






 Hadoop是Apache基金会的分布式系统框架,核心包括HDFS和MapReduce。HDFS是分布式文件系统,采用异步复制,保证数据完整性。MapReduce用于大规模数据并行计算。YARN作为资源管理器,包含ResourceManager、ApplicationMaster和NodeManager,负责任务分配和集群资源管理。
Hadoop是Apache基金会的分布式系统框架,核心包括HDFS和MapReduce。HDFS是分布式文件系统,采用异步复制,保证数据完整性。MapReduce用于大规模数据并行计算。YARN作为资源管理器,包含ResourceManager、ApplicationMaster和NodeManager,负责任务分配和集群资源管理。
Hadoop是由apache基金会开发的,用于解决大数据存储与分析的分布式系统基础框架。其有两大核心:HDFS与MapReduce。
1. HDFS
HDFS(Hadoop Distributed File System)是可扩展、容错、高性能的分布式文件系统,异步复制,一次写入多次读取,主要负责存储。对于外部客户端来说,HDFS与Linux文件系统类似,像一个传统的分级文件系统。
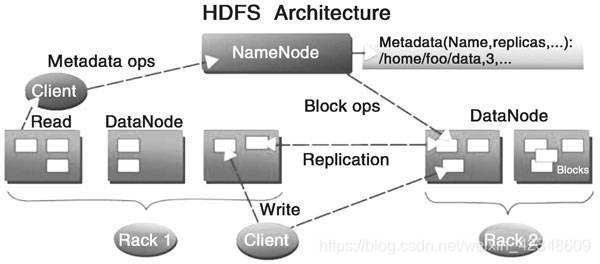
在HDFS中,名称节点(NameNode)负责管理文件系统的空间和控制外部客户机的访问。数据节点(DataNode)负责存储数据,文件在HDFS中被分成块(通常为128MB),存储在数据节点中。每一个数据块一般会保留三份,一份存在本地,一份存在同一机架的不同节点上,一份存在不同机架的某个节点上。名称节点会通过每个数据节点的定期心跳(heartbeat)消息验证各个数据节点的数据,若数据节点的数据缺失,会通过备份加以修复,以此保证数据的完整性。
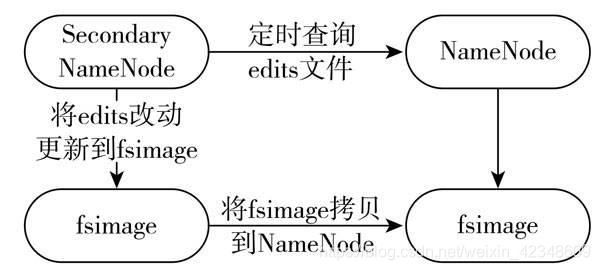
第二名称节点作用是为了给HDFS中的名称节点提供一个checkpoint。一般来说,只有当NameNode重启时,edits(NameNode启动后对文件系统的改动序列)才会合并到fsimage(NameNode启动时对文件系统的快照)中,从而得到一个文件系统的最新快照。但由于NameNode在生产环境中重启较少,若不进行处理,会导致edits越来越大,当发生宕机时,edits会丢失很多改动。所以借助第二名称节点,定时去获取edits同步到自身的fsimage中,并且当第二名称节点中的fsimage达到一定的阈值,会将此fsimage文件拷贝回NameNode,减少丢失操作的风险与重启时间。
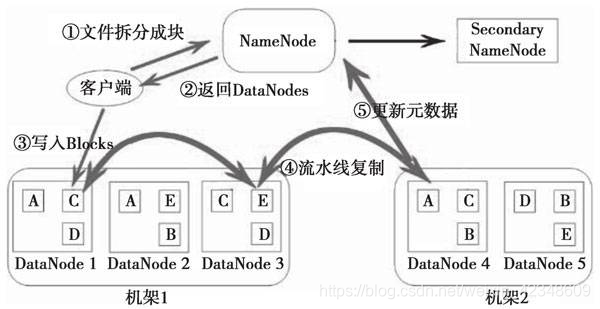
文件上传步骤:
- 客户端将文件按128MB分块
- 客户端向NameNode发送写数据请求
- NameNode记录各个DataNode信息,并返回可用的DataNode列表
- 客户端向DataNode流式写入文件
- 写入完成后,DataNode向NameNode发送消息,更新元数据
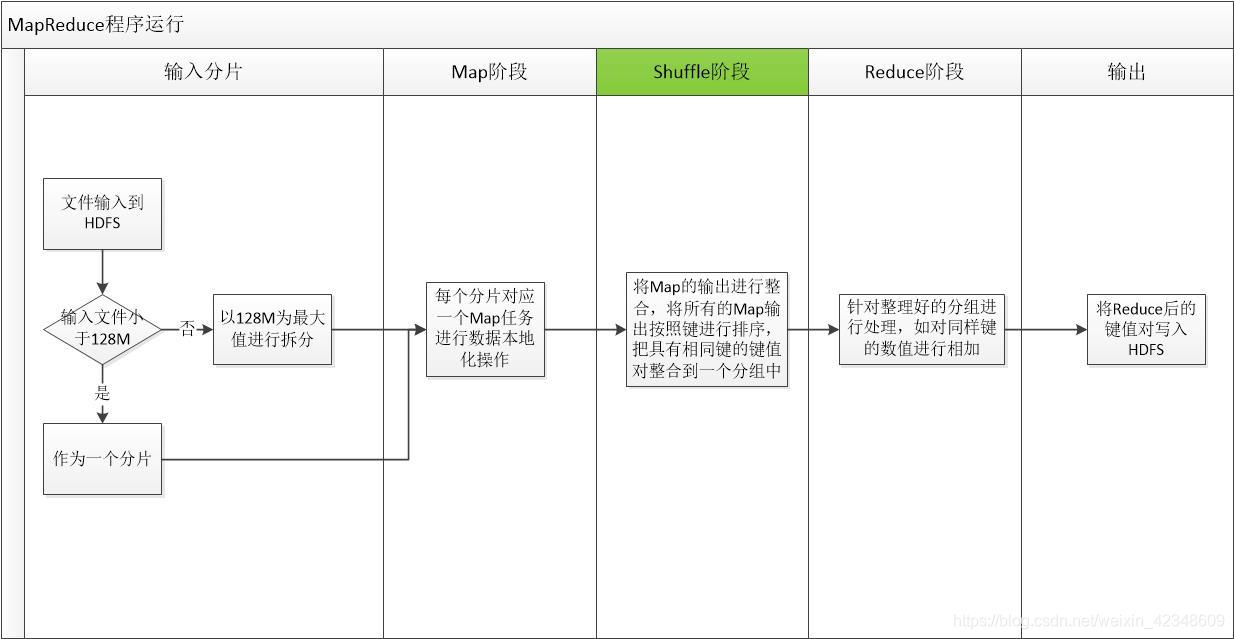
2. MapReduce
MapReduce是谷歌提出的一个软件框架,用于大规模数据的并行计算。
3. Hadoop资源管理YARN
YARN(Yet Another Resource Manager) 是一个任务分配和集群资源管理的框架。
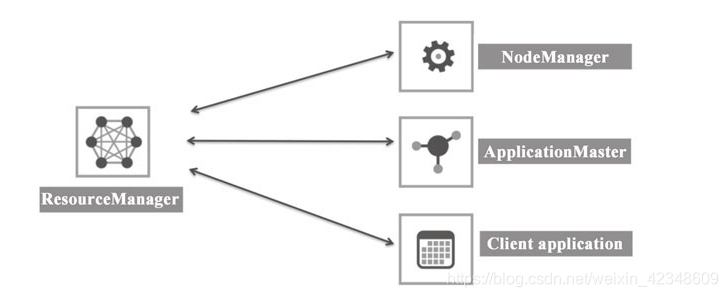
3.1 ResourceManager
ResourceManager是一个全局资源管理器,负责整个系统资源的管理和分配。其主要由:调度器和应用程序管理器组成。
调度器负责分配最少但满足应用程序运行所需的资源量给应用程序,但并不会监视应用程序的状态,不会处理失败的任务。
应用程序管理器负责处理客户端提交的job及协商一个container(内存、IO、网络等资源的抽象)供ApplicationMaster运行,并且在ApplicationMaster失败后重启ApplicationMaster。
3.2 ApplicationMaster
ApplicationMaster是一个框架的特殊库,每个Application有一个ApplicationMaster,用于监控和管理部署在YARN集群上的各种应用。
3.3 NodeManager
NodeManager主要负责启动ResourceManager分配给ApplicationMaster的container,并且监视container的运行情况,如果超出资源限制,终止container所代表的进程。

















 2004
2004

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









