







先了解下JUC
java.util.concurrent(简称JUC)包,在此包中增加了在并发编程中很常用的工具类,
用于定义类似于线程的自定义子系统,包括线程池,异步 IO 和轻量级任务框架;还提供了设计用于多线程上下文中的 Collection 实现等;
再了解下volatile 关键字
volatile 关键字: 当多个线程进行操作共享数据时,可以保证内存中的数据是可见的;相较于 synchronized 是一种较为轻量级的同步策略;
- volatile 不具备"互斥性";
- volatile 不能保证变量的"原子性";
1. ArrayList
底层实现是数组,元素为Object,java 8对其初始化和扩容有了新的变化,移步【java 8】ArrayList的初始容量以及扩容测试
线程不安全
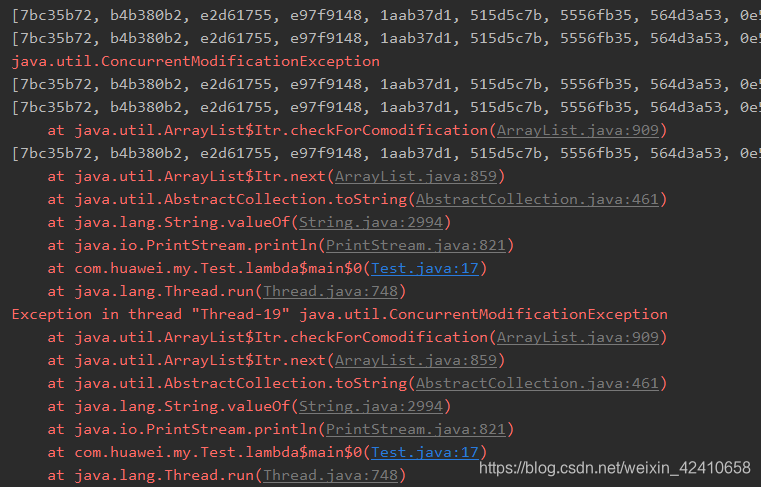
演示并发修改异常 ConcurrentModificationException
public class Test {
public static void main(String[] args) throws Exception {
List<Object> list = new ArrayList<>();
for (int i = 0; i < 20; i++) {
new Thread(() -> {
list.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(list);
}, "Thread-" + i).start();
}
}
}
运行结果:
解决方案一:Vector(不让用)
更改程序:
List<Object> list = new Vector<>();
运行结果:解决了并发修改异常
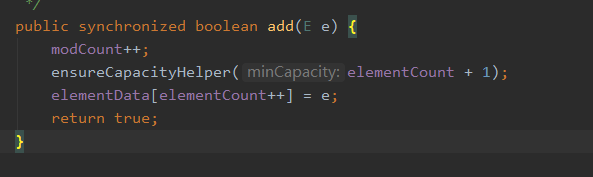
查看源码:增删改操作都使用同步方法,效率低。
解决方案二:使用集合工具类提供的线程安全包装(也不让使用)
List<Object> list = Collections.synchronizedList(new ArrayList<>());
源码:还是加同步锁,效率低。

解决方案三:JUC写时复制技术
List<Object> list = new CopyOnWriteArrayList<Object>();
源码:
内部持有一个锁:ReentrantLock lock = new ReentrantLock(); 增删改操作时,先将数据创建一个副本后对其修改。读操作还是访问原来的数据,不会产生影响,等修改操作完成后list引用指向副本(原数据变为垃圾交给gc)。读写分离,提高了效率。
// 注意这个volatile关键字,请自行百度一下
private transient volatile Object[] array;
// 底层还是Object数组
public CopyOnWriteArrayList() {
setArray(new Object[0]);
}
final void setArray(Object[] a) {
array = a;
}
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1);
newElements[len] = e;
setArray(newElements);
return true;
} finally {
lock.unlock();
}
}
2. HashSet
知识点补充:HashSet底层使用的是HashMap结构,元素存入HashMap的key中,HashMap的value是一个常量(new Object())
源码如下:
public HashSet() {
map = new HashMap<>();
}
// Dummy value to associate with an Object in the backing Map
private static final Object PRESENT = new Object();
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
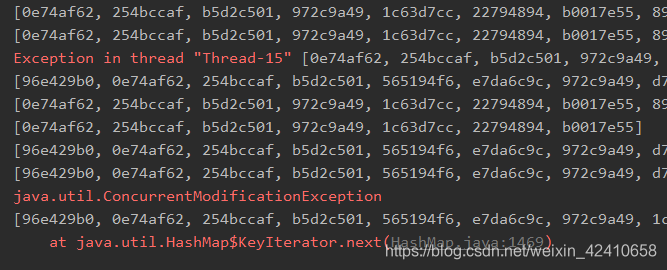
同样有并发安全问题,如ConcurrentModificationException,测试代码如下:
public class Test {
public static void main(String[] args) throws Exception {
Set<Object> set = new HashSet<Object>();
for (int i = 0; i < 20; i++) {
new Thread(() -> {
set.add(UUID.randomUUID().toString().substring(0, 8));
System.out.println(set);
}, "Thread-" + i).start();
}
}
}
运行结果:并发修改异常
解决方案一:使用集合工具类提供的线程安全包装(不让使用)
Set<Object> set = Collections.synchronizedSet(new HashSet<>());
解决方案二:JUC,写时复制
Set<Object> set = new CopyOnWriteArraySet<>();
// 底层借助 CopyOnWriteArrayList
public CopyOnWriteArraySet() {
al = new CopyOnWriteArrayList<E>();
}
解决方案三
Set<Object> set = new ConcurrentSkipListSet<>();
// 底层借助 ConcurrentSkipListSet
public ConcurrentSkipListSet() {
m = new ConcurrentSkipListMap<E,Object>();
}
3. HashMap
知识点补充:重新认识HashMap(jdk1.8新增特性)
HashMap?ConcurrentHashMap?相信看完这篇没人能难住你!
Java的ConcurrentHashMap
HashMap同样不是线程安全的
public class Test {
public static void main(String[] args) throws Exception {
Map<Object, Object> map = new HashMap<>();
for (int i = 0; i < 20; i++) {
new Thread(() -> {
String substring = UUID.randomUUID().toString().substring(0, 8);
map.put(substring, substring);
System.out.println(map);
}, "Thread-" + i).start();
}
}
}
运行结果:
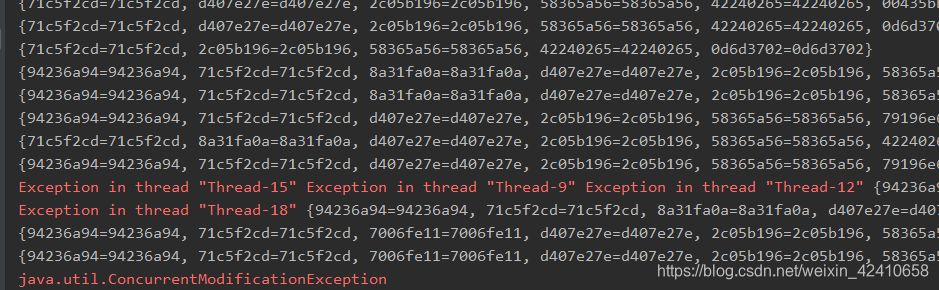
解决方案一:Map<Object, Object> map = new Hashtable<>(); (不让用)
修改方法都加同步锁
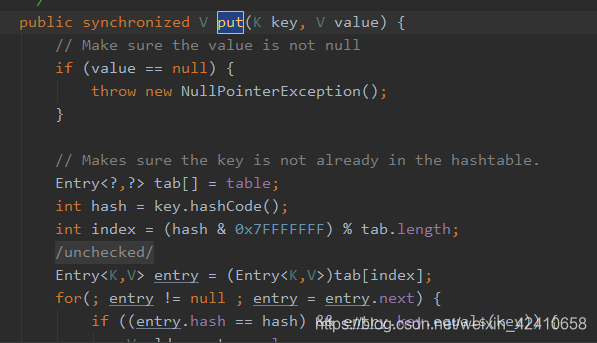
解决方案二:Map<Object, Object> map = Collections.synchronizedMap(new HashMap<>()); (不让用)
加同步代码块

解决方案三:JUC, ConcurrentHashMap (推荐)
Map<Object, Object> map = new ConcurrentHashMap<>();
java 8抛弃了java 7原有的 Segment 分段锁,采用了 CAS + synchronized 来保证并发安全性。
ConcurrentHashMap总结
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode());
int binCount = 0;
for (Node<K,V>[] tab = table;;) { // 根据 key 计算出 hashcode 。
Node<K,V> f; int n, i, fh;
if (tab == null || (n = tab.length) == 0) //判断是否需要进行初始化。
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// f 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED) // 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
tab = helpTransfer(tab, f);
else {
V oldVal = null;
synchronized (f) { // 如果都不满足,则利用 synchronized 锁写入数据。
if (tabAt(tab, i) == f) {
if (fh >= 0) {
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) {
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {
Node<K,V> p;
binCount = 2;
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) { // 如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);
return null;
}
搬运过来一段概述
1、判断Node[]数组是否初始化,没有则进行初始化操作
2、通过hash定位数组的索引坐标,是否有Node节点,如果没有则使用CAS进行添加(链表的头节点),添加失败则进入下次循环。
3、检查到内部正在扩容,就帮助它一块扩容。
4、如果f!=null,则使用synchronized锁住f元素(链表/红黑树的头元素)。如果是Node(链表结构)则执行链表的添加操作;如果是TreeNode(树型结构)则执行树添加操作。
5、判断链表长度已经达到临界值8(默认值),当节点超过这个值就需要把链表转换为树结构。
6、如果添加成功就调用addCount()方法统计size,并且检查是否需要扩容。
在JDK1.7和JDK1.8中的区别,在JDK1.8主要设计上的改进有以下几点:
1、不采用segment而采用node,锁住node来实现减小锁粒度。
2、设计了MOVED状态 当resize的中过程中 线程2还在put数据,线程2会帮助resize。
3、使用3个CAS操作来确保node的一些操作的原子性,这种方式代替了锁。
4、sizeCtl的不同值来代表不同含义,起到了控制的作用。
采用synchronized而不是ReentrantLock(java 8 对synchronized做了很多优化)

















 3150
3150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









