







Networks as Feature Extractors
我们将讨论迁移学习的概念,即使用预先训练的模型作为“捷径”,从最初没有训练过的数据中学习模式的能力。
- 什么是Transfer learning: 使用现有的预训练分类器,作为新的分类任务的起始点。
原理:深度神经网络在大规模的数据集上进行训练,这种网络结构学习到的大量的具有判别性的特征能够识别1000种独立的对象类,使得其特征过滤器可以重复应用于除原始训练任务以外的分类任务 - 计算机视觉领域深度学习常见的两种迁移学习
- 训练网络结构成为任意的特征提取器
- 将原有网络结构的FC层移除,替换新的FC层,通过**微调权重(后面会讲到)**识别新的目标类
- 使用预训练的CNN提取特征(端到端):可以在任意层终止向前传播,然后使用当前层的特征向量,针对这些特征向量,我们可以训练现成的机器学习模型,比如SVM ,Logistic Regression ,Random Forest获得一个能够识别新类图像的分类器
- HDF5: 由hdf5组创建的二进制数据格式用于存储磁盘上巨大的数字数据集,同时便于对数据集进行访问和获取。HDF5中的数据采用分层存储,类似于文件系统存储数据的方式。数据首先在组(类似于一个容器结构,可以保存数据和其他组)中的定义

Figure 3.2: An example of a HDF5 file with three datasets. The first dataset contains the
label_names for CALTECH-101. We then have labels, which maps the each image to its
corresponding class label. Finally, the features dataset contains the image quantifications extracted
by the CNN. - 如何根据原始图像生成HDF5数据集

Understanding rank-1 & rank-5 Accuracies

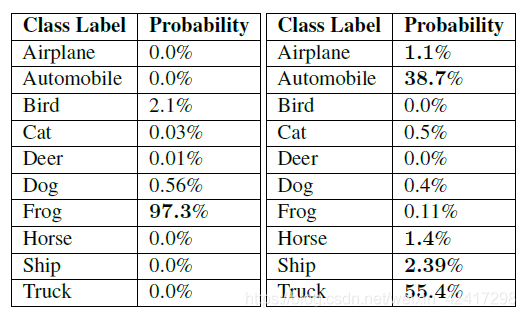
rank-1 accuracy:
rank-5 accuracy:
Fine-tuning Networks :a type of transfer learning
微调是 transfer learning 的一种
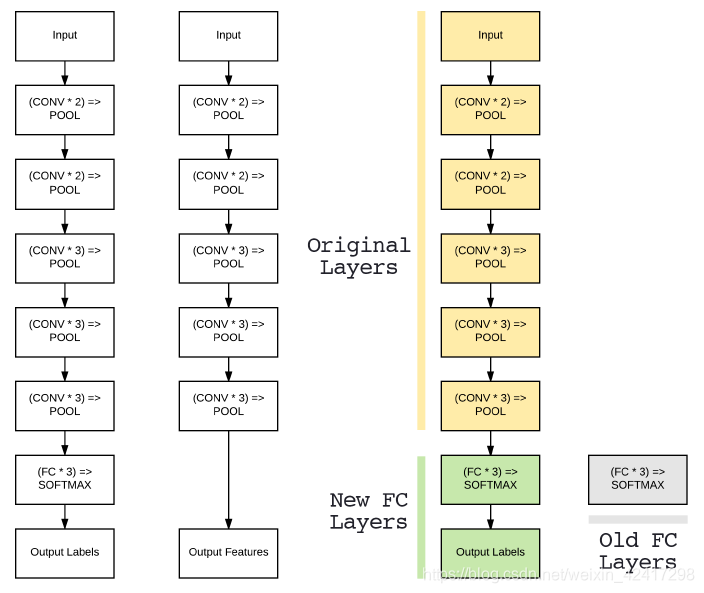
以VGG16为例子,当开始微调时,将原VGG16结构中的全连接层移除,此时最后一层的池化层作为新的特征提取器,新的FC层可以微调到特定的数据集
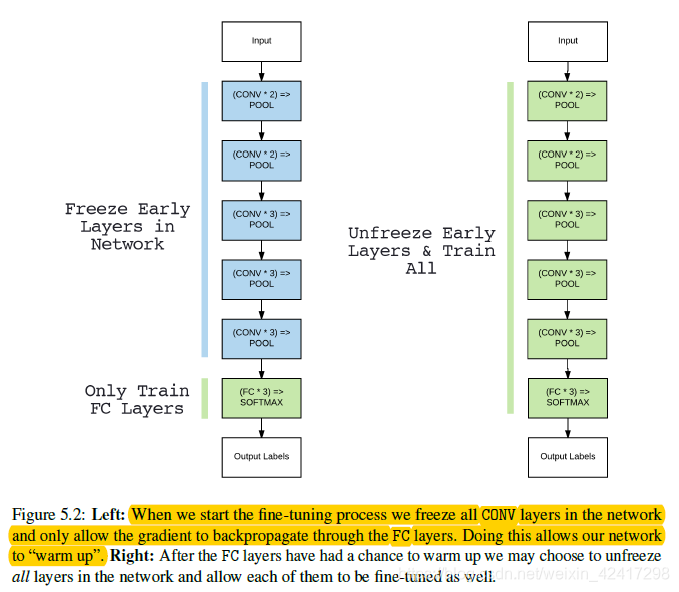
当开始微调时,对原网络结构的卷积层进行冷冻,并且只允许BP执行到FC层,在新的FC层训练后,再对CONV进行解冻,允许所有的layers进行微调
Python代码
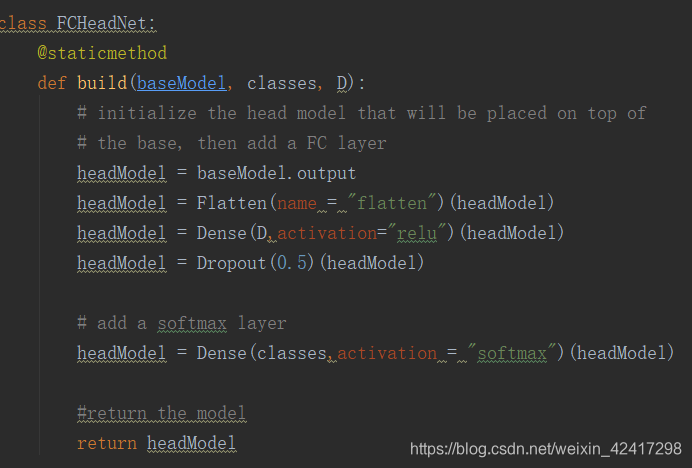
对新增FC层,作为headModel的构造以替换原来的VGG16中的FC部分
Improving Accuracy with Network Ensembles (网络集成)##
集成学习:将多个分类器集合成一个大的元分类器,本章集成方法主要依赖詹森不等式
内容:如何从一个脚本训练多个CNNs,然后将这些CNNS合并成一个单一的元分类器,并且提高其精度
- Ensemble Methods: AdaBoost & Random Forests
- Random Forests:
Each decision tree “votes” on what it thinks the final classification should
be.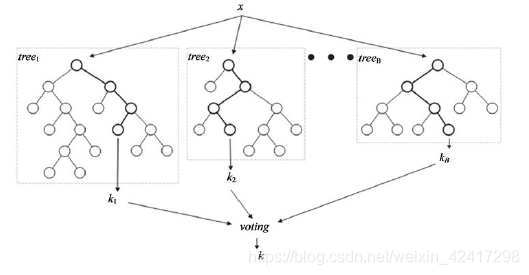
- 对CNN的应用:train multiple networks and ask each network to return the probabilities for each class label given an input data point
- Jensen’s Inequality: 用来说明为什么集成方法能够更好地获得较高的准确率——Jensen 's的形式定义
不等式表明凸组合(平均)集成的误差小于或等于单个模型的平均误差
深度学习模型的集成学习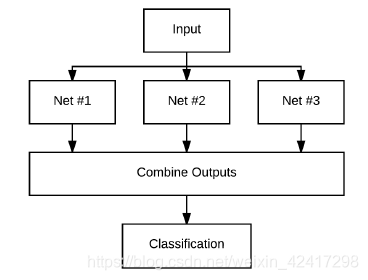
Advanced Optimization Methods
-
Adagrad
 cache: 该变量维护每一个参数的梯度平方和并且在训练过程中每一个小批次进行更新;通过检测cache我们可以判断哪个参数更新的频繁哪个不频繁
cache: 该变量维护每一个参数的梯度平方和并且在训练过程中每一个小批次进行更新;通过检测cache我们可以判断哪个参数更新的频繁哪个不频繁
divide the lr * dx by the square-root of the cache (adding in an epsilon value
for smoothing and preventing division by zero errors
更新较快的权重/缓存冲较大的梯度值能过减小更新的规模从而有效的降低参数的学习率;相反,更新不频繁的权重/缓存中较小的梯度值能够有效的提高参数的学习率优点不再需要手动微调学习率(初始学习率设置为0.01)
缺点分母位置梯度累计(平方值累计),这种累计在训练过程中持续增长 -
Adadelta:Adagrad的一个扩展——降低由缓存引起的单调下降的学习率
In the Adagrad algorithm, we update our cache with all of the previously squared gradients.
However, Adadelta restricts this cache update by only accumulating a small number of past gradients
– when actually implemented, this operation amounts to computing a decaying average of all past
squared gradients.(缓存更新只涉及当前计算批次的梯度的平方) -
RMSprop:converting the cache into an exponentially weighted moving average
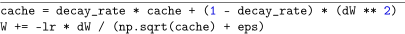 之前
之前 -
Adam
-
Nadam
Optimal Pathway to Apply Deep Learning
回顾训练神经网络的必要组成包括:
dataset; loss function ; neural network architecture; optimization method
深度学习模型训练的关键点:检查你的准确率/损失曲线
- 通常来说,我们很难保证我们的训练集能能够有效的代替测试集和验证集。

左图为实际我们想要识别的图(验证集/测试集)
有图表示我们的神经网络通常训练的图(训练集)
**注意:**如果希望深度学习模型获得一个较高的准确率,需要保证训练的图片能够代表你所需要识别的内容,
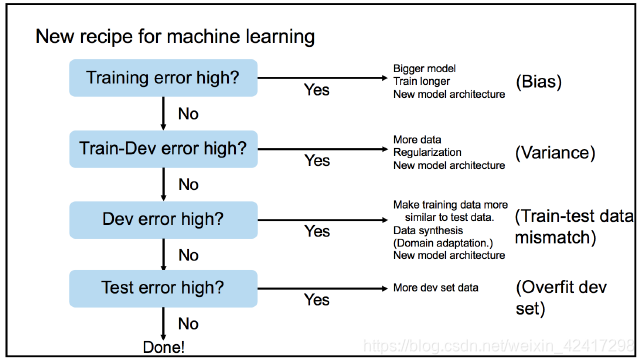
four step process to aid us in our training
training a deep learning model : - Training : determine the bias of our model
- Training-validation: determine variance
- Validation:
- Testing
training: 确定模型的偏差?
Training-validation: 确定方差?
针对于不同的误差情况,可以分为以下方式进行解决:
-
如果训练误差很高,此时考虑加深我们当前的结构,通过增加一些层和神经元;考虑训练更长时间,适当的调整学习速度——使用较小的学习率能够让你训练的更长,并且避免过拟合。
-
如果训练-验证集误差很高,此时检查网络中的正则化参数。我们是否在网络结构中添加了丢包层?是否使用数据扩展技术产生的新的训练样例?实际的损失/更新函数本身?在你自己的深度学习模型中检查这些问题,并添加相应的正则化
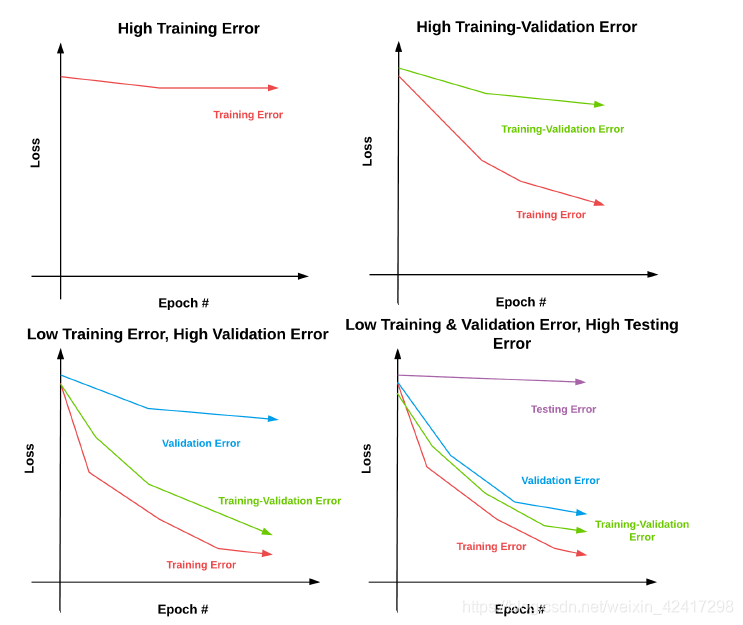
左上:训练误差很高,暗示我们需要一个更好的模型去代表数据中的底层模式
右上:训练误差降低,但是训练-验证误差很高。这暗示,我们需要获得更多的数据或者添加一下更强的正则项
左下:如果训练和训练-验证的误差都很低,但是验证集的误差很高,需要检查训练数据,确保他能够很好的模拟验证和测试集
右下:如果,训练,训练验证和验证集误差都很低,但是测试误差很高,我们需要收集更多的训练-验证数据(此时发生过拟合,需要收集更多验证集去判断什么时候发生过拟合)2. Transfer Learning or Train from Scratch(转移模型或是从零开始训练)
two import factors:- size of your dataset
- similarity of your dataset to the dataset the pre-trained CNN was trained on

数据集比较小或者和原始数据集相似
你的数据集很大且和原始数据集相似
数据集很小并且和原始数据集不同
数据集很大并且和原始数据集不同
Working with HDF5 and Large Datasets
目前为止我们所使用的的数据集,都是能够装入我们机器主内存中的数据集。对于一些小型数据集来说,这是一种合理的假设。但对于大型数据集,我们需要创建数据生成器:用来每次访问数据集的一部分——这种方法很低效,会有延迟
在本章有效的方法是针对原始图像产生一个HDF5数据集,我们存储的是图像本身,而不是提取的特征。HDF5不仅能够存储大量数据集,而且还针对I/O操作进行了优化,特别是针对从文件中提取批(称为“片”)。采取额外的步骤将驻留在磁盘上的原始图像打包到HDF5文件中,这允许我们构建一个深度学习框架,该框架可用于快速构建数据集并在其上训练深度学习网络
几种额外的图像预处理程序
1: 平均减值预处理:从输入图像中减去数据集上的整个红、绿
蓝像素强度
2:Patch预处理:在训练中随机提取图像的M*N像素区域
3:过采样预处理程序:在测试中对输入图像的五个区域进行采样(四个角和中心区域)以及它们相应的翻转,总共10个裁剪区域
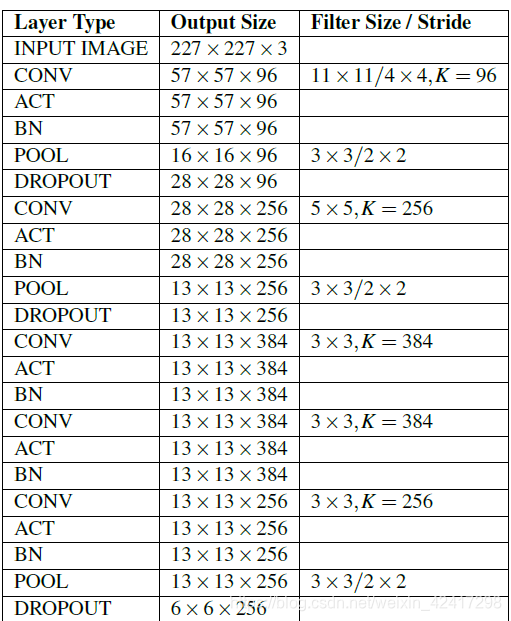
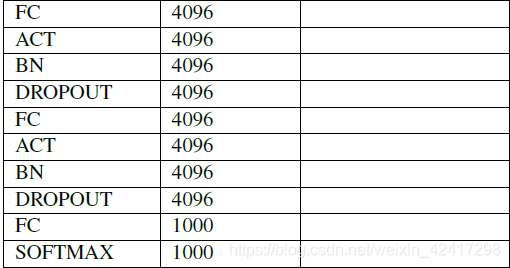
AlexNet
output_size =1+ (input_size+2*padding-kernel_size)/stride
GoogleNet
micro-architectures: network in network modules, build blocks in context of the overall macro-architecture
Inception Module:


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









