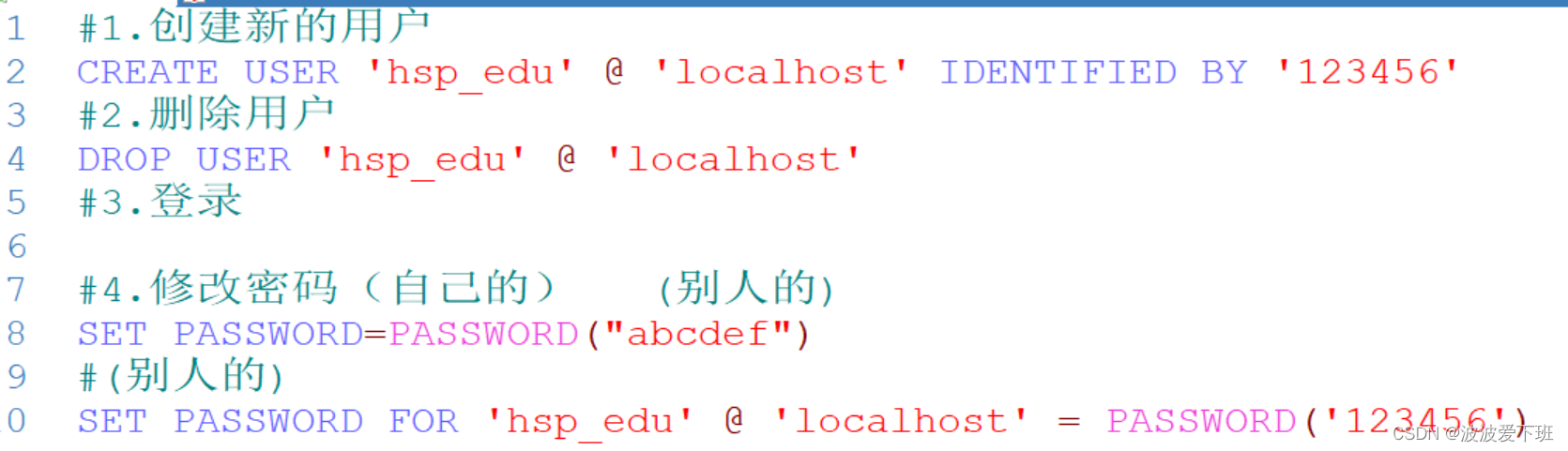


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









