




 本文探讨了如何通过正则化技术防止模型过拟合,并介绍了一种利用L1正则化减少模型复杂度和参数数量的方法。通过具体示例展示了如何在保持模型精度的同时,压缩模型大小以适应资源受限的设备。
本文探讨了如何通过正则化技术防止模型过拟合,并介绍了一种利用L1正则化减少模型复杂度和参数数量的方法。通过具体示例展示了如何在保持模型精度的同时,压缩模型大小以适应资源受限的设备。
特征组合:不要组合过度
简单正则化

添加模型复杂度惩罚项、结构风险最小化(简化模型)

L2正则化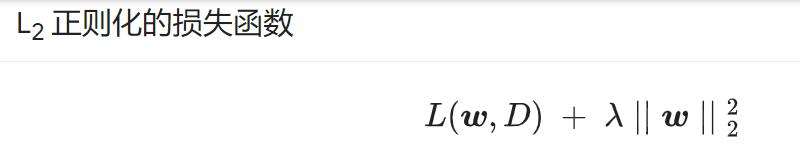
逻辑回归

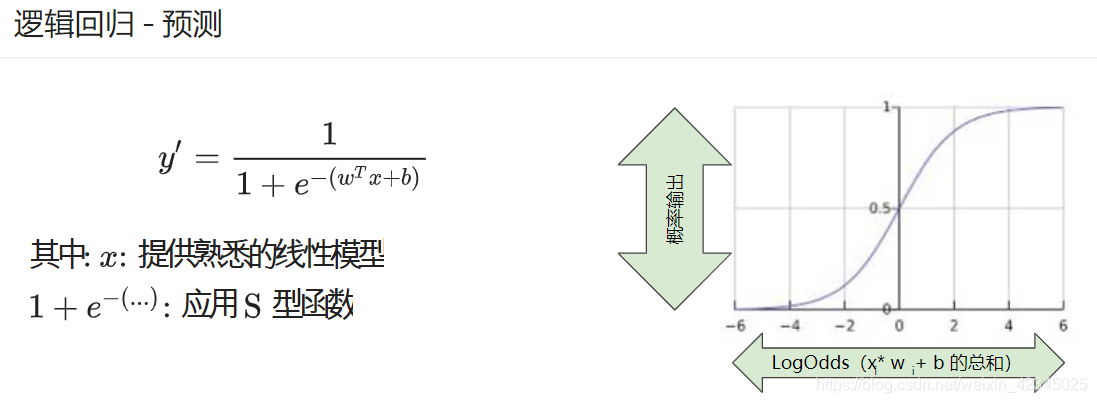
S型函数: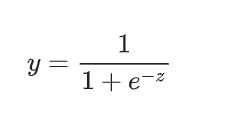 ,确保输出在0,1之间
,确保输出在0,1之间
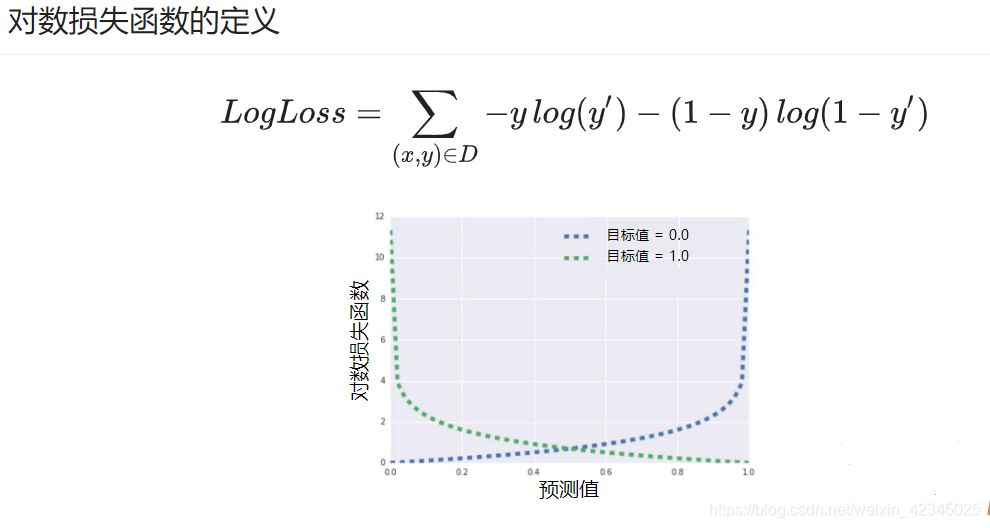
逻辑回归的损失函数:对数损失函数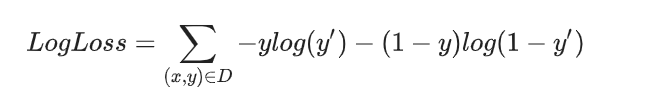
其中(x,y)为数据集,y为标签,y‘为预测值
分类:使用逻辑回归解决分类任务
评估指标:精确率与召回率

分类阈值
2X2混淆矩阵:

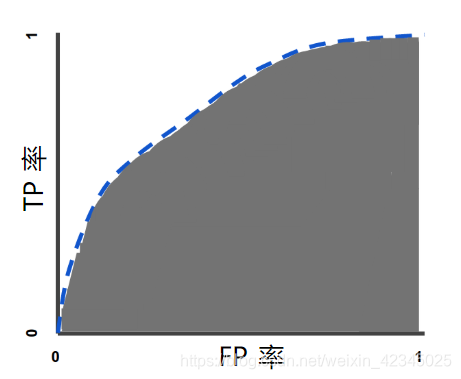
ROC和曲线下面积
预测偏差=预测平均值-相应标签平均值
造成预测偏差的可能原因包括:
- 特征集不完整
- 数据集混乱
- 模型实现流水线中有错误?
- 训练样本有偏差
- 正则化过强
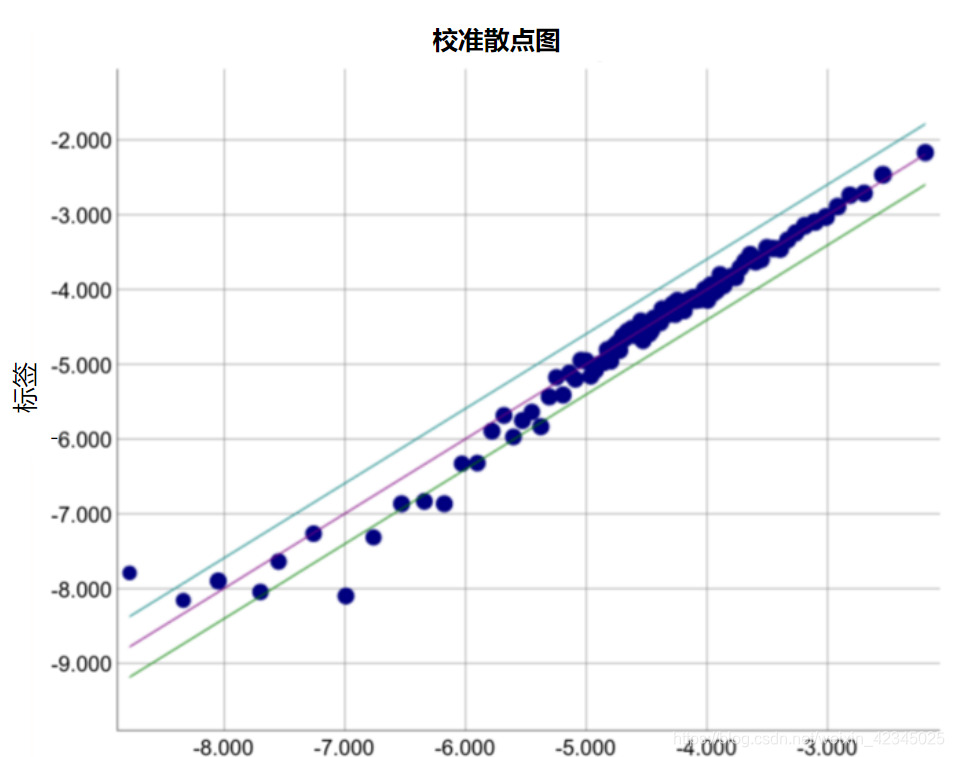
为什么只有模型的某些部分所做的预测如此糟糕?以下是几种可能性:
稀疏性正则化:L1正则化
L1 和 L2 正则化。
L2 和 L1 采用不同的方式降低权重:
- L2 会降低权重2。
- L1 会降低 |权重|。
因此,L2 和 L1 具有不同的导数:
- L2 的导数为 2 * 权重。
- L1 的导数为 k(一个常数,其值与权重无关)。
L1 正则化 - 减少所有权重的绝对值 - 证明对宽度模型非常有效。可将一些权重降为0
Google示例代码:python、tenserflow 关于L1正则化
from __future__ import print_function
import math
from IPython import display
from matplotlib import cm
from matplotlib import gridspec
from matplotlib import pyplot as plt
import numpy as np
import pandas as pd
from sklearn import metrics
import tensorflow as tf
from tensorflow.python.data import Dataset
tf.logging.set_verbosity(tf.logging.ERROR)
pd.options.display.max_rows = 10
pd.options.display.float_format = '{:.1f}'.format
california_housing_dataframe = pd.read_csv("https://download.mlcc.google.cn/mledu-datasets/california_housing_train.csv", sep=",")
california_housing_dataframe = california_housing_dataframe.reindex(
np.random.permutation(california_housing_dataframe.index))def preprocess_features(california_housing_dataframe):
"""Prepares input features from California housing data set.
Args:
california_housing_dataframe: A Pandas DataFrame expected to contain data
from the California housing data set.
Returns:
A DataFrame that contains the features to be used for the model, including
synthetic features.
"""
selected_features = california_housing_dataframe[
["latitude",
"longitude",
"housing_median_age",
"total_rooms",
"total_bedrooms",
"population",
"households",
"median_income"]]
processed_features = selected_features.copy()
# Create a synthetic feature.
processed_features["rooms_per_person"] = (
california_housing_dataframe["total_rooms"] /
california_housing_dataframe["population"])
return processed_features
def preprocess_targets(california_housing_dataframe):
"""Prepares target features (i.e., labels) from California housing data set.
Args:
california_housing_dataframe: A Pandas DataFrame expected to contain data
from the California housing data set.
Returns:
A DataFrame that contains the target feature.
"""
output_targets = pd.DataFrame()
# Create a boolean categorical feature representing whether the
# median_house_value is above a set threshold.
output_targets["median_house_value_is_high"] = (
california_housing_dataframe["median_house_value"] > 265000).astype(float)
return output_targets# Choose the first 12000 (out of 17000) examples for training.
training_examples = preprocess_features(california_housing_dataframe.head(12000))
training_targets = preprocess_targets(california_housing_dataframe.head(12000))
# Choose the last 5000 (out of 17000) examples for validation.
validation_examples = preprocess_features(california_housing_dataframe.tail(5000))
validation_targets = preprocess_targets(california_housing_dataframe.tail(5000))
# Double-check that we've done the right thing.
print("Training examples summary:")
display.display(training_examples.describe())
print("Validation examples summary:")
display.display(validation_examples.describe())
print("Training targets summary:")
display.display(training_targets.describe())
print("Validation targets summary:")
display.display(validation_targets.describe())def my_input_fn(features, targets, batch_size=1, shuffle=True, num_epochs=None):
"""Trains a linear regression model.
Args:
features: pandas DataFrame of features
targets: pandas DataFrame of targets
batch_size: Size of batches to be passed to the model
shuffle: True or False. Whether to shuffle the data.
num_epochs: Number of epochs for which data should be repeated. None = repeat indefinitely
Returns:
Tuple of (features, labels) for next data batch
"""
# Convert pandas data into a dict of np arrays.
features = {key:np.array(value) for key,value in dict(features).items()}
# Construct a dataset, and configure batching/repeating.
ds = Dataset.from_tensor_slices((features,targets)) # warning: 2GB limit
ds = ds.batch(batch_size).repeat(num_epochs)
# Shuffle the data, if specified.
if shuffle:
ds = ds.shuffle(10000)
# Return the next batch of data.
features, labels = ds.make_one_shot_iterator().get_next()
return features, labelsdef get_quantile_based_buckets(feature_values, num_buckets):
quantiles = feature_values.quantile(
[(i+1.)/(num_buckets + 1.) for i in range(num_buckets)])
return [quantiles[q] for q in quantiles.keys()]
def construct_feature_columns():
"""Construct the TensorFlow Feature Columns.
Returns:
A set of feature columns
"""
bucketized_households = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("households"),
boundaries=get_quantile_based_buckets(training_examples["households"], 10))
bucketized_longitude = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("longitude"),
boundaries=get_quantile_based_buckets(training_examples["longitude"], 50))
bucketized_latitude = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("latitude"),
boundaries=get_quantile_based_buckets(training_examples["latitude"], 50))
bucketized_housing_median_age = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("housing_median_age"),
boundaries=get_quantile_based_buckets(
training_examples["housing_median_age"], 10))
bucketized_total_rooms = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("total_rooms"),
boundaries=get_quantile_based_buckets(training_examples["total_rooms"], 10))
bucketized_total_bedrooms = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("total_bedrooms"),
boundaries=get_quantile_based_buckets(training_examples["total_bedrooms"], 10))
bucketized_population = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("population"),
boundaries=get_quantile_based_buckets(training_examples["population"], 10))
bucketized_median_income = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("median_income"),
boundaries=get_quantile_based_buckets(training_examples["median_income"], 10))
bucketized_rooms_per_person = tf.feature_column.bucketized_column(
tf.feature_column.numeric_column("rooms_per_person"),
boundaries=get_quantile_based_buckets(
training_examples["rooms_per_person"], 10))
long_x_lat = tf.feature_column.crossed_column(
set([bucketized_longitude, bucketized_latitude]), hash_bucket_size=1000)
feature_columns = set([
long_x_lat,
bucketized_longitude,
bucketized_latitude,
bucketized_housing_median_age,
bucketized_total_rooms,
bucketized_total_bedrooms,
bucketized_population,
bucketized_households,
bucketized_median_income,
bucketized_rooms_per_person])
return feature_columns计算模型大小:
def model_size(estimator):
variables = estimator.get_variable_names()
size = 0
for variable in variables:
if not any(x in variable
for x in ['global_step',
'centered_bias_weight',
'bias_weight',
'Ftrl']
):
size += np.count_nonzero(estimator.get_variable_value(variable))
return size减小模型大小
您的团队需要针对 SmartRing 构建一个准确度高的逻辑回归模型,这种指环非常智能,可以感应城市街区的人口统计特征(
median_income、avg_rooms、households等等),并告诉您指定城市街区的住房成本是否高昂。由于 SmartRing 很小,因此工程团队已确定它只能处理参数数量不超过 600 个的模型。另一方面,产品管理团队也已确定,除非所保留测试集的对数损失函数低于 0.35,否则该模型不能发布。
您可以使用秘密武器“L1 正则化”调整模型,使其同时满足大小和准确率限制条件吗?
任务 1:查找合适的正则化系数。
查找可同时满足以下两种限制条件的 L1 正则化强度参数:模型的参数数量不超过 600 个且验证集的对数损失函数低于 0.35。
以下代码可帮助您快速开始。您可以通过多种方法向您的模型应用正则化。在此练习中,我们选择使用
FtrlOptimizer来应用正则化。FtrlOptimizer是一种设计成使用 L1 正则化比标准梯度下降法得到更好结果的方法。重申一次,我们会使用整个数据集来训练该模型,因此预计其运行速度会比通常要慢。
def train_linear_classifier_model(
learning_rate,
regularization_strength,
steps,
batch_size,
feature_columns,
training_examples,
training_targets,
validation_examples,
validation_targets):
"""Trains a linear regression model.
In addition to training, this function also prints training progress information,
as well as a plot of the training and validation loss over time.
Args:
learning_rate: A `float`, the learning rate.
regularization_strength: A `float` that indicates the strength of the L1
regularization. A value of `0.0` means no regularization.
steps: A non-zero `int`, the total number of training steps. A training step
consists of a forward and backward pass using a single batch.
feature_columns: A `set` specifying the input feature columns to use.
training_examples: A `DataFrame` containing one or more columns from
`california_housing_dataframe` to use as input features for training.
training_targets: A `DataFrame` containing exactly one column from
`california_housing_dataframe` to use as target for training.
validation_examples: A `DataFrame` containing one or more columns from
`california_housing_dataframe` to use as input features for validation.
validation_targets: A `DataFrame` containing exactly one column from
`california_housing_dataframe` to use as target for validation.
Returns:
A `LinearClassifier` object trained on the training data.
"""
periods = 7
steps_per_period = steps / periods
# Create a linear classifier object.
my_optimizer = tf.train.FtrlOptimizer(learning_rate=learning_rate, l1_regularization_strength=regularization_strength)
my_optimizer = tf.contrib.estimator.clip_gradients_by_norm(my_optimizer, 5.0)
linear_classifier = tf.estimator.LinearClassifier(
feature_columns=feature_columns,
optimizer=my_optimizer
)
# Create input functions.
training_input_fn = lambda: my_input_fn(training_examples,
training_targets["median_house_value_is_high"],
batch_size=batch_size)
predict_training_input_fn = lambda: my_input_fn(training_examples,
training_targets["median_house_value_is_high"],
num_epochs=1,
shuffle=False)
predict_validation_input_fn = lambda: my_input_fn(validation_examples,
validation_targets["median_house_value_is_high"],
num_epochs=1,
shuffle=False)
# Train the model, but do so inside a loop so that we can periodically assess
# loss metrics.
print("Training model...")
print("LogLoss (on validation data):")
training_log_losses = []
validation_log_losses = []
for period in range (0, periods):
# Train the model, starting from the prior state.
linear_classifier.train(
input_fn=training_input_fn,
steps=steps_per_period
)
# Take a break and compute predictions.
training_probabilities = linear_classifier.predict(input_fn=predict_training_input_fn)
training_probabilities = np.array([item['probabilities'] for item in training_probabilities])
validation_probabilities = linear_classifier.predict(input_fn=predict_validation_input_fn)
validation_probabilities = np.array([item['probabilities'] for item in validation_probabilities])
# Compute training and validation loss.
training_log_loss = metrics.log_loss(training_targets, training_probabilities)
validation_log_loss = metrics.log_loss(validation_targets, validation_probabilities)
# Occasionally print the current loss.
print(" period %02d : %0.2f" % (period, validation_log_loss))
# Add the loss metrics from this period to our list.
training_log_losses.append(training_log_loss)
validation_log_losses.append(validation_log_loss)
print("Model training finished.")
# Output a graph of loss metrics over periods.
plt.ylabel("LogLoss")
plt.xlabel("Periods")
plt.title("LogLoss vs. Periods")
plt.tight_layout()
plt.plot(training_log_losses, label="training")
plt.plot(validation_log_losses, label="validation")
plt.legend()
return linear_classifier解决方案:正则化强度0.1(正则化越强,模型越小,会影响分类损失)
linear_classifier = train_linear_classifier_model(
learning_rate=0.1,
regularization_strength=0.1,
steps=300,
batch_size=100,
feature_columns=construct_feature_columns(),
training_examples=training_examples,
training_targets=training_targets,
validation_examples=validation_examples,
validation_targets=validation_targets)
print("Model size:", model_size(linear_classifier))

















 7159
7159

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









