




简介:Java是一种面向对象编程语言,提供高可移植性、健壮性和安全性,可在多种平台上运行。文章涵盖Java基础、语法、内存管理、集合框架、IO流、多线程、网络编程、API使用、JVM原理和开发工具等方面,详细介绍了Java编程的各个方面。Java因其丰富的库、强大的跨平台能力和成熟的社区支持,成为企业级应用开发的首选语言,并广泛应用于多个技术领域。 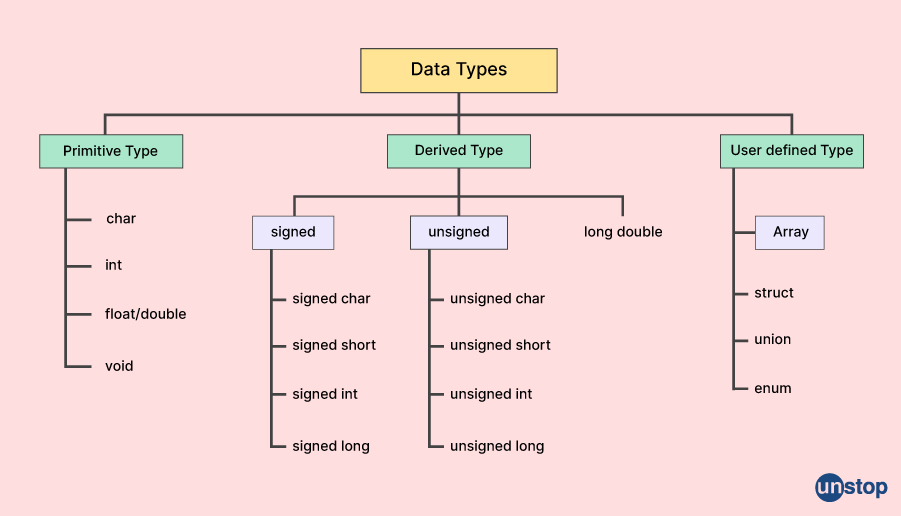
1. 面向对象编程基础
1.1 面向对象编程概念
面向对象编程(Object-Oriented Programming,OOP)是一种编程范式,通过“对象”的概念来构建软件系统。对象是类的实例,包含属性(数据)和方法(行为)。OOP 的核心思想包括封装、继承和多态,这有助于提高代码的重用性、灵活性和可维护性。
1.2 封装、继承和多态
- 封装 是将数据(属性)和代码(方法)绑定到一起,形成一个独立的单元(类)。封装还涉及到权限控制,如私有(private)、受保护(protected)和公共(public)成员。
- 继承 允许新创建的类(子类)继承一个已存在的类(父类)的特性,从而可以复用父类的代码,同时可以扩展新的功能。
- 多态 允许创建一个接口,让不同的对象通过这个接口访问其统一的特性或行为。它通过继承和接口实现,允许调用者通过超类型来引用子类型对象。
面向对象编程的这些基本原则是构建复杂软件系统的基石,能够帮助开发者在构建大型应用程序时,维持代码的清晰结构和易于扩展性。
2. Java语法知识深入
2.1 Java的关键字与数据类型
2.1.1 关键字的作用与分类
Java中的关键字是一些保留的单词,它们在Java语言中具有特殊的意义和用法。这些关键字被编译器识别,用于执行特定的操作,如控制流程(如if、for、while)、访问修饰符(如public、private)以及其他语言功能(如class、interface)。Java的关键字不能用作变量名、方法名或其他标识符。
关键宇可以进一步分类为如下:
- 原始数据类型关键字:int、byte、short、long、float、double、char、boolean。
- 流程控制关键字:if、else、for、while、do、switch、case、default、break、continue。
- 访问修饰符关键字:private、protected、public。
- 类和接口关键字:class、interface、extends、implements、this、super。
- 其他关键字:return、void、new、try、catch、finally、throw、throws、instanceof、package、import。
2.1.2 数据类型的特点与转换
Java的数据类型分为两大类:原始数据类型(也称为基本数据类型)和引用数据类型。原始数据类型直接存储值,而引用数据类型存储的是对实际数据(对象)的引用。
数据类型的转换可以分为两类:
- 隐式类型转换(自动转换) :当赋值操作不会导致数据丢失时,Java会自动将较小的数据类型转换为较大的数据类型。例如,将int类型的值赋给long类型的变量。
int myInt = 10;
long myLong = myInt; // 隐式转换
- 显式类型转换(强制转换) :当赋值操作可能导致数据丢失时,必须使用强制类型转换。显式转换可能会引起精度降低或值的改变,例如将double类型的值赋给int类型的变量。
double myDouble = 10.99;
int myInt = (int) myDouble; // 显式转换,结果为10
代码块:显式类型转换
// Java代码示例 - 显式类型转换
public class TypeCastingExample {
public static void main(String[] args) {
double myDouble = 10.99;
int myInt = (int) myDouble; // 强制类型转换
System.out.println("double value: " + myDouble);
System.out.println("int value: " + myInt);
}
}
在上述代码中, myDouble 是一个 double 类型的变量。当我们尝试将其值赋给一个 int 类型的变量 myInt 时,必须使用强制类型转换 (int) 。由于 double 类型可以存储更大的范围和精度,强制转换会导致小数点后面的数值被截断,因此 myInt 的值将是 10 而不是 10.99 。
显式类型转换是需要注意的,因为不恰当的转换可能会导致数据丢失或精度问题,因此在编写代码时要特别小心。
2.2 Java的控制结构与异常处理
2.2.1 条件语句与循环语句
Java提供了丰富的控制结构来管理程序的流程控制,主要分为条件语句和循环语句。
条件语句 允许根据条件表达式的真假来执行不同的代码块。常用的条件语句包括 if 、 else 以及它们的组合形式 if-else 和 else if 。
int num = 5;
if (num > 0) {
System.out.println("Number is positive");
} else if (num < 0) {
System.out.println("Number is negative");
} else {
System.out.println("Number is zero");
}
循环语句 用于重复执行一段代码直到满足特定条件。Java中的循环语句有 for 、 while 和 do-while 三种形式。
-
for循环:通常用于预设的循环次数,如遍历数组或集合。
for (int i = 0; i < 10; i++) {
System.out.println("Value of i: " + i);
}
-
while循环:当条件为真时,执行循环体。适用于循环次数不确定的情况。
int count = 0;
while (count < 5) {
System.out.println("Count is: " + count);
count++;
}
-
do-while循环:至少执行一次循环体,然后检查条件以决定是否继续执行。
int count = 0;
do {
System.out.println("Count is: " + count);
count++;
} while (count < 5);
2.2.2 异常处理机制
异常处理是Java中一个重要的概念,用于处理程序执行过程中可能出现的错误情况。当Java程序运行出现异常时,会创建一个异常对象,并且这个对象会被传递到程序的异常处理器。
Java的异常处理主要依赖于 try 、 catch 和 finally 语句块:
-
try块:用于包围可能产生异常的代码。 -
catch块:用于捕获并处理异常。 -
finally块:无论是否捕获到异常,finally块中的代码都会执行。
try {
// 可能发生异常的代码
int result = 10 / 0;
} catch (ArithmeticException e) {
// 处理异常
System.out.println("Cannot divide by zero.");
} finally {
// 无论是否发生异常都会执行的代码
System.out.println("This is the finally block.");
}
在上述示例中, try 块尝试执行一个除法操作,但由于除数为0,将会抛出 ArithmeticException 异常。 catch 块捕获这个异常并打印一条错误信息。 finally 块无论是否发生异常都会执行。
异常处理机制允许程序以一种结构化的方式来处理错误情况,提高了程序的健壮性和可靠性。异常对象提供了关于异常类型和状态的信息,这有助于程序员理解和解决问题。
代码块:异常处理
// Java代码示例 - 异常处理
public class ExceptionHandlingExample {
public static void main(String[] args) {
try {
int[] numbers = {1, 2, 3};
System.out.println(numbers[5]); // 将引发数组索引越界异常
} catch (ArrayIndexOutOfBoundsException e) {
System.out.println("ArrayIndexOutOfBoundsException caught!");
} finally {
System.out.println("This is the finally block.");
}
}
}
在上面的示例中,我们尝试访问一个长度为3的数组的第六个元素,这显然将引发 ArrayIndexOutOfBoundsException 异常。异常被捕获在 catch 块中,并且无论是否捕获到异常, finally 块中的代码都将被执行。异常处理允许程序以更加优雅的方式处理错误情况,而不是简单地崩溃或停止执行。
3. Java内存管理机制
3.1 Java内存结构:堆与栈
3.1.1 堆内存的特点与管理
在Java虚拟机(JVM)中,堆内存是对象分配的主要区域,几乎所有的对象实例和数组都在这里分配内存。堆内存的特点是线程共享,生命周期较长,并且随着应用程序的运行,堆内存的使用量会持续增加,直到达到JVM的最大堆内存限制为止。堆内存的管理是Java内存管理的一个重点,它涉及到内存泄漏、性能优化以及垃圾回收机制等关键问题。
堆内存是垃圾回收的主要区域。当一个对象不再被引用时,它就有可能成为垃圾回收的候选对象。JVM通过不同的垃圾回收算法来管理堆内存,例如标记-清除、复制、标记-整理和分代收集算法等。这些算法在不同的垃圾回收器中有着不同的实现,比如Serial、Parallel、CMS(Concurrent Mark Sweep)和G1(Garbage-First)等。
Java堆内存的管理还包括内存分配和回收的监控。开发者可以通过参数调整堆内存的初始大小和最大大小,以及选择垃圾回收器。例如,使用 -Xms 和 -Xmx 参数来设置堆内存的起始和最大值。开发者还应了解不同垃圾回收器的特点,并根据应用程序的特点来选择合适的垃圾回收器,以达到最佳的性能和资源利用率。
// 示例代码:设置堆内存的初始和最大大小
public class HeapMemoryConfig {
public static void main(String[] args) {
// 获取JVM内存堆的信息
long initialHeapSize = Runtime.getRuntime().totalMemory() / (1024 * 1024);
long maxHeapSize = Runtime.getRuntime().maxMemory() / (1024 * 1024);
System.out.println("Initial heap size: " + initialHeapSize + " MB");
System.out.println("Max heap size: " + maxHeapSize + " MB");
}
}
在上述示例代码中,通过 Runtime.getRuntime().totalMemory() 和 Runtime.getRuntime().maxMemory() 方法可以获取当前JVM堆内存的初始大小和最大大小。调整堆内存大小能够适应不同规模的应用程序和数据集。
3.1.2 栈内存的结构与作用
Java的栈内存主要负责局部变量的存储和方法的执行。它具有线程私有的特性,意味着每个线程都会拥有自己的栈内存。栈内存的特点是速度快,因为它是以线程为单位进行分配的,因此不存在线程安全问题。栈内存的操作遵循后进先出(LIFO)原则,主要包含方法调用、局部变量的创建和销毁等。
每个栈帧包含了执行方法时需要的所有信息,包括局部变量表、操作数栈、动态链接、方法返回地址和附加信息。局部变量表用于存储编译时期就确定了的局部变量,包括基本数据类型变量和引用类型的变量。操作数栈则用于执行计算。
由于栈内存的这种特性,使得栈的使用效率很高。当一个方法执行完成之后,相应的栈帧就会被弹出,局部变量就会随之消失,使得栈内存得到快速释放。这也有助于减少内存泄漏的风险。
// 示例代码:调用一个方法并查看栈帧信息
public class StackFrameExample {
public void methodA() {
int a = 10;
methodB();
}
public void methodB() {
int b = 20;
// ...
}
public static void main(String[] args) {
StackFrameExample example = new StackFrameExample();
example.methodA();
}
}
在上述代码中,方法 methodA 调用了 methodB 。当 methodA 执行时,会压入一个栈帧,包含局部变量 a 。当 methodA 调用 methodB 时,会压入第二个栈帧,包含局部变量 b 。当 methodB 执行完成并返回时,第二个栈帧会弹出,局部变量 b 随之消失。当 methodA 执行完毕并返回时,第一个栈帧也会弹出,局部变量 a 随之消失。
3.2 对象创建与垃圾回收
3.2.1 对象的内存布局
在Java中,对象是在堆内存上分配的。对象的内存布局主要由以下几个部分组成:
- 对象头(Header):包括对象的同步锁信息(Mark Word)以及指向类的类型信息的指针(Class Pointer)。
- 实例数据(Instance Data):对象的实例变量,这些变量包括该对象的所有属性。
- 对齐填充(Padding):由于JVM要求对象的起始地址必须是8字节的整数倍,因此可能会有对齐填充字节。
对象头通常占据对象所占内存的12个字节(在32位JVM上)或者16个字节(在64位JVM上)。实例数据则根据对象的属性所占空间大小而定。如果实例数据的空间大小不是8的倍数,JVM会自动进行对齐填充,以确保对象的大小是8的倍数。
// 示例代码:观察对象的内存布局
public class ObjectMemoryLayout {
private int instanceVar;
public ObjectMemoryLayout(int instanceVar) {
this.instanceVar = instanceVar;
}
public static void main(String[] args) {
ObjectMemoryLayout obj = new ObjectMemoryLayout(123);
// 这里可以使用JVM工具来分析obj对象的内存布局
}
}
在实际开发中,理解对象内存布局有助于优化内存使用。比如,通过减少对象中的字段数量和减少字段占用的字节大小,可以有效减少对象的内存占用,提高缓存的利用率和垃圾回收的效率。
3.2.2 垃圾回收机制的原理与优化
Java垃圾回收机制负责回收堆内存中不再被引用的对象。其核心原理是识别并回收那些“死亡”的对象,即没有引用指向的对象。垃圾回收机制的工作主要依赖于可达性分析算法,该算法通过一系列的“GC Roots”对象作为起点,遍历整个对象图,标记所有可达的对象。无法到达的对象即被视为不可达,等待被回收。
垃圾回收器的优化是一个复杂的过程,需要针对具体的应用程序特性来选择和调整。例如,对于新生代对象,可以使用Eden区和两个幸存者区(S0和S1)的复制算法,这种算法更适合处理生命周期短的对象。对于老年代对象,则可能使用标记-整理算法或并发标记-清除算法。
开发者可以通过JVM参数来调整垃圾回收器的行为。例如, -XX:+UseG1GC 参数可以启用G1垃圾回收器,而 -XX:+PrintGCDetails 和 -XX:+PrintGCDateStamps 参数可以打印垃圾回收的详细信息。
// 示例代码:设置垃圾回收的日志输出
public class GarbageCollectionLogging {
public static void main(String[] args) {
// 程序代码
}
}
在上面的代码中,可以添加特定的JVM参数来开启垃圾回收日志的输出,如 -XX:+PrintGCDetails -XX:+PrintGCDateStamps 。这对于监控垃圾回收行为、定位性能问题以及优化内存管理非常有用。
垃圾回收器的优化还包括调整新生代与老年代的比例、调整垃圾回收的触发阈值等。合理的垃圾回收策略能够提高程序的稳定性和吞吐量,减少程序运行时的延迟。
4. Java集合框架应用
4.1 集合接口与实现类
集合框架是Java编程语言中非常重要的一部分,它提供了一系列接口和类用于存储和操作对象集合。掌握集合框架对于提高开发效率和性能优化至关重要。我们将从集合框架的基石开始,了解不同集合接口的特点和使用场景,以及它们的实现类和如何根据实际需求选择合适的实现。
4.1.1 List、Set、Map接口的使用场景
在Java中,List、Set和Map是三种主要的集合接口,它们各自有不同的特点和使用场景。
List接口
List接口是一个有序集合,允许重复的元素。它以索引的形式存储元素,可以通过索引来访问元素。List是最常用的接口之一,尤其适合以下场景:
- 需要维护元素的插入顺序。
- 需要通过索引快速访问元素。
- 需要允许重复元素。
常用的List实现类有 ArrayList 和 LinkedList 。 ArrayList 基于动态数组实现,适合随机访问; LinkedList 基于双向链表实现,适合频繁插入和删除操作。
Set接口
Set接口是一个不允许重复元素的集合。它主要用于去重和检查元素是否存在。Set主要有两种类型的实现:
-
HashSet:基于哈希表实现,对快速查找进行了优化,不保证元素的顺序。 -
TreeSet:基于红黑树实现,元素会自动排序,适合需要排序的场景。
Set通常用于需要去除重复数据,以及对数据的唯一性有严格要求的场景。
Map接口
Map接口是一个映射接口,存储键值对(key-value pairs)。每个键映射到一个值,Map不允许键重复,但值可以重复。Map的实现主要用于以下场景:
- 需要通过键快速检索值。
- 需要将数据组织成键值对形式。
- 需要对键进行排序。
常见的Map实现有 HashMap 、 TreeMap 和 LinkedHashMap 。 HashMap 基于哈希表实现,适用于快速查找; TreeMap 基于红黑树实现,适用于需要排序的场景; LinkedHashMap 保持了插入顺序,适用于需要按照插入顺序操作的场景。
4.1.2 实现类的特性与选择
在选择集合实现类时,了解每个实现类的特性是非常重要的。下表总结了List、Set和Map实现类的特性及其选择依据:
| 实现类 | 特性 | 选择依据 | |------------|--------------------------------------------------------------|----------------------------------------------------| | ArrayList | 随机访问速度快,适合读多写少的场景 | 需要快速访问元素且数据量不是非常大 | | LinkedList | 插入和删除操作性能好,维护了链表结构 | 需要频繁插入和删除操作 | | HashSet | 基于哈希表,提供了快速的查找速度,无序 | 需要快速查找且不需要元素排序 | | TreeSet | 基于红黑树,元素自动排序,提供了对数时间复杂度的排序操作 | 需要对元素进行排序或查找操作 | | HashMap | 基于哈希表,提供了快速的键查找速度,无序 | 需要快速访问键值对且数据量不是非常大 | | TreeMap | 基于红黑树,键自动排序,提供了对数时间复杂度的排序操作 | 需要对键进行排序或有序访问键值对 | | LinkedHashMap| 基于哈希表,维护了元素的插入顺序 | 需要快速访问键值对且需要保持插入顺序 |
选择合适的集合实现类可以提升程序的性能,并且可以更有效地满足业务需求。在实际开发中,应该根据具体场景和需求做出合理的选择。
在下一小节中,我们将详细介绍泛型的原理及其在集合框架中的应用实例。
5. Java高级主题探索
5.1 Java IO流技术
5.1.1 流的概念与分类
在Java中,IO流技术是进行数据输入输出操作的基础。流可以被看作是一系列数据的传输通道,它抽象了数据的来源和去向。IO流主要分为两大类:字节流和字符流。字节流用于处理原始二进制数据,而字符流则专门用于处理文本数据。
字节流包括 InputStream 和 OutputStream 两个抽象类及其各种实现类。例如, FileInputStream 用于从文件读取字节流,而 FileOutputStream 用于将字节流写入文件。字符流则包括 Reader 和 Writer 两个抽象类及其各种实现类,如 FileReader 用于读取字符流, FileWriter 用于写入字符流。
流的使用通常遵循以下步骤: 1. 创建流对象。 2. 使用流对象读取或写入数据。 3. 关闭流对象以释放系统资源。
代码示例:
// 使用FileInputStream读取文件字节流
FileInputStream fis = new FileInputStream("example.txt");
int content;
while ((content = fis.read()) != -1) {
// 处理读取到的数据
}
// 使用FileWriter写入字符流到文件
FileWriter fw = new FileWriter("output.txt");
fw.write("Hello, World!");
fw.close();
5.1.2 文件操作与缓冲区机制
文件操作在IO流技术中占有重要地位。使用 File 类可以对文件系统进行操作,包括但不限于检查文件是否存在、创建文件、删除文件等。
缓冲区机制是IO流中提高数据处理效率的重要手段。通过创建缓冲流,例如 BufferedReader 和 BufferedWriter ,可以减少对底层物理设备的读写次数,从而提高性能。这些缓冲流实际上包装了原有的字节流或字符流,并在内部实现了一个缓冲数组。
代码示例:
// 使用BufferedReader读取文件内容
BufferedReader br = new BufferedReader(new FileReader("example.txt"));
String line;
while ((line = br.readLine()) != null) {
// 处理每一行数据
}
br.close();
// 使用BufferedWriter写入缓冲字符流到文件
BufferedWriter bw = new BufferedWriter(new FileWriter("output.txt"));
bw.write("缓冲区操作");
bw.close();
缓冲区不仅可以提高数据的读写效率,还可以通过 flush() 方法手动刷新缓冲区,确保数据被及时写入底层输出流。
5.2 Java多线程与网络编程
5.2.1 多线程的创建与同步控制
Java支持多线程编程,这使得程序可以同时执行多个任务,从而提高程序的执行效率。Java的多线程主要通过 Thread 类和 Runnable 接口来实现。
创建线程的两种常用方法: 1. 继承 Thread 类并重写 run() 方法。 2. 实现 Runnable 接口并重写 run() 方法。
为了保证多线程的同步,Java提供了一些同步机制,包括 synchronized 关键字和 ReentrantLock 等。同步的关键在于对共享资源的互斥访问。
代码示例:
// 继承Thread类创建线程
class MyThread extends Thread {
public void run() {
// 线程执行的任务
}
}
MyThread t1 = new MyThread();
t1.start();
// 实现Runnable接口创建线程
class MyRunnable implements Runnable {
public void run() {
// 线程执行的任务
}
}
MyRunnable task = new MyRunnable();
Thread t2 = new Thread(task);
t2.start();
5.2.2 Socket通信原理与应用
网络编程允许Java程序之间或与其他语言编写的程序进行数据交换。Socket是实现网络通信的基础。一个Socket代表一个网络连接上的两端的点。
在Java中, ServerSocket 用于在服务器端监听指定端口上的连接请求,当接受到请求后,可以创建一个 Socket 对象来与客户端建立连接。客户端同样使用 Socket 来建立与服务器的连接。
代码示例:
// 服务器端使用ServerSocket监听端口并接收客户端连接
ServerSocket serverSocket = new ServerSocket(12345);
Socket socket = serverSocket.accept();
// 处理接收到的连接
// 客户端使用Socket连接到服务器
Socket clientSocket = new Socket("localhost", 12345);
// 与服务器通信
多线程与网络编程结合使用是开发复杂应用程序的常见做法,例如在实现网络服务器或进行并发网络请求时。
5.3 Java API与虚拟机原理
5.3.1 核心库与JDBC使用技巧
Java的核心库提供了丰富的功能,包括数据结构、网络通信、图形用户界面等。正确使用这些库能显著提高开发效率。
JDBC(Java Database Connectivity)是一个Java API,用于连接和执行查询数据库。JDBC API使得Java程序能够使用标准方法连接数据库管理系统。
JDBC使用步骤通常包括: 1. 加载数据库驱动。 2. 建立与数据库的连接。 3. 创建 Statement 或 PreparedStatement 。 4. 执行SQL语句并处理结果集。 5. 关闭连接。
代码示例:
// 加载驱动
Class.forName("com.mysql.cj.jdbc.Driver");
// 建立连接
String url = "jdbc:mysql://localhost:3306/databaseName";
String user = "username";
String password = "password";
Connection conn = DriverManager.getConnection(url, user, password);
// 创建Statement
Statement stmt = conn.createStatement();
ResultSet rs = stmt.executeQuery("SELECT * FROM tableName");
// 处理结果集
while (rs.next()) {
// 处理每一行数据
}
// 关闭连接
rs.close();
stmt.close();
conn.close();
5.3.2 JVM的工作机制与类加载过程
JVM(Java虚拟机)是运行Java字节码的虚拟计算机。JVM的工作机制包括内存管理、垃圾回收和执行字节码等。
类加载过程是JVM运行Java程序的关键步骤。类加载通常包含以下几个阶段: 1. 加载:JVM查找并加载类文件。 2. 链接:验证加载的类文件、准备内存空间并进行解析。 3. 初始化:执行静态变量的初始化和静态代码块。
类加载机制允许Java应用程序在运行时动态加载类,这提高了程序的灵活性。
5.4 Java开发工具与环境配置
5.4.1 JDK、IDE的选择与配置
JDK(Java Development Kit)是Java开发环境的核心,它包括了Java运行环境(JRE)、Java工具以及Java基础的类库。在编写Java程序时,首先需要安装适合操作系统的JDK。
IDE(集成开发环境)为Java开发提供了便捷的界面和工具。流行的IDE包括Eclipse、IntelliJ IDEA、NetBeans等。选择IDE时应考虑社区支持、插件生态和个性化设置。
配置开发环境通常包括: 1. 安装JDK。 2. 安装IDE并配置JDK路径。 3. 安装并配置必要的插件。 4. 配置构建工具,如Maven或Gradle。
5.4.2 项目管理工具Maven/Gradle的使用
Maven和Gradle是Java项目管理工具,用于构建和维护项目依赖关系。Maven使用XML配置文件,而Gradle使用基于Groovy的DSL。
使用Maven或Gradle可以简化构建过程,自动化依赖管理和项目构建。它们提供了丰富的插件系统,支持从编译、测试到部署等各个阶段。
配置Maven或Gradle项目通常涉及以下步骤: 1. 创建 pom.xml 或 build.gradle 文件。 2. 配置项目依赖。 3. 配置插件和项目构建任务。 4. 运行构建命令。
代码示例(Maven pom.xml ):
<project>
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>my-app</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.example</groupId>
<artifactId>library</artifactId>
<version>1.0</version>
</dependency>
</dependencies>
</project>
代码示例(Gradle build.gradle ):
apply plugin: 'java'
repositories {
mavenCentral()
}
dependencies {
implementation 'org.example:library:1.0'
}
选择和配置合适的开发工具和环境配置对于提高开发效率和项目质量至关重要。
简介:Java是一种面向对象编程语言,提供高可移植性、健壮性和安全性,可在多种平台上运行。文章涵盖Java基础、语法、内存管理、集合框架、IO流、多线程、网络编程、API使用、JVM原理和开发工具等方面,详细介绍了Java编程的各个方面。Java因其丰富的库、强大的跨平台能力和成熟的社区支持,成为企业级应用开发的首选语言,并广泛应用于多个技术领域。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









