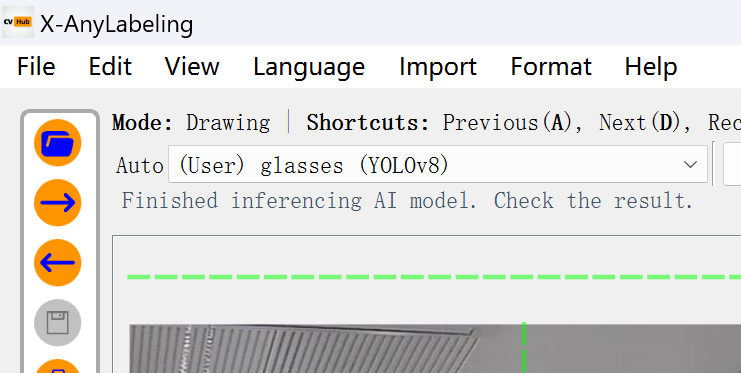
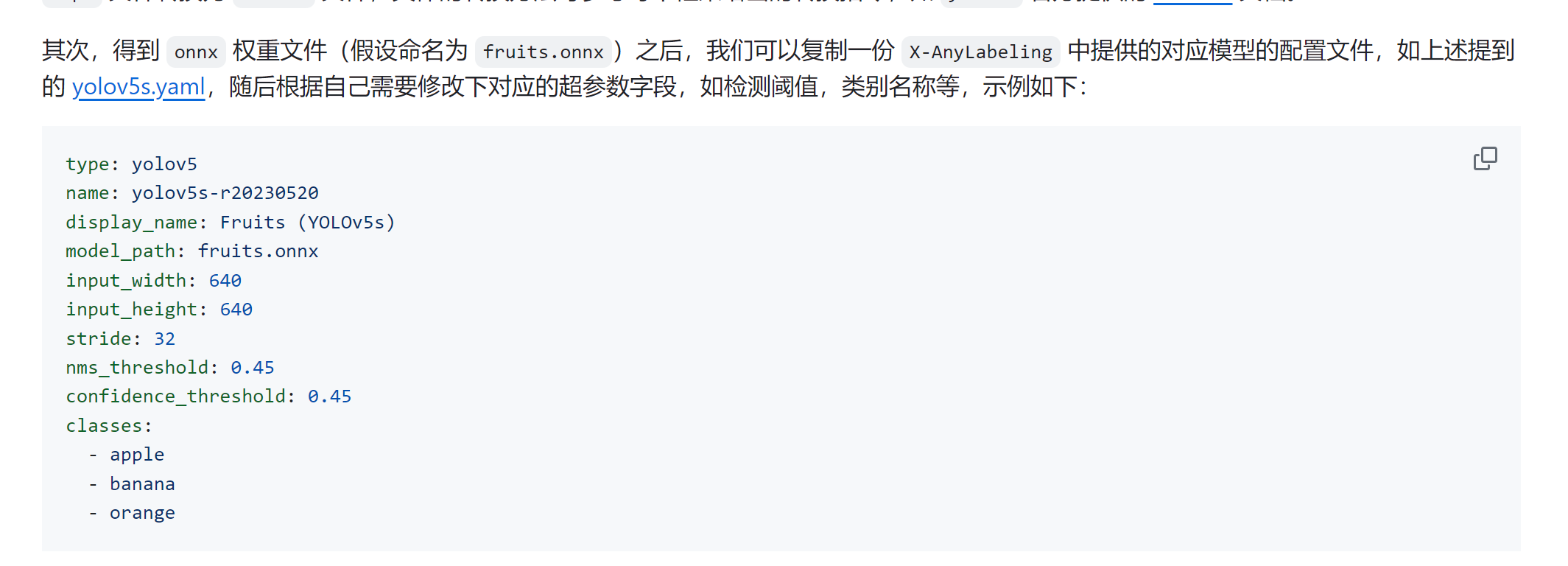
一、X-AnyLabeling 图像标注工具及模型自动标注 参考:https://github.com/CVHub520/X-AnyLabeling 1、下载 直接https://github.com/CVHub520/X-AnyLabeling/releases/tag/下载对应版本 软件打开: 2、自定义标注模型yaml构建 这里自定义模型自动标注加载预训练的yolov8 佩戴眼镜检测模型 yolov8 pt转onnx: yolo export model=/mn









 超级会员免费看
超级会员免费看

 本文介绍了使用X-AnyLabeling进行图像标注,包括下载与自定义模型加载,特别是利用yolov8模型进行自动标注,并将标注结果转换为yolo格式。此外,还讲述了json2yolo格式转换和训练数据集的划分过程。
本文介绍了使用X-AnyLabeling进行图像标注,包括下载与自定义模型加载,特别是利用yolov8模型进行自动标注,并将标注结果转换为yolo格式。此外,还讲述了json2yolo格式转换和训练数据集的划分过程。

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 6373
6373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








