




 文章介绍了多任务学习的挑战,特别是任务之间的关系对模型预测质量的影响。提出了MMoE模型,它结合了专家混合结构和门控网络,以优化每个任务并处理不同任务的相关性。MMoE通过在多任务中共享专家子模型,同时利用门控网络动态调整任务的专家组合,从而更好地捕捉任务的共性和特性。与传统的硬参数共享或多任务模型相比,MMoE在不显著增加资源消耗的情况下,提高了模型的适应性和性能。
文章介绍了多任务学习的挑战,特别是任务之间的关系对模型预测质量的影响。提出了MMoE模型,它结合了专家混合结构和门控网络,以优化每个任务并处理不同任务的相关性。MMoE通过在多任务中共享专家子模型,同时利用门控网络动态调整任务的专家组合,从而更好地捕捉任务的共性和特性。与传统的硬参数共享或多任务模型相比,MMoE在不显著增加资源消耗的情况下,提高了模型的适应性和性能。
摘要
对于多任务学习,我们的目标是建立一个单一的模型,同时学习这些多个目标和任务。然而,常用的多任务模型的预测质量往往对任务之间的关系比较敏感。因此,研究任务特定目标和任务间关系之间的建模权衡是很重要的。
在这项工作中,我们提出了一种新的多任务学习方法,多门专家混合模型(MMoE),通过在所有任务中共享专家子模型,我们将专家混合结构(MoE)适应于多任务学习,同时还训练了一个门控网络来优化每个任务。为了在具有不同任务相关性级别的数据上验证我们的方法,我们将其应用于一个合成数据集,在该数据集上我们控制任务相关性。
介绍
近年来,深度神经网络模型已成功应用于许多现实世界的大规模应用,如推荐系统。这样的推荐系统通常需要同时优化多个目标。例如,在向用户推荐电影时,我们可能希望用户不仅购买并观看电影,还希望他们在观看后喜欢上电影,这样他们就会回来看更多的电影。也就是说,我们可以创建模型来同时预测用户的购买和他们的评级。
在MMoE提出之前,多任务学习大多采用hard参数共享机制或者每个任务单独学一个模型的方式,这两种方式都存在明显的缺点:hard参数共享机制在share bottom部分对task差异性表征弱,和task的适配性有待提高;每个任务单独学一个模型,无法利用任务之间的关联性和共性,而且资源消耗大,后期维护成本高。在实际选择方案时,大多团队从模型后续迭代性和成本考虑,会选择hard参数共享机制,也就是多任务学习中share-bottom的DNN模型结构。
Share-bottom的多任务DNN模型的效果,受不同任务之间的相关性影响大,当任务相关性强时,task的特性相对弱,模型结构中share bottom部分可以有效提取task的共性,实现较好的效果。然而,随着不同任务之间的相关性减弱,hard参数共享机制对效果提升作用降低,甚至一定程度制约了模型的效果提升,这一点在MMoE的论文中通过人工生成数据集进行了实验验证,当任务相关性减小,模型损失增大,一定程度表示了模型的拟合能力变弱。
MMoE模型的提出,有效缓解了不同任务的拉扯问题,使模型兼具任务共性和特性的表征。模型结构采用soft参数共享机制,相比share-bottom模型结构,在不增加参数量和成本消耗的情况下,可发挥不同task共同学习的优势,对可持续性迭代友好。
MMOE
Share-bottom模型
Share bottom的多任务DNN模型结构是MMoE模型结构的基础,如图所示,不同task在底层共享多层DNN网络,进行底层特征提取,得到task共享的特征表征,再将其输入到各个task的网络层中进行独立学习。
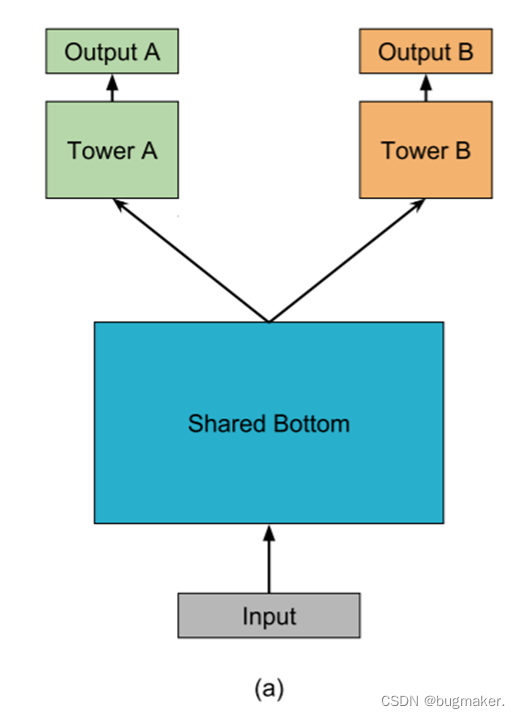
给定K个任务,模型由一个共享底网络(用函数f表示)和K个塔网络hk组成,其中K = 1, 2,…,分别为每个任务。共享底层网络遵循输入层,塔式网络建立在共享底层输出的基础上。然后每个任务的单独输出yk紧跟在相应的特定于任务的塔后面。对于任务k,模型可以表示为:
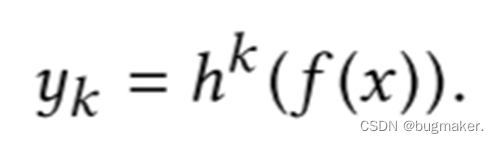
其中,f(x)表示Share bottom部分,hk表示Tower部分。
OMoE
原专家混合(OMoE)模型的结构如下:
原专家混合(OMoE)模型可表示为:
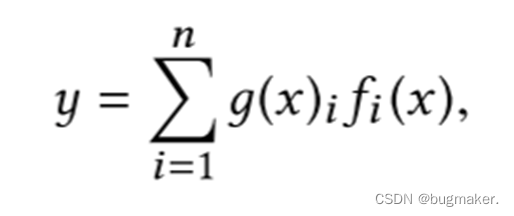
其中 f(x)表示专家网络。这里,i = 1,…, n表示n个专家网络,g(x)表示一个门控网络,集合所有专家的结果。更具体地说,门控网络根据输入对n个专家产生一个分布,最终的输出是所有专家输出的加权和。
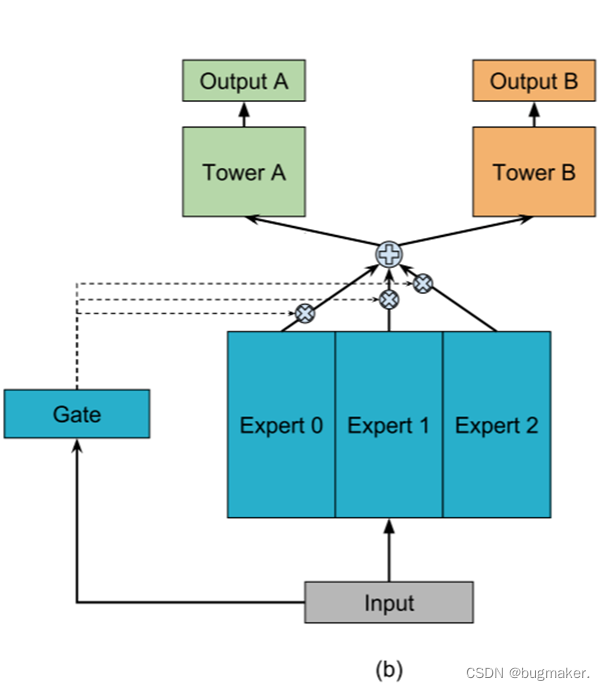
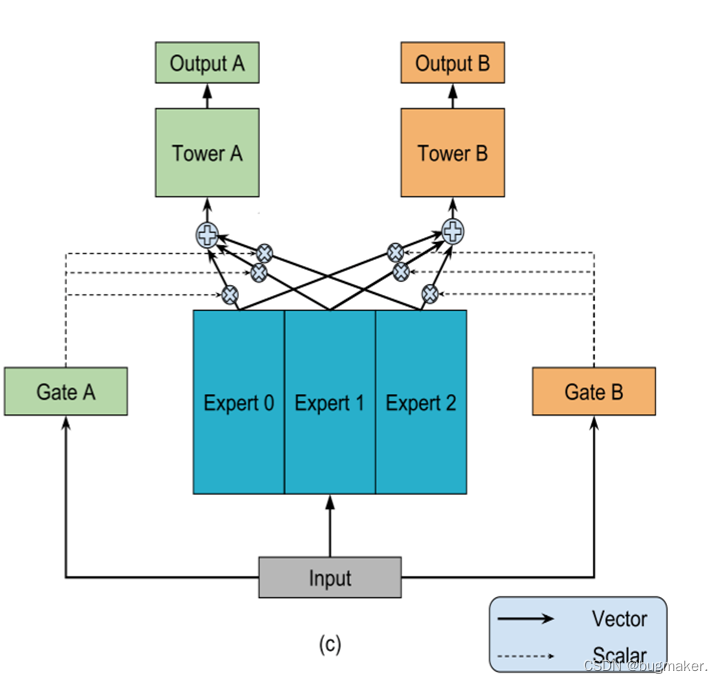
MMoE
MMoE模型引入专家(expert)概念,对share bottom部分进行分组,形成多个expert,同时使用门网络,对每个task生成对应的expert权重后进行组合,得到task的输入表征,再进行后续task层的学习,网络结构如图所示。Gate的运用使模型可以自动学习不同task的expert组合,对任务之间的共性和特性自动调整参数进行学习,从而使模型有效地挖掘任务之间的关系。
更准确地说,任务k的输出为
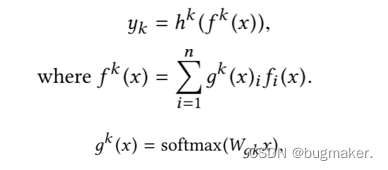
可以看到,所谓的门控网络本质上就是一个权重矩阵W,每个门控网络可以学习“选择”一个专家子集。作为一种特殊情况,如果只选择了一个门得分最高的专家,那么每个门网络实际上将输入空间线性划分为n个区域,每个区域对应一个专家。
MMoE能够以一种复杂的方式对任务关系进行建模,方法是决定不同门之间的重叠如何产生分离。如果任务的相关性较低,那么共享专家将受到惩罚,这些任务的控制网络将学会使用不同的专家。与共享底部模型相比,MMoE仅具有几个额外的门控网络,且门控网络中模型参数的数量可以忽略不计。因此,整个模型在多任务学习中仍然尽可能地享受知识转移的好处。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









