






介绍
贡献:1、一个由1000个视频中的180多万张图像组成的操纵面部图像的新型大规模数据集,具有原始(即真实)来源和目标地面真相,以实现监督学习
2、一种适合面部操作的最先进的伪造检测方法。
3、对各种场景中最先进的手工制作和学习伪造检测器进行了广泛评估
4、用于在随机压缩下进行面部操作检测的自动基准,用于标准化比较,包括人类基线
大规模人脸伪造数据库
两种基于计算机图形的方法(Face2Face和FaceSwap)和两种基于学习的方法(DeepFakes和NeuralTextures)。所有四种方法都需要源和目标演员视频对作为输入。每个方法的最终输出是由生成的图像组成的视频。除了操纵输出,我们还计算指示像素是否已被修改的地面真值掩码,这可用于训练伪造定位方法
FaceSwap是一种基于图形的方法,用于将面部区域从源视频传输到目标视频。基于稀疏检测到的面部标志,提取面部区域。使用这些界标,该方法使用混合形状拟合3D模板模型。通过使用输入图像的纹理最小化投影形状和局部界标之间的差异,将该模型反向投影到目标图像。最后,将渲染模型与图像混合,并应用颜色校正。我们对所有成对的源帧和目标帧执行这些步骤,直到一个视频结束。
DeepFakes该方法基于两个具有共享编码器的自动编码器,这些编码器被训练为分别重建源面部和目标面部的训练图像。人脸检测器用于裁剪和对齐图像。为了创建假图像,将源人脸的训练编码器和解码器应用于目标人脸。然后使用泊松图像编辑将自动编码器输出与图像的其余部分混合。本文通过用完全自动化的数据加载器替换手动训练数据选择来稍微修改实现。
Face2Face是一种面部重演系统,它将源视频的表情转移到目标视频,同时保持目标人物的身份。
最初的实现基于两个视频输入流,并手动选择关键帧,这些帧用于生成人脸的密集重建,可以用于在不同的照明和表情下重新合成人脸。
对于本文,在预处理过程中处理每个视频,使用第一帧获得临时面部身份(即3D模型),并跟踪剩余帧上的表情,我们自动选择具有面部最左侧和最右侧角度的帧。基于这种身份重建,我们跟踪整个视频以计算每帧的表达式、刚性姿势和照明参数。我们通过将每个帧的源表达式参数(即76个混合形状系数)传输到目标视频来生成再现视频输出
NeuralTextures应用了Pix2Pix中使用的基于补丁的GAN损失。NeuralTextures方法依赖于训练和测试期间使用的跟踪几何体。使用Face2Face的跟踪模块来生成这些信息。我们只修改与嘴部区域相对应的面部表情,即眼睛区域保持不变(否则渲染网络将需要类似于深度视频肖像的眼睛运动的条件输入)
后期处理-视频质量:使用H.264编解码器压缩视频,为了生成高质量的视频,我们使用由HQ表示的光压缩(恒定速率量化参数等于23),这在视觉上几乎是无损的。使用40的量化来产生低质量视频(LQ)。
伪造检测
将数据集分成固定的训练、验证和测试集,分别由720、140和140个视频组成。
人类检测
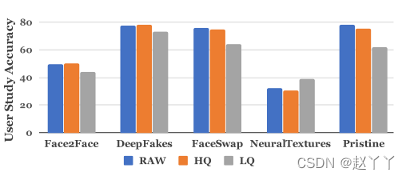
RAW原始、HQ高质量、LQ低质量、Pristine未受损的
自动伪造检测

输入图像由面部跟踪方法处理,提取被面部覆盖的图像区域,该区域被馈送到输出预测的学习分类网络中。
使用保守裁剪(放大了1.3倍)围绕跟踪面的中心,包围重建的面。
(1)基于隐写分析特征的检测
该方法采用了手工特征,这些特征在高通图像上沿水平和垂直方向的4个像素图案上共出现,总特征长度为162。然后使用这些特征来训练线性支持向量机(SVM)分类器。
提供了一个128×128的中心裁剪作为该方法的输入,虽然手工制作的方法在原始图像上大大优于人类的准确性,但它难以应对压缩,这导致低质量视频的准确性低于人类的表现。
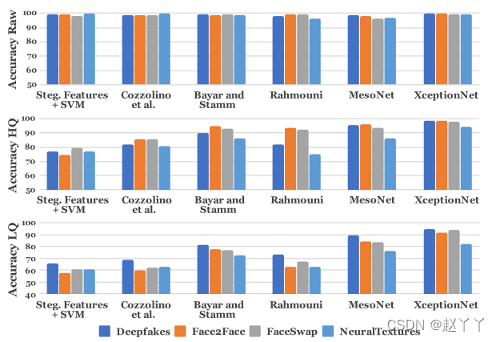
使用在所有四种操作方法和不同视频质量级别上分别评估的所有网络架构的二进制伪造检测任务的结果。
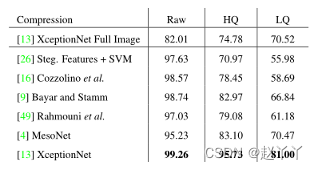
除了full image XceptionNet,所有方法都是在跟踪人脸中心周围的保守裁剪(放大1.3倍)上训练的。
XceptionNet能够在弱压缩上获得令人信服的结果,同时在低质量图像上仍然保持合理的性能,因为它得益于在ImageNet上的预训练以及更大的网络容量。
(2)基于学习特征的检测
1)Cozzolino等[16]将前一节的手工隐写分析特征转换为基于cnn的网络。我们在我们的大规模数据集上微调这个网络。
2)训练卷积神经网络,该网络使用约束卷积层,然后是两个卷积、两个最大池和三个完全连接层,约束卷积层是为了抑制图像的高级内容,使用居中的128×128裁剪作为输入
3)Rahmouni等[49]采用了不同的CNN架构,其全局池化层计算四种统计量(均值、方差、最大值和最小值)。我们认为Stats-2L网络的性能最好。
4)MesoInception-4是一个基于CNN的网络,灵感来自InceptionNet,用于检测视频中的人脸篡改。该网络具有两个初始模块和两个与最大池层交错的经典卷积层。然后,有两个完全连接的层。相比于经典的交叉熵损失,提出了真实标签和预测标签之间的均方误差。将面部图像的大小调整为256×256
5)XceptionNet是一种传统的CNN,基于具有残余连接的可分离卷积在ImageNet上训练。通过用两个输出替换最终的完全连接层,我们将其转移到任务中。其他层使用ImageNet权重初始化。为了建立新插入的完全连接层,我们将所有权重固定到最终层,并对网络进行3个时期的预训练。在这一步骤之后,我们再训练15个时间段的网络,并基于验证精度选择性能最佳的模型。
(3)基于GAN方法的伪造检测
NeuralTextures正在为每个操作训练一个独特的模型,这将导致可能的伪影的更高变化。虽然DeepFakes也在为每个操作训练一个模型,但它使用了固定的后处理管道,与基于计算机的操作方法类似,因此具有一致的伪影。
训练语料库大小评估:
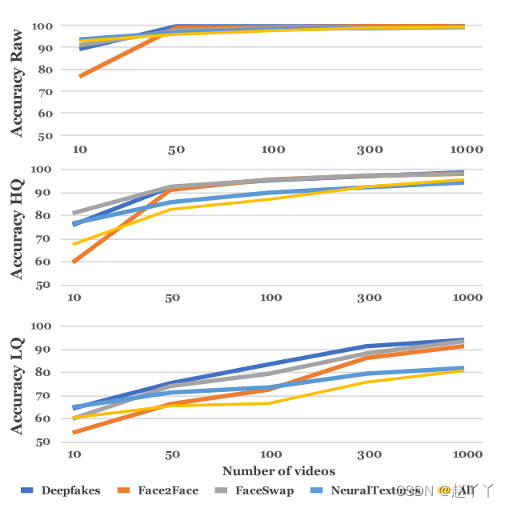
在所有三个视频质量级别上分别使用不同的训练语料库大小来训练XceptionNet分类器。
整体性能随着训练图像的数量而增加,这对于低质量视频片段尤为重要。
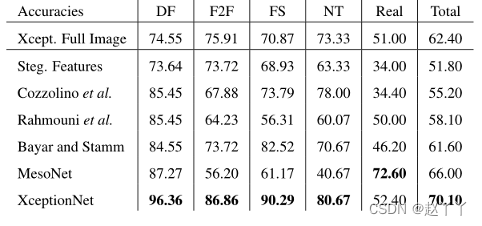
每种检测方法的低质量训练模型的结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









