




参考:http://www.360doc.com/content/15/0601/21/12129652_474971709.shtml
https://blog.youkuaiyun.com/jkhere/article/details/12227901
- 点击下面的“运行”里的运行

- 在出现下面的窗口,输入如下所示的,保存后设置快捷键就可直接运行到d:\code目录下
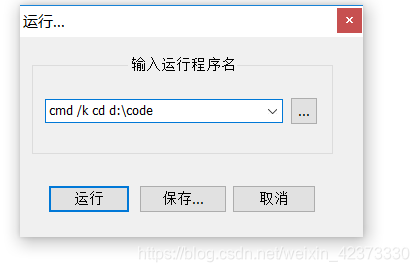
- 这样以后按快捷键后就会直接出现以下窗口

- 这样就可以运行你的更快的运行程序了
- 来自:JKhere https://blog.youkuaiyun.com/jkhere/article/details/12227901
- 编译和运行一步完成:
cmd /K cd /d $(CURRENT_DIRECTORY) & g++ -o $(NAME_PART).exe $(FULL_CURRENT_PATH) & $(NAME_PART) & cd $(CURRENT_DIRECTORY)
编译源代码:
cmd /K cd /d $(CURRENT_DIRECTORY) & g++ -o
(
N
A
M
E
P
A
R
T
)
.
e
x
e
"
(NAME_PART).exe "
(NAMEPART).exe"(FULL_CURRENT_PATH)" & PAUSE & EXIT
cmd /K cd /d $(CURRENT_DIRECTORY) & g++ -o $(NAME_PART).exe $(FULL_CURRENT_PATH) & cd $(CURRENT_DIRECTORY)
运行上一步生成的可执行文件:
cmd /k cd /d KaTeX parse error: Expected 'EOF', got '&' at position 21: …ENT_DIRECTORY) &̲ "(NAME_PART)" & PAUSE & EXIT
cmd /k cd /d $(CURRENT_DIRECTORY) & $(NAME_PART) & PAUSE & EXIT
python编译运行:
cmd /K cd /d $(CURRENT_DIRECTORY) & python $(FULL_CURRENT_PATH) & cd $(CURRENT_DIRECTORY)
在dos窗口中打开当前目录:
cmd /K cd /d $(CURRENT_DIRECTORY)
在文件浏览器中打开当前目录:
explorer $(CURRENT_DIRECTORY)
$(NAME_PART) : 当前操作文件的文件名,并可设置快捷键
$(FULL_CURRENT_PATH):当前操作文件的完整路径,包括盘符,路径,文件名,后缀
$(CURRENT_DIRECTORY):当前操作文件的目录,只有目录,没有文件名
&PAUSE:运行后暂停等待键盘操作
&EXIT:完成后退出运行窗口,回到notepad++
cmd /k的含义是执行后面的命令,并且执行完毕后保留窗口. (也就是说,cmd表示打开Command Prompt窗口,且运行跟在/k后边的命令—python)
cmd /k python == 开始 –> 运行 –> 输入cmd –> 输入python
$(FULL_CURRENT_PATH)的含义是当前文件的完整路径,这是 Notepad++ 的宏定义
&是连接多条命令
PAUSE表示运行结束后暂停,等待一个任意按键
EXIT表示关闭命令行窗口 (如果使用 cmd /c 就可以省掉 EXIT 了。)

















 3337
3337

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









