







 本文介绍了如何通过分析京东网站的Ajax加载机制来高效地爬取商品列表信息,避免使用Selenium,采用requests或Scrapy即可实现快速爬取。
本文介绍了如何通过分析京东网站的Ajax加载机制来高效地爬取商品列表信息,避免使用Selenium,采用requests或Scrapy即可实现快速爬取。
由于京东运用ajax加载页面,正常的爬取页面不能获得全部页面内容,之前做过用Scrapy + Selenium实现京东商品列表摘要信息的爬取,今天又研究了一下其下拉后接口url的构造,终于发现了其中的奥秘!
先用谷歌浏览器请求网页:https://search.jd.com/Search?keyword=手机&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=手机&psort=4&page=7&s=181&click=0
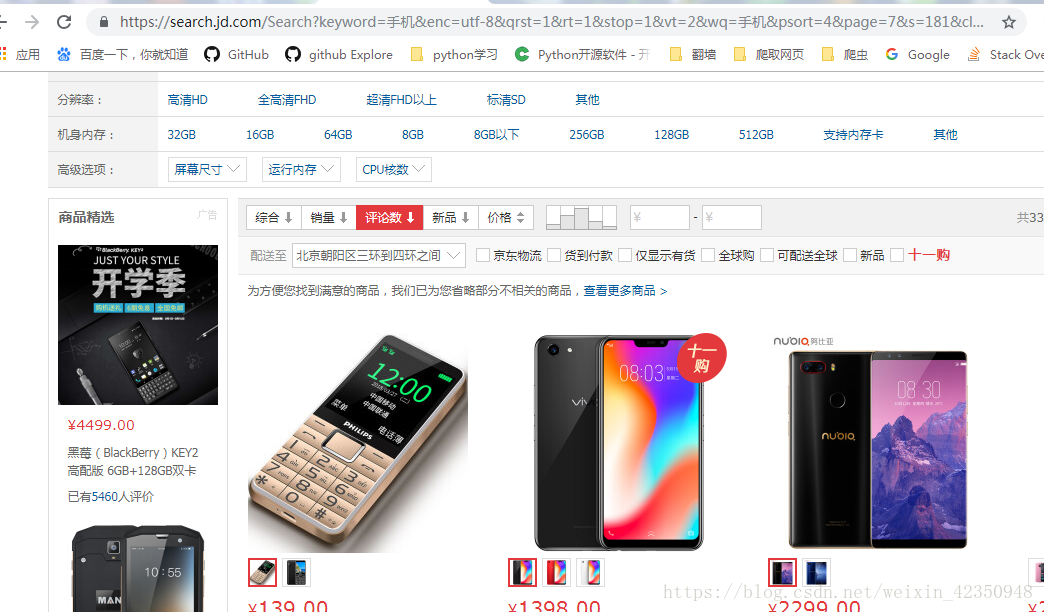
正常的爬取网页解析后只会显示30条商品:
而将滚动条滚动到最下面时,又会以ajax的形式加载出另外30条,通过Fildder抓包可以看到当额外的30条加载出来时,截获了一个包:

可以看到这个包的全部url为:
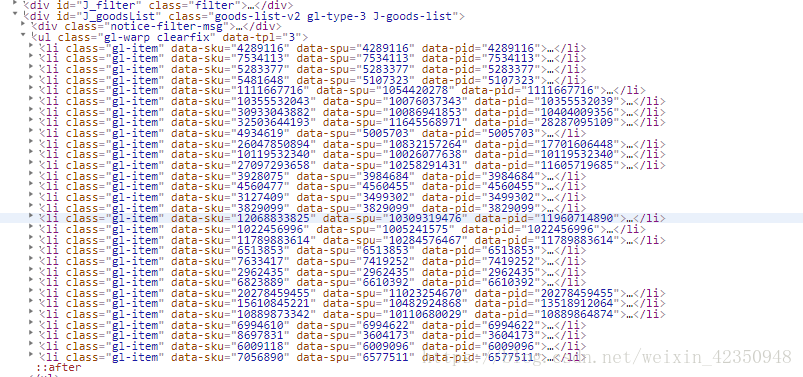
https://search.jd.com/s_new.php?keyword=%E6%89%8B%E6%9C%BA&enc=utf-8&qrst=1&rt=1&stop=1&vt=2&wq=%E6%89%8B%E6%9C%BA&psort=4&page=8&s=211&scrolling=y&log_id=1537268972.31844&tpl=3_M&show_items=4289116,7534113,5283377,5107323,1111667716,10355532039,10404009356,28287095109,5005703,17701606448,10119532340,11605719685,3984684,4560455,3499302,3829099,11960714890,1022456996,11789883614,6513853,7419252,2962435,6610392,20278459455,13518912064,10889864874,6994622,3604173,6009096,6577511
经过分析可以发现:第二次截获的ur有三处需要构造

经分析发现:
- 第一处不同为log_id其值应该是时间戳去掉最后两位即time.time()[:-2]
- 第二处为page是第一个页面请求的page+1
- 第三处为最后的一串数字的组成,查看前面第一张图中的data-pid标签发现,正是这前30个data-pid构成。
这样就大工告成了,就不需要用Selenium爬取了,可以用requests或者scrapy快速请求啦。
之前用Scray写过爬取的代码,这里就不放了,有需要的可以去github翻,希望能帮到大家!
GitHub地址:https://github.com/wangyeqiang/Crawl

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









