






前言
介绍redis Cluster集群之前,我想先介绍下过去的常见的几种redis集群模式,并对其优缺点做相应的阐述。
Redis 支持三种集群模式,分别为主从模式、哨兵模式和Cluster模式。
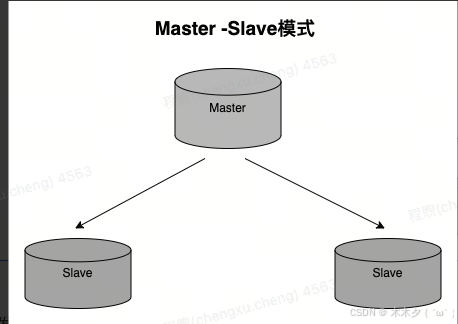
主从复制模式
主从复制是Redis的一种基本集群模式,它通过将一个Redis节点(主节点)的数据复制到一个或多个其他Redis节点(从节点)来实现数据的冗余和备份。
主节点负责处理客户端的写操作,同时从节点会实时同步主节点的数据。客户端可以从从节点读取数据,实现读写分离,提高系统性能。
-
故障发生时,需人工介入。
-
无法实现数据分片,受单节点内存限制。
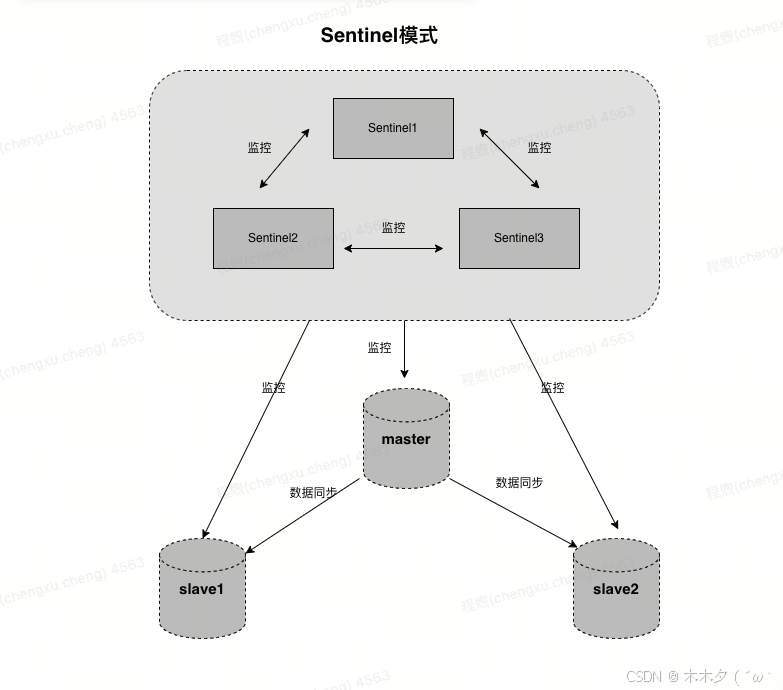
哨兵模式
哨兵模式是在主从复制基础上加入了哨兵节点,实现了自动故障转移。哨兵节点是一种特殊的Redis节点,它会监控主节点和从节点的运行状态。当主节点发生故障时,哨兵节点会自动从从节点中选举出一个新的主节点,并通知其他从节点和客户端,实现故障转移。
缺点:
-
无法实现数据分片,受单节点内存限制。
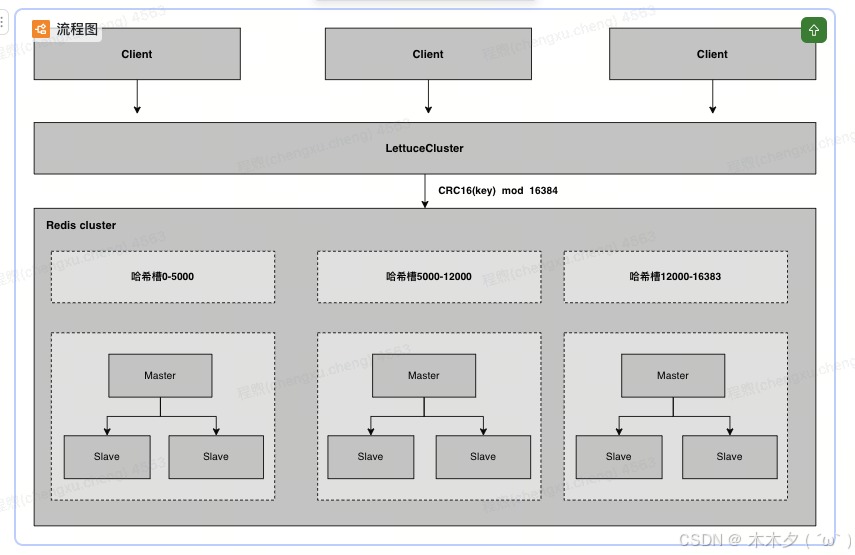
Cluster模式
Cluster模式是Redis的一种高级集群模式,它通过数据分片和分布式存储实现了负载均衡和高可用性。这种集群模式没有中心节点,可自由水平扩展,官网建议不超过1000个节点,在Cluster模式下,集群将数据分为16384个槽位,每个节点负责管理一部分槽位。当客户端向Redis Cluster发送请求时,Cluster会根据键的哈希值将请求路由到相应的节点。具体来说,Redis Cluster使用CRC16算法计算键的哈希值,然后对16384取模,得到槽位编号。
Cluster 集群通信原理
欲知答案,必须先了解下Gossip算法。Gossip协议工作原理就是集群内每个节点每隔一段时间都会往另外几个节点发送ping消息,同时其他节点接收到ping之后返回pong,一段时间后所有的节点都会知道集群完整的信息,这种方式类似流言传播。gossip协议包含多种消息,包括ping,pong,meet,fail,等等
meet:
某个节点发送meet给新加入的节点,让新节点加入集群中,然后新节点就会开始与其他节点进行通信
ping:
每个节点都会频繁给其他节点发送ping,其中包含自己的状态还有自己维护的集群元数据(节点和slot的映射关系),互相通过ping交换元数据 互相进行元数据的更新,ping消息体里封装了自身节点和部分其他节点的状态数据
pong:
当接收到ping,meet消息后,作为响应消息回复给发送方确认,pong消息包含自身的状态数据。
fail:
某个节点判断另一个节点fail之后,就发送fail给其他节点,通知其他节点,指定的节点宕机了。
节点通信机制如下:
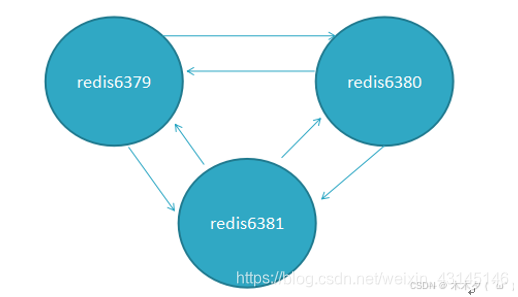

ping很频繁,而且要携带一些元数据,所以可能会加重网络负担(官方推荐不要超过1000个节点),每个节点每秒会执行10次ping,每次会选择5个最久没有通信的其他节点,当然如果发现某个节点通信延时达到了cluster_node_timeout / 2,那么立即发送ping,避免数据交换延时过长,落后的时间太长了,比如说,两个节点之间都10分钟没有交换数据了,那么整个集群处于严重的元数据不一致的情况,就会有问题,所以cluster_node_timeout可以调节,如果调节比较大,那么会降低发送的频率。每次ping,一个是带上自己节点的信息,还有就是带上1/10其他节点的信息,发送出去,进行数据交换,至少包含3个其他节点的信息,最多包含总节点-2个其他节点的信息
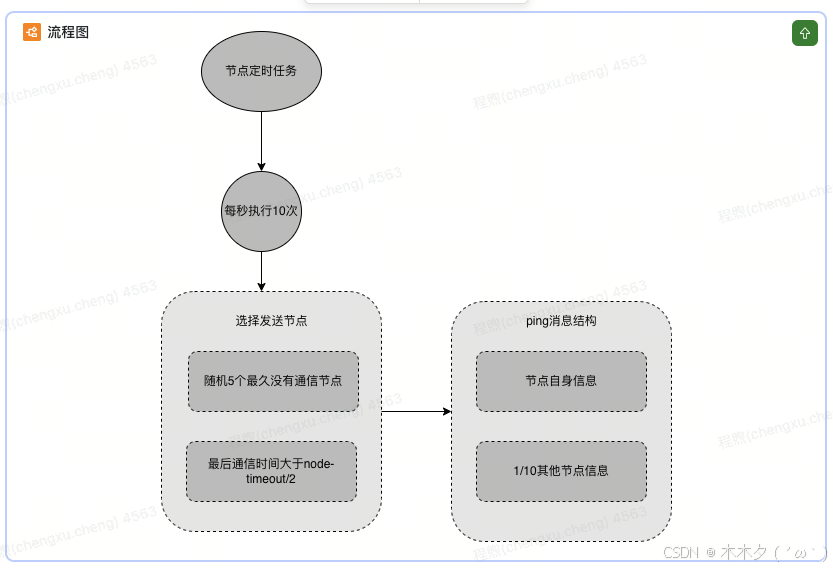
Cluster 故障转移原理
-
故障检测:
redis集群通过Gossip协议广播自己的状态以及对整个集群认知的改变。比如A节点发现B节点失联了,他会将这条信息像集群中其他节点(C,D,E)广播,如果有一个节点接收到了B节点失联的数量超过总节点的1/2就会标记该节点(fail),然后向集群广播,强迫其他节点接收B节点下线的事实,并立即启动主从切换。
-
故障转移:
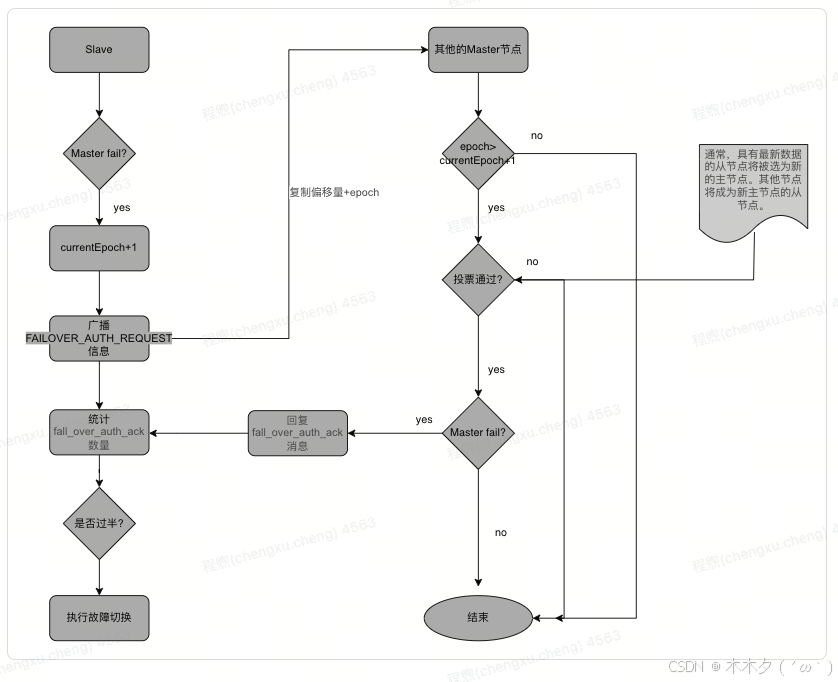
当slave发现自己的master变为FAIL状态时,便尝试进行Failover,以期成为新的master ,由于挂掉的master可能会有多个slave,从而存在多个slave竞争成为master节点的过程(基于Raft算法),过程如下:
-
从节点会发送投票请求到其他节点,要求其他节点支持自己成为新的主节点。
-
其他节点会根据自己的状态和能力来决定是否支持该从节点成为新的主节点。
-
如果有超过半数的节点同意支持该从节点成为主节点,那么该从节点就会成为新的主节点。
在选举过程中,Redis Cluster会根据每个节点的状态、延迟等因素来选择新的主节点,以确保集群的高可用性和稳定性。
流程如下:
Cluster 扩容缩容原理
-
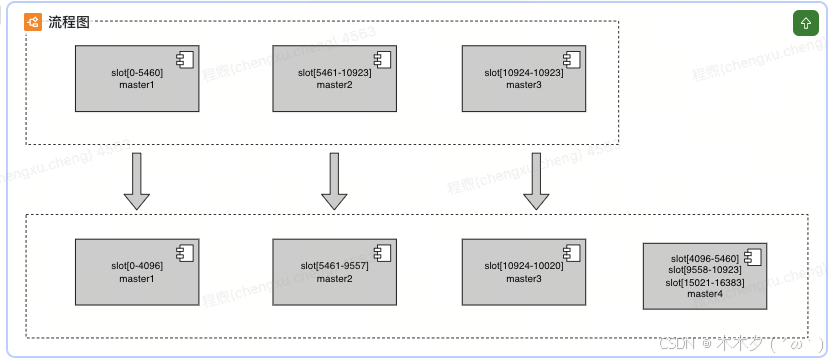
扩容:
假设有三个master,每个master负责16384/3=5461 slots
加了一个新的master后,每个master负责16384/4 = 4096个slot
确认迁移计划后,每个master需要迁移(5046-4096=950)个slot到新的master上,然后以slot为单位进行迁移
-
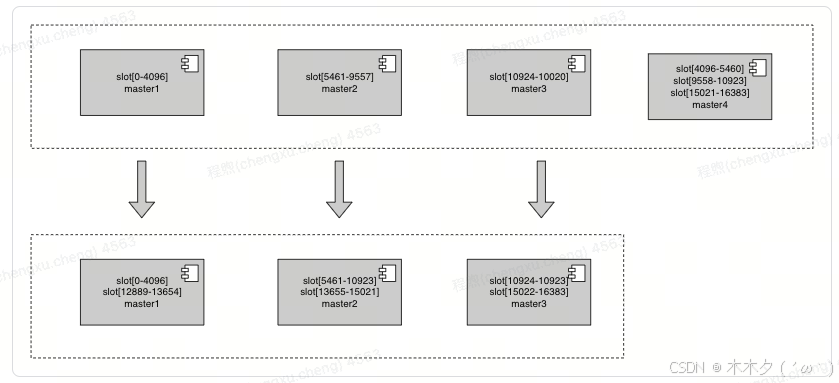
缩容:
Client 访问cluster流程
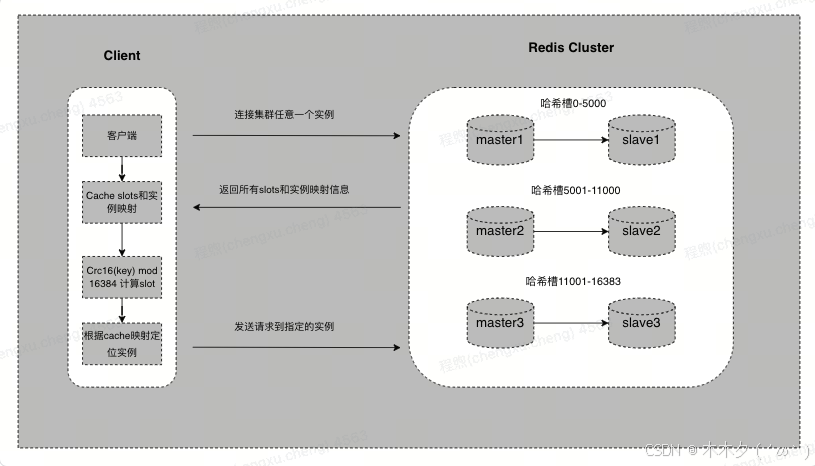
数据重新分配(新增或删除节点),客户端如何感知
集群中的节点通过gossip协议相互传递消息获取最新的hash slot分配信息,一旦新增或删除节点,势必会导致hash slot重新分配,相应的节点数据也需要做迁移。客户端如何感知呢。
数据重新分配(新增或删除节点),客户端如何感知
集群中的节点通过gossip协议相互传递消息获取最新的hash slot分配信息,一旦新增或删除节点,势必会导致hash slot重新分配,相应的节点数据也需要做迁移。客户端如何感知呢。
重定向:redis将请求数据发送给cluster节点,节点发现当前key不在自己这里,然后会返回客户端error错误,并将正确的节点ip一并返回,客户端就可以根据返回的ip,重新请求正确的节点获取数据。
![]()
重定向error : moved,asked
moved: slot数据已全部迁移到新的实例(迁移完成)
asked: slot数据部分迁移到新的实例(部分迁移)
重定向:redis将请求数据发送给cluster节点,节点发现当前key不在自己这里,然后会返回客户端error错误,并将正确的节点ip一并返回,客户端就可以根据返回的ip,重新请求正确的节点获取数据。
高性能客户端Lettuce
对于java开发者来说,Jedis和Lettuce是当前比较主流Redis客户端,springBoot 2.0之前默认的客户端是jedis,2.0之后默认的客户端是lettuce。Lettuce客户端基于Netty的NIO框架实现,对于大多数的Redis操作,只需要维持单一的连接即可高效支持业务端的并发请求 —— 这点与Jedis的连接池模式有很大不同。同时,Lettuce支持的特性更加全面下面我们来看看这两种客户端的特点和区别
Lettuce Vs Jedis
| 纬度 | Lettuce | Jedis |
|---|---|---|
| 单线程 vs 多线程 | Lettuce是基于Netty的连接实例,可以在多个线程间并发访问。单一长链接,所有业务线程都是通过单一共享长链接访问redis实例(事务场景除外) | Jedis实例不是线程安全的,因此在多线程环境下,你需要每个线程创建一个新的连接实例,或者使用连接池 |
| 阻塞 vs 非阻塞 | Lettuce支持异步、反应式、同步和非阻塞操作。 | Jedis操作是同步阻塞的,不支持异步和非阻塞操作。 |
| 自动刷新拓扑 | 支持自动刷新拓扑。 lettuce框架本身支持定时任务自动刷新拓扑,默认60s,hll硬编码30s。 | 不支持自动刷新拓扑。 当集群拓扑发生变化时(例如节点增加、删除或者主从切换),客户端并不会自动获取新的集群配置。应用程序需要根据业务需求手动处理这类情况,例如重新初始化 JedisCluster 对象或者调用 |
| 自适应刷新拓扑 | 支持。 lettuce 在执行命令时,如果遇到如 MOVED 或 ASK 类型的错误响应(这是 Redis Cluster 在请求路由到错误节点时返回的错误类型),会根据这些异常反馈尝试重定向到正确的节点上执行命令。同时异步执行cluster node命令,获取集群信息,更新内存拓扑 | 不支持。 lettuce 在执行命令时,如果遇到如 MOVED 或 ASK 类型的错误响应(这是 Redis Cluster 在请求路由到错误节点时返回的错误类型),也会进行重定向,但不会刷新拓扑 |
Lettuce 访问RedisCluster流程
-
服务启动时初始化客户端实例,创建共享链接(shareNativeConnection = true 时, 共用一个物理链接,shareNativeConnection = false,每次创建新的物理链接),链接配置url的第一个实例。
-
然后客户端实例,通过共享长链接,发送cluster node命令获取到集群拓扑信息,同时激活拓扑定时刷新任务(llm这边统一设置的是硬编码30s)
-
客户端请求set,get命令时,先通过CRC16(KEY) mod 16384计算出slot的值,然后根据拓扑缓存信息定位需要访问的实例ip,然后去缓存里拿链接,缓存【此处缓存是一个conrrenthashmap结构,key是包含ip+port+ConnectionIntent(read,write)的对象,vaulue是一个链接对象】,缓存里没有会创建一个长链接放入缓存
-
解析服务端返回的结果,如果是重定向erorr(重定向次数不能超过5次),异步提交一个刷新集群拓扑的任务(拓扑刷新的过程会进行限流,扩容缩容期间会触发的大量的重定向事件),同时重新请求新的实例。
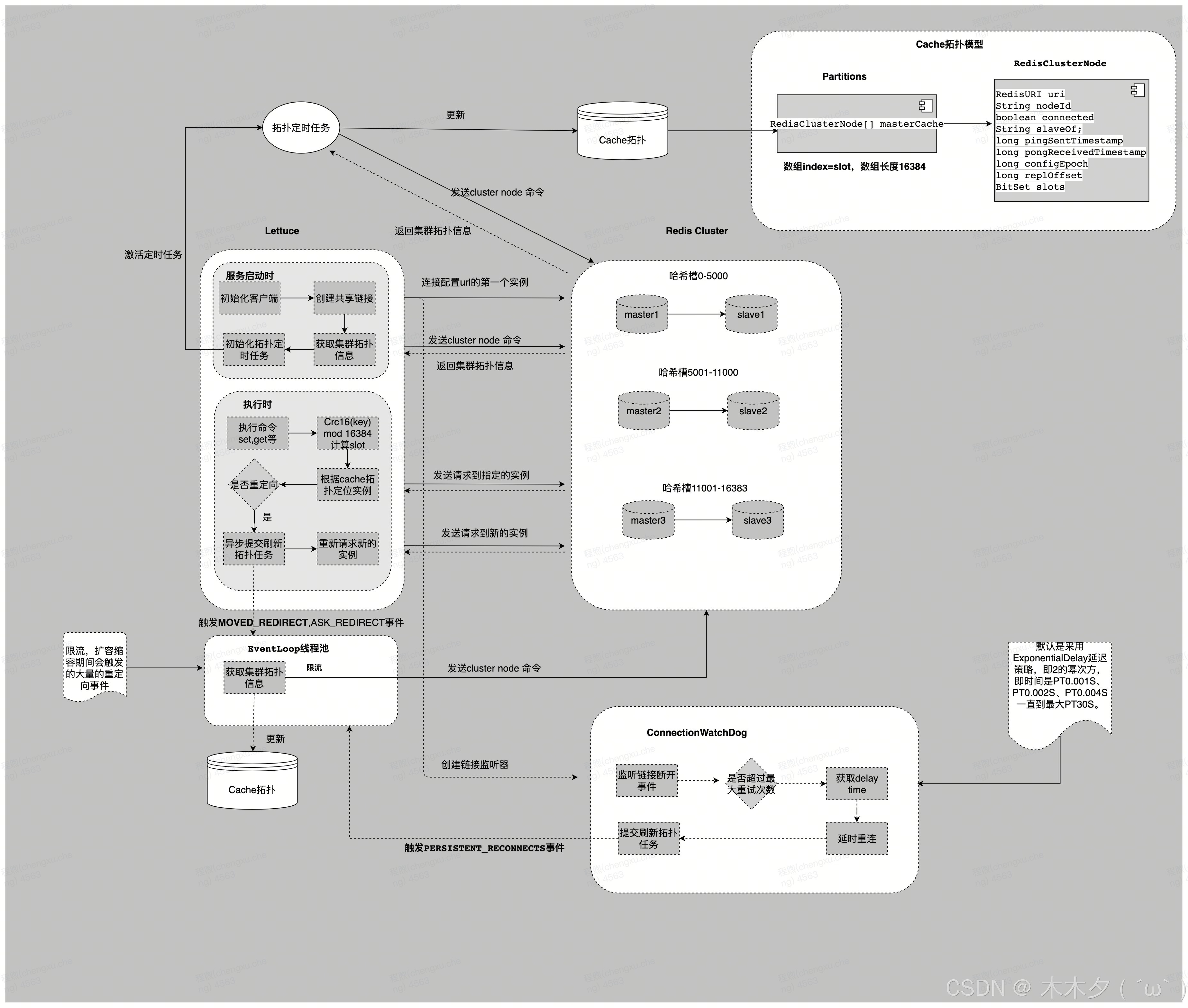
ConnectionWatchDog
ConnectionWatchdog 是 Lettuce 客户端中的一个组件,它负责监视与 Redis 服务器的连接状态,并在连接断开时尝试自动重连。这个组件是 Lettuce 客户端的默认配置之一,旨在提高应用程序的可用性和健壮性 。
链接断开的监控本质上还是依赖keepAlive探活机制,或者服务端因某些原因主动关闭链接。在某些情况下,例如长时间没有操作 Redis 导致连接超时,或者网络问题导致连接中断, ConnectionWatchdog 会尝试重新建立连接。然而,它并不会立即重连,而是会根据一定的策略(如指数退避策略)来延迟重连时间.
CLUSTER NODES命令详解
127.0.0.1:6379> CLUSTER NODES aa21d77504e84708dfb3bbfac5245caf15454de1 xxx.xxx.xx.xx:6382@16382 myself,master - 0 1708240763000 9 connected 0-1364 5461-12287 87db139b877abef5260acad4abfc98a13d7c89dc xxx.xxx.xx.xx:6381@16381 master - 0 1708240763000 1 connected 1365-5460 64e08ec5999853e9872e2caa96a740ccc7419a56 xxx.xxx.xx.xx:6386@16386 slave 87db139b877abef5260acad4abfc98a13d7c89dc 0 1708240766231 1 connected a879da074a4167c284ed5fd15277e02bf2d25626 xxx.xxx.xx.xx:6385@16385 slave b53ada569ade1032fcdea547a8244ee794dc7214 0 1708240764000 3 connected b53ada569ade1032fcdea547a8244ee794dc7214 xxx.xxx.xx.xx:6383@16383 master - 0 1708240767000 3 connected 12288-16383 fe3e77c93c006a768b4151bbec630dedb42455c7 xxx.xxx.xx.xx:6384@16384 slave aa21d77504e84708dfb3bbfac5245caf15454de1 0 1708240765226 9 connected cbb4d8289865fc39c093dc8c89d6e5a22f9e7612 xxx.xxx.xx.xx:6388@16388 slave aa21d77504e84708dfb3bbfac5245caf15454de1 0 1708240767234 9 connected f9c3d83a04697d79522361a7dfe3c05783ed65d2 xxx.xxx.xx.xx:6387@16387 slave aa21d77504e84708dfb3bbfac5245caf15454de1 0 1708240764223 9 connected
内容由以下字段组成:
<id> <ip:port> <flags> <master> <ping-sent> <pong-recv> <config-epoch> <link-state> <slot> <slot> ... <slot>
| 属性 | 意义 |
| id | 节点 ID,一个40个字符的随机字符串,当一个节点被创建时不会再发生变化(除非CLUSTER RESET HARD被使用)。 |
| ip:port | 客户端应该联系节点以运行查询的节点地址。 |
| flags | 逗号列表分隔的标志:myself,master,slave,fail?,fail,handshake,noaddr,noflags。标志在下一节详细解释。 |
| master | 如果节点是从属节点,并且主节点已知,则节点ID为主节点,否则为“ - ”字符。 |
| ping-sent | 以毫秒为单位的当前激活的ping发送的unix时间,如果没有挂起的ping,则为零 |
| pong-recv | 毫秒 unix 时间收到最后一个乒乓球。 |
| config-epoch | 当前节点(或当前主节点,如果该节点是从节点)的配置时期(或版本)。每次发生故障切换时,都会创建一个新的,唯一的,单调递增的配置时期。如果多个节点声称服务于相同的哈希槽,则具有较高配置时期的节点将获胜。 |
| link-state | 用于节点到节点集群总线的链路状态。我们使用此链接与节点进行通信。可以是connected或disconnected。 |
| slot | 散列槽号或范围。从参数9开始,但总共可能有16384个条目(限制从未达到)。这是此节点提供的散列槽列表。如果条目仅仅是一个数字,则被解析为这样。如果它是一个范围,它是在形式start-end,并且意味着节点负责所有散列时隙从start到end包括起始和结束值。 |
Lettuce的mget实现方式(批量取值)
Redis Cluster的Multi-Key操作受槽位限制,例如我们执行mget,获取同一个节点不同槽位多个key的数据,是限制执行的:

mget涉及多个key的时候,主要有三个步骤:
public RedisFuture<List<KeyValue<K, V>>> mget(Iterable<K> keys) {
//将key按照槽位拆分
Map<Integer, List<K>> partitioned = SlotHash.partition(codec, keys);
if (partitioned.size() < 2) {
return super.mget(keys);
}
Map<K, Integer> slots = SlotHash.getSlots(partitioned);
Map<Integer, RedisFuture<List<KeyValue<K, V>>>> executions = new HashMap<>();
//对不同槽位的keys分别执行mget
for (Map.Entry<Integer, List<K>> entry : partitioned.entrySet()) {
RedisFuture<List<KeyValue<K, V>>> mget = super.mget(entry.getValue());
executions.put(entry.getKey(), mget);
}
// 获取、合并、排序结果
return new PipelinedRedisFuture<>(executions, objectPipelinedRedisFuture -> {
List<KeyValue<K, V>> result = new ArrayList<>();
for (K opKey : keys) {
int slot = slots.get(opKey);
int position = partitioned.get(slot).indexOf(opKey);
RedisFuture<List<KeyValue<K, V>>> listRedisFuture = executions.get(slot);
result.add(MultiNodeExecution.execute(() -> listRedisFuture.get().get(position)));
}
return result;
});
}
1、按照槽位 将key进行拆分;
2、分别对相同槽位的key去对应的槽位mget获取数据;
3、将所有执行的结果按照传参的key顺序排序返回。
所以Lettuce的mget的key数量越多,涉及的槽位数量越多,性能就会越差。比如mget 100个key的数据,分组后,槽位数量30个(且分布在3个master节点上)。这个时候会请求30次。Codis也是拆分执行mget,不过是并发发送命令,并使用pipeline提高性能,进而减少了网络的开销。
性能优化(客户端改造)
我们利用pipeline对Redis节点批量发送get命令,相对于Lettuce串行发送mget命令来说,减少了多次跨槽位mget发送命令的网络耗时。具体步骤如下:
1、把所有key按照所在的Redis节点拆分;
2、通过pipeline对每个Redis节点批量发送get命令;
3、获取所有命令执行结果,排序、合并结果,并返回。
这样改造,使用pipeline一次发送批量的命令,减少了串行批量发送命令的网络耗时。
在改造完客户端之后,网络上有人对客户端的mget进行了性能测试,测试了下面三种类型的耗时
mget 1000key性能pk:
| RT | Lettuce(改造后) | Lettuce(改造前) |
|---|---|---|
| avg | 0.92ms | 5.04ms |
| p99 | 1.22ms | 8.91ms |
| p99.9 | 3.88ms | 32ms |
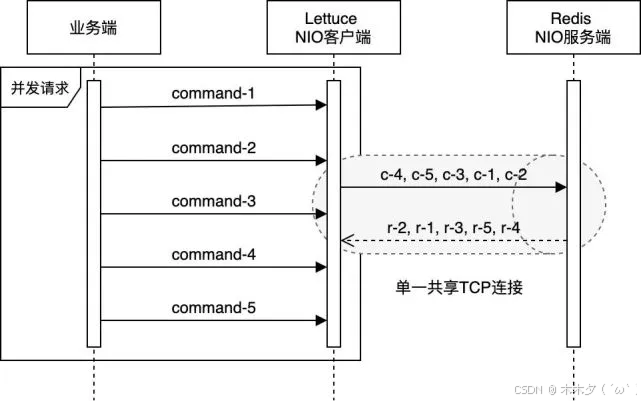
Lettuce使用单一连接与Redis交互流程
业务端的并发请求均会被放入EventLoop的任务队列中,最终被该线程顺序处理。同时,Lettuce自身也会维护一个队列,当其通过EventLoop向Redis发送指令时,成功发送的指令会被放入该队列;当收到服务端的响应时,Lettuce又会以FIFO的方式从队列的头部取出对应的指令,进行后续处理,这就是Lettuce仅凭单一的Redis连接即可支持业务端的大部分并发请求 且是线程安全的重要原因。
Netty NIO简介
下图展示了Netty NIO的核心逻辑。NIO通常被理解为non-blocking I/O的缩写,表示非阻塞I/O操作。图中Channel表示一个连接通道,用于承载连接管理及读写操作;EventLoop则是事件处理的核心抽象。一个EventLoop可以服务于多个Channel,但它只会与单一线程绑定。EventLoop中所有I/O事件和用户任务的处理都在该线程上进行;其中除了选择器Selector的事件监听动作外,对连接通道的读写操作均以非阻塞的方式进行 —— 这是NIO与BIO(blocking I/O,即阻塞式I/O)的重要区别,也是NIO模式性能优异的原因
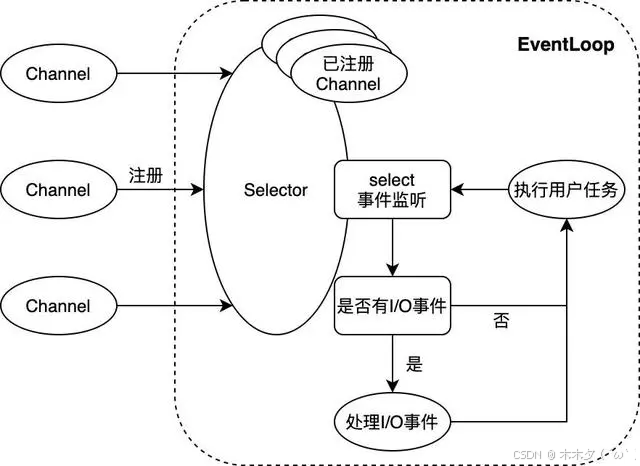
如此,Lettuce在保证请求处理顺序的基础上,天然地使用了管道模式(pipelining)与Redis交互 —— 在多个业务线程并发请求的情况下,客户端不必等待服务端对当前请求的响应,即可在同一个连接上发出下一个请求。这在一定程度上极大的加速了客户端处理请求的速度。而与之相对的,在没有显式指定使用管道模式的情况下,Jedis只能在处理完某个Redis连接上当前请求的响应后,才能继续使用该连接发起下一个请求。
阿里云redis
-
数据量较大的场景。
-
QPS压力较大的场景。
-
吞吐密集型应用场景。
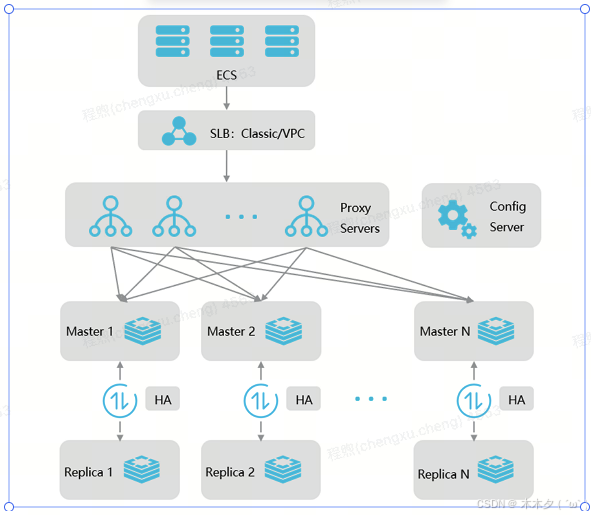
| 组件 | 说明 |
|---|---|
| 代理服务器(proxy servers) | 单节点配置,集群版结构中会有多个Proxy组成。 |
| 数据分片(data shards) | 双节点:每个数据分片均为双副本(分别部署在不同机器上)高可用架构,主节点发生故障后,系统会自动进行主备切换保证服务高可用。 |
| 单节点:没有备用节点,分片故障后,HA系统会在30s内拉起一个redis,来保证高可用,但原节点数据丢失 | |
| 配置服务器(config server) | 采用双副本高可用架构,用于存储集群配置信息及分区策略。对应了后端的云后台(云后台读取的就是config Server的信息)。 |
| 故障探测切换系统(HA) | 阿里云Redis服务封装HA切换系统,实时探测主节点的异常情况,可以有效解决磁盘IO故障,CPU故障等问题导致的服务异常,及时进行主从切换,从而保证服务高可用 |


















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









