







 本文详细介绍了Kafka的核心概念和机制,包括Kafka的体系架构、消息发送机制、副本机制、控制器功能以及消费端的Rebalance机制。Kafka作为一个分布式消息引擎,提供高吞吐、低延迟、持久化存储和分布式可扩展性。通过异步发送、批量发送和重试机制,确保高效的消息传递。副本机制保证了数据的可靠性和可用性,而控制器则负责集群管理和协调。消费端的Rebalance机制确保了消费组内消息的均衡消费。了解这些核心原理,有助于深入理解和应用Kafka。
本文详细介绍了Kafka的核心概念和机制,包括Kafka的体系架构、消息发送机制、副本机制、控制器功能以及消费端的Rebalance机制。Kafka作为一个分布式消息引擎,提供高吞吐、低延迟、持久化存储和分布式可扩展性。通过异步发送、批量发送和重试机制,确保高效的消息传递。副本机制保证了数据的可靠性和可用性,而控制器则负责集群管理和协调。消费端的Rebalance机制确保了消费组内消息的均衡消费。了解这些核心原理,有助于深入理解和应用Kafka。
Kafka 是目前主流的分布式消息引擎及流处理平台,经常用做企业的消息总线、实时数据管道,本文挑选了 Kafka 的几个核心话题,帮助大家快速掌握 Kafka,包括:
Kafka 体系架构
Kafka 消息发送机制
Kafka 副本机制
Kafka 控制器
Kafka Rebalance 机制
因为涉及内容较多,本文尽量做到深入浅出,全面的介绍 Kafka 原理及核心组件,不怕你不懂 Kafka。
1. Kafka 快速入门
Kafka 是一个分布式消息引擎与流处理平台,经常用做企业的消息总线、实时数据管道,有的还把它当做存储系统来使用。早期 Kafka 的定位是一个高吞吐的分布式消息系统,目前则演变成了一个成熟的分布式消息引擎,以及流处理平台。
1.1 Kafka 体系架构
Kafka 的设计遵循生产者消费者模式,生产者发送消息到 broker 中某一个 topic 的具体分区里,消费者从一个或多个分区中拉取数据进行消费。拓扑图如下:
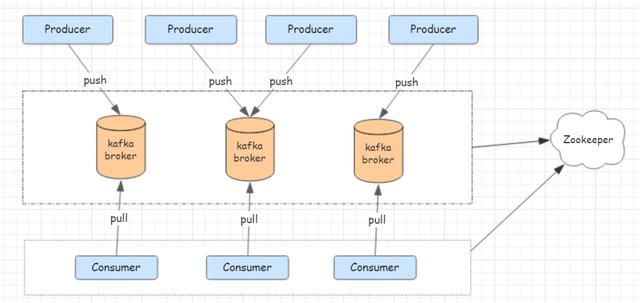
目前,Kafka 依靠 Zookeeper 做分布式协调服务,负责存储和管理 Kafka 集群中的元数据信息,包括集群中的 broker 信息、topic 信息、topic 的分区与副本信息等。
1.2 Kafka 术语
这里整理了 Kafka 的一些关键术语:
Producer:生产者,消息产生和发送端。
Broker:Kafka 实例,多个 broker 组成一个 Kafka 集群,通常一台机器部署一个 Kafka 实例,一个实例挂了不影响其他实例。
Consumer:消费者,拉取消息进行消费。 一个 topic 可以让若干个消费者进行消费,若干个消费者组成一个 Consumer Group 即消费组,一条消息只能被消费组中一个 Consumer 消费。
Topic:主题,服务端消息的逻辑存储单元。一个 topic 通常包含若干个 Partition 分区。
Partition:topic 的分区,分布式存储在各个 broker 中, 实现发布与订阅的负载均衡。若干个分区可以被若干个 Consumer 同时消费,达到消费者高吞吐量。一个分区拥有多个副本(Replica),这是Kafka在可靠性和可用性方面的设计,后面会重点介绍。
message:消息,或称日志消息,是 Kafka 服务端实际存储的数据,每一条消息都由一个 key、一个 value 以及消息时间戳 timestamp 组成。
offset:偏移量,分区中的消息位置,由 Kafka 自身维护,Consumer 消费时也要保存一份 offset 以维护消费过的消息位置。
1.3 Kafka 作用与特点
Kafka 主要起到削峰填谷(缓冲)、系统解构以及冗余的作用,主要特点有:
高吞吐、低延时:这是 Kafka 显著的特点,Kafka 能够达到百万级的消息吞吐量,延迟可达毫秒级;
持久化存储:Kafka 的消息最终持久化保存在磁盘之上,提供了顺序读写以保证性能,并且通过 Kafka 的副本机制提高了数据可靠性。
分布式可扩展:Kafka 的数据是分布式存储在不同 broker 节点的,以 topic 组织数据并且按 partition 进行分布式存储,整体的扩展性都非常好。
高容错性:集群中任意一个 broker 节点宕机,Kafka 仍能对外提供服务。
2. Kafka 消息发送机制
Kafka 生产端发送消息的机制非常重要,这也是 Kafka 高吞吐的基础,生产端的基本流程如下图所示:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









