







 本文详细解析了Hive SQL在MapReduce环境中的执行流程,包括Join操作、Group By及Distinct功能的具体实现机制,深入探讨了MapReduce如何处理这些SQL语句。
本文详细解析了Hive SQL在MapReduce环境中的执行流程,包括Join操作、Group By及Distinct功能的具体实现机制,深入探讨了MapReduce如何处理这些SQL语句。
前言:hive将hql语句经过解析器,编译器,优化器,执行器变成可执行的mapreduce程序,balabala…又一顿mapreduce运行过程给面试官讲完之后
面试官:小伙子理论不错。那比如一个简单的hql语句select x from x1 join 一下 x2 group by ,这条语句对应到mr是在哪个阶段干活具体又是怎么处理的。
我又GG了 只背理论,理解不深入的后果。

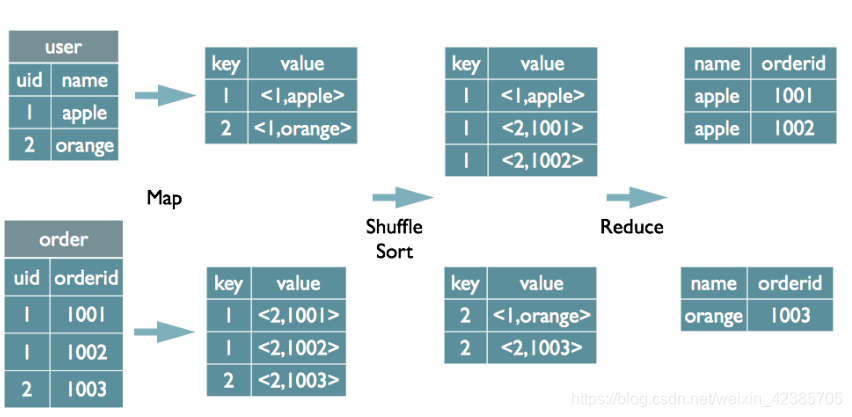
1.如何join
select u.name, o.orderid from order o join user u on o.uid = u.uid;
在map的输出value中为不同表的数据打上tag标记,在reduce阶段根据tag判断数据来源
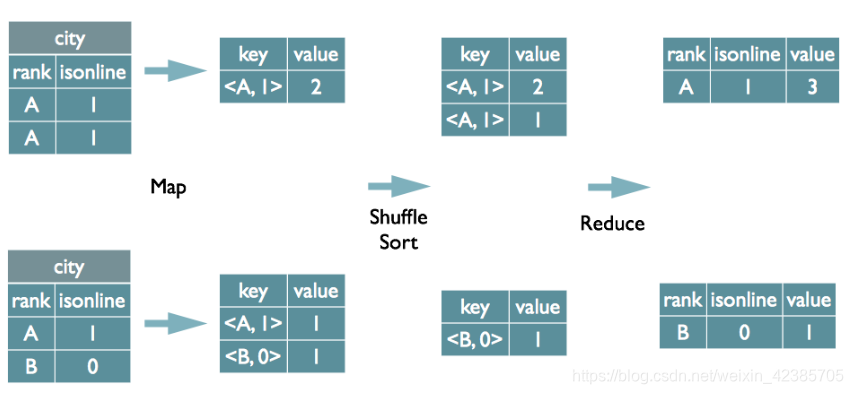
2.如何group by
将GroupBy的字段组合为map的输出key值,利用MapReduce的排序,在reduce阶段保存LastKey区分不同的key。
select rank, isonline, count(*) from city group by rank, isonline;
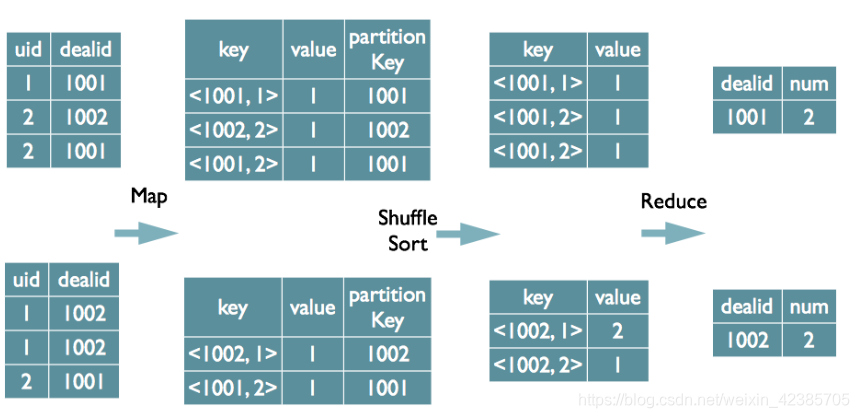
3.Distinct的实现原理
select dealid, count(distinct uid) num from order group by dealid;
当只有一个distinct字段时,如果不考虑Map阶段的Hash GroupBy,只需要将GroupBy字段和Distinct字段组合为map输出key,利用mapreduce的排序,同时将GroupBy字段作 为reduce的key,在reduce阶段保存LastKey即可完成去重
如果有多个distinct字段
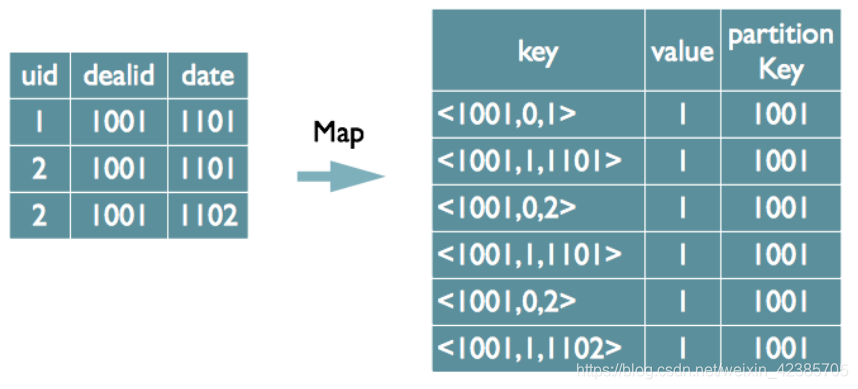
select dealid, count(distinct uid), count(distinct date) from order group by dealid;
实现方式有两种:
1)如果仍然按照上面一个distinct字段的方法,无法跟据uid和date分别排序,也就无法通过LastKey去重,仍然需要在reduce阶段在内存中通过Hash去重
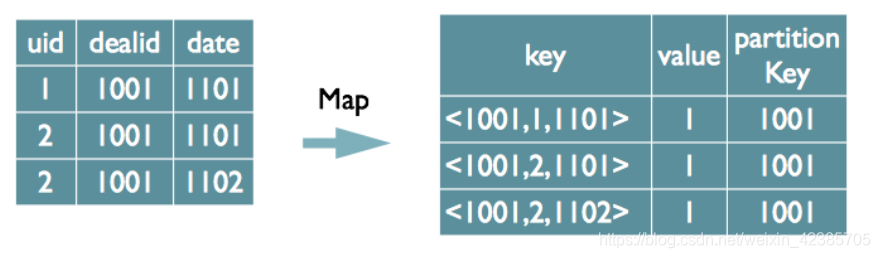
第二种实现方式,可以对所有的distinct字段编号,每行数据生成n行数据,那么相同字段就会分别排序,这时只需要在reduce阶段记录LastKey即可去重。
这种实现方式很好的利用了MapReduce的排序,节省了reduce阶段去重的内存消耗,但是缺点是增加了shuffle的数据量。
需要注意的是,在生成reduce value时,除第一个distinct字段所在行需要保留value值,其余distinct数据行value字段均可为空。

















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









