






Multi-attentional Deepfake Detection
介绍
大多数检测为一个普通的二进制分类问题(真/假),首先使用骨干网络提取可疑图像的全局特征,然后将其输入到二元分类器中,以区分真假图像。
将深度假脸检测表述为一种特殊的细粒度分类问题,并提出一种新的多注意力深度假脸检测网络
1)多个空间注意力头部,使网络关注不同的局部信息(真假差异更加微妙和局部,使网络关注不同的潜在伪影区域,通过使用深度语义特征预测多个空间注意力图)
2)纹理特征增强块,用于放大浅层特征中的子纹理瑕疵
3)聚集由注意力图引导的低级纹理特征和高级语义特征作为每个局部部分的表示
4)每个局部部分的特征表示将由双线性注意力汇集层独立汇集,并融合为整个图像的表示
进一步引入了新的区域独立性损失和注意力引导的数据增强策略
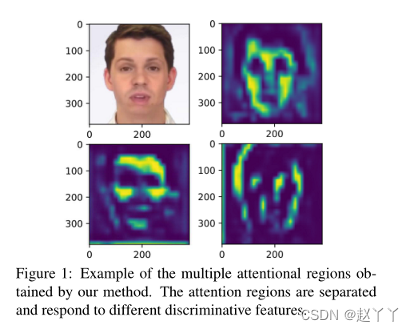
单注意网络可以使用视频水平标签作为显式指导并以监督方式进行训练,多注意网络只能以无监督或弱监督的方式进行训练,通过使用共同的学习策略,多注意力头部将退化为单个注意力对应物,只有一个注意力区域产生强烈的响应,而所有的剩余的注意力区域都被抑制,无法捕获有用的信息,所以进一步提出来一种新的注意力引导的数据增强策略。(模糊一些高反映的注意力区域,迫使从其他注意力区域学习),引入一个新的区域独立损失,鼓励不同关注者关注不同的地方,确保每个注意力图都集中在一个特定区域而不重叠,而且集中区域在不同样本之间是一致的。
Sstnet:通过空间,隐写分析和时间特征来检测被篡改的面孔。 它添加了带有约束卷积和LSTM的简化Xception流
使用双分支表示提取器,使用多尺度拉普拉斯高斯(LoG)算子将颜色域和频率域的信息结合起来。
使用频率感知分解和局部频率统计来暴露频域中的深层伪影
将全局平均池替换为局部注意池(纹理在不同区域之间的变化很大,从不同区域提取的特征通过全局池进行平均,失去可分辨性)
伪造方法导致的轻微伪影倾向于保存在浅层特征的纹理信息中,所以应该关注浅层特征。
方法
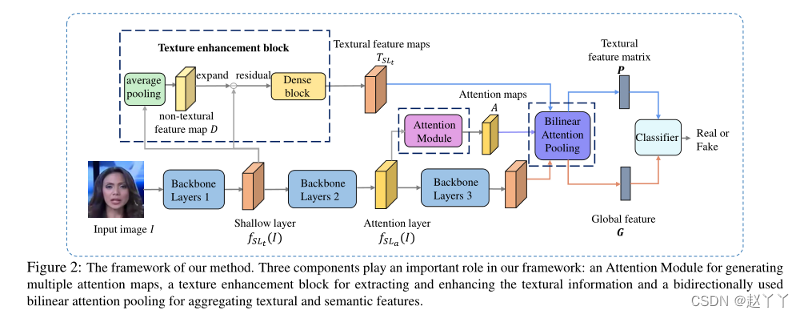
输入面部图像为I,框架的主干网络表示f,从第t层的中间阶段提取的特征图表示为ft(I),大小为Ct×Ht×Wt。
Ct是通道的数量,Ht特征图的高度,Wt特征图的宽度。
注意力模块
用于生成多个注意力图的注意力模块
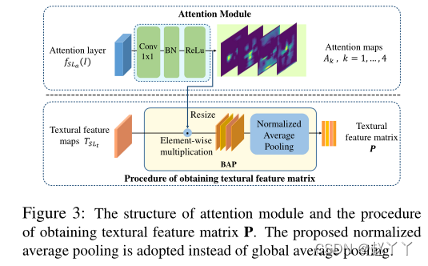
首先使用注意力模块生成多个注意力图,注意力模块是一个轻加权模型,由11卷积层、批归一化层和非线性激活层ReLu组成,从特定层SLa提取的特征图将被送到该模块中,从而获得大小为HtWt的M个注意力图a,Ak表示第k个注意力图,并对应一个特定的区分区域。
纹理增强块
从浅层特征图中用于提取和增强纹理信息的纹理增强块(密集连接的卷积层)
首先使用补丁中的局部平均池对特定层的SLt的特征图进行下采样,并获得池化的特征图D,然后类似于空间图像的纹理表示,定义特征级别的残差表示纹理信息,T包含fslt(I)的大部分纹理信息,然后使用具有三层的密集连接卷积块来增强来增强T,输出纹理特征图。
双线性注意力池
用于聚合纹理和语义特征的双向使用双线性注意力池
对浅层特征图和深层特征图双向使用BAP
为了提取浅纹理特征,首先使用双线性插值将注意力图调整到与纹理特征图相同的比例,然后将纹理特征图F乘以每个注意力图Ak,获得局部纹理特征图Fk,归一化平均池,将归一化的注意力特征Vk堆叠在一起,以获得纹理特征矩阵P,该矩阵被馈送到分类器中
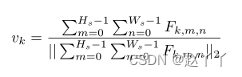
为了提取深层特征,首先拼接每个注意力图以获得单个通道注意力图Asum,然后使用Asum的BAP和来自网络最后一层的特征图来获得全局深度特征G,也被送到分类器中。
区域独立性损失RIL
注意力图正则化的区域独立性损失RIL

没有RIL和AGDA情况下,网络很容易退化,并且多个注意力图定位相同的输入区域,但是我们希望对于不同的输入图像,每个注意力图位于固定的语义区域,例如注意力图A1关注不同图像的眼睛,A2关注嘴巴,这样将减少每个注意力图捕获的信息的随机性。因此提出区域独立性损失,有利于减少注意力图之间的重叠,保持不同输入的一致性
将BAP应用于合并特征图D,以获得语义特征向量V∈RM*N,通过修改中心损失
区域独立性损失定义:LRIL的第一部分是类内损失,将V拉近特征中心c,第二部分是类间损失,排斥分散的特征中心。
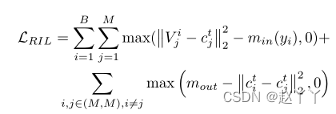
其中B是批量大小,M是关注数量,min表示特征和对应特征中心之间的裕度,并且当yi为0和1时,被设置为不同的值。mout是每个特征中心之间的边距。
c∈RM×N是V的特征中心,其定义如下并在每次迭代中更新:α是特征中心的更新率,我们在每个训练时期之后衰减α。通过计算每个批次中V的梯度来优化c
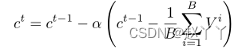
假人脸的纹理比真实人脸更多样,因此限制了邻域中假人脸的部分特征远离真实人脸的特征中心
将区域独立性损失与传统的交叉熵损失相结合:
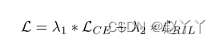
LCE是交叉熵损失,λ1和λ2是这两项的平衡权重。默认情况下,我们在实验中设置λ1=λ2=1。
注意力引导数据增强AGDA
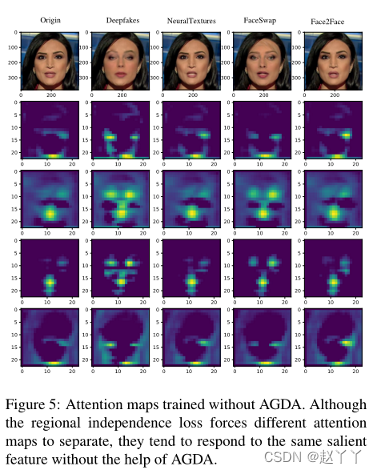
没有AGDA的情况下,注意力区域没有重叠,但是对相同的显著特征做出反应,为了使不同的注意力图聚焦于不同的信息,提出注意力引导数据增强
对于每个训练样本,随机选择一个注意力图Ak来指导数据增强过程,并将其归一化为增强图Ak∈RH×W。然后我们使用高斯模糊来生成退化图像。最后,我们使用Ak作为原始图像和退化图像的权重:
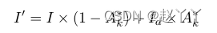
注意力引导的数据增强有助于从两个方面训练模型。第一,它可以向一些区域添加模糊,以确保模型从其他区域学习更鲁棒的特征。第二,可以偶然擦除最显著的辨别区域,这迫使不同的注意力图将其反应集中在不同的目标上。此外,AGDA机制可以防止单个注意力区域过度扩展,并鼓励注意力块探索各种注意力区域划分形式。
实验
首先使用最先进的面部提取器RetinaFace检测面部,将对齐的面部图像保存为380*380大小的输入
设置了超参数α=0.05,每次迭代后衰减0.9。类间边距mout被设置为0.2。对于真实图像和伪图像,类内边距min分别设置为0.05和0.1。
在AGDA中,我们将调整大小因子设置为0.3,高斯模糊σ=7。我们的模型使用Adam优化器进行训练,学习率为0.001,体重衰减为1e6。我们在批量大小为48的4RTX 2080Ti GPU上训练我们的模型。
采用EfficientNet-b4作为多注意框架的主干网络。EfficientNet-b4能够在只有一半FLOP的情况下实现与XceptionNet相当的性能。总共有7层,用L1~L7表示。通过实验选择了SLa和SLt的数量。
注意:细微的伪影倾向于由网络浅层的纹理特征保留,因此选择L2和L3作为SLt的候选,而注意力图关注输入的不同区域,这在某种程度上需要高级语义信息的指导,因此,我们使用更深层的L4和L5作为SLa的候选。
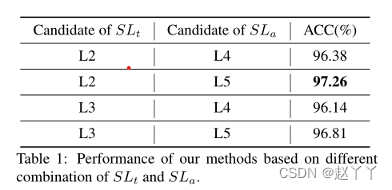
默认设置M=1,我们在FF++(HQ)上训练具有四种组合的模型。从表1的结果中,我们发现当使用L2作为SLt和L5作为SLa时,该模型达到了最佳性能。
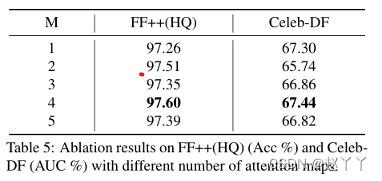
通过实验选择了注意图M的数量。
在不同的数据集上对比
FF++
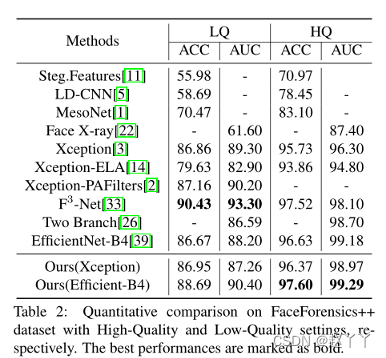
FF++(LQ)中的视频被高度压缩,并导致纹理信息的显著损失,这对我们的纹理增强设计是一个灾难。框架对高压缩率敏感
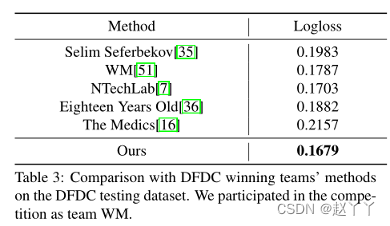
DFDC
Celeb DF
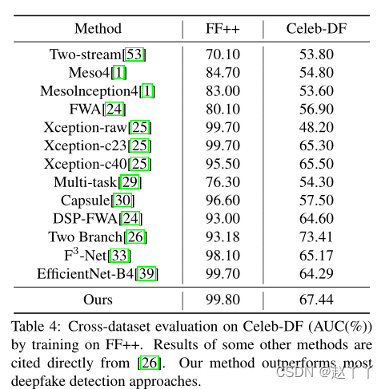
框架的可移植性,在FF++(HQ)上进行训练,在Celeb DF上进行了测试,对每个视频采样30帧计算AUC
消融研究
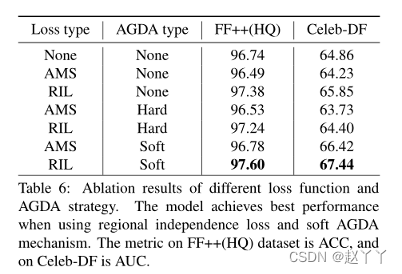
软注意力下降,模糊原始图像以降低所选输入区域的质量
硬注意力下降,以二进制方式直接擦除所选区域的像素,如果增强图大于阈值就使其为0,注意力下降阈值θd=0.5
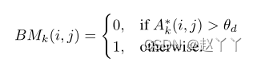
硬注意力:0/1问题,哪些区域被关注,哪些区域不关注
软注意力:[0,1]间连续分布问题,每个区域被关注的程度高低,用0~1的score表示
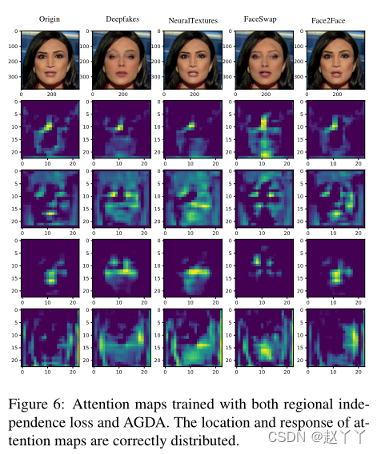
使用RIL和AGDA训练的注意力图,位置和响应是正确分布的。

















 2374
2374

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









