







 本文详细介绍了Hadoop高可用(HA)架构的设计原理与部署流程,包括使用JournalNode和ZooKeeper来确保NameNode服务的高可用性,以及在多节点环境下如何实现服务的冗余与自动切换。
本文详细介绍了Hadoop高可用(HA)架构的设计原理与部署流程,包括使用JournalNode和ZooKeeper来确保NameNode服务的高可用性,以及在多节点环境下如何实现服务的冗余与自动切换。
Hadoop HA 架构
准备阿里云环境
在之前已经准备好了3台阿里云按时按量计费服务器服务器,

为什么要使用集群
正在全面的博客中,在学习过程中使用的都是hadoop的伪分布式部署,只有1台服务器,每一个服务有且只有一个进程
但是如果生产环境HDFS的NameNode节点或者ResourceManager进程夯死或宕掉,生产服务即终止对外停止
使用HA集群架构,每个服务都有至少两个或两个以上的进程节点,使单节点宕机而不至于停止对外服务
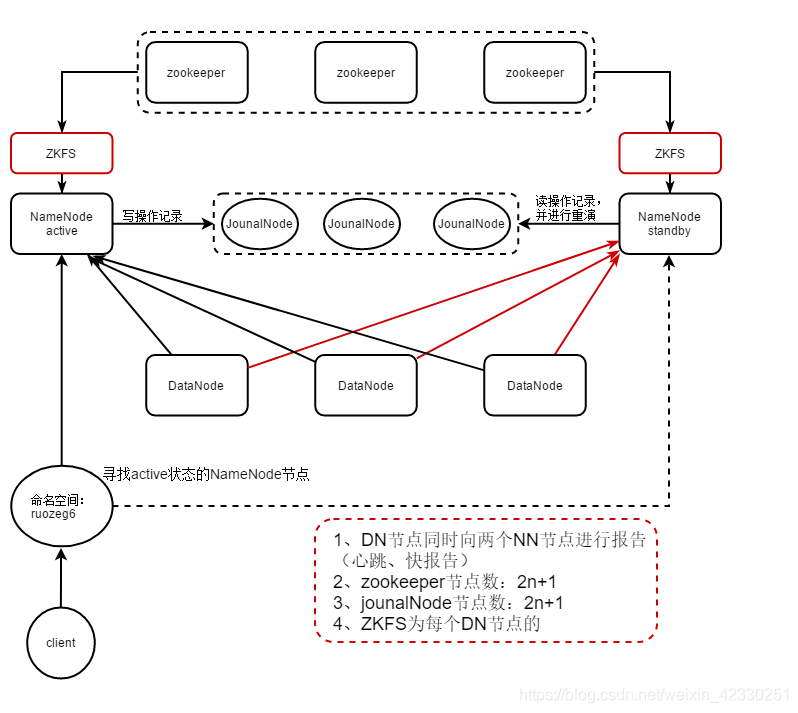
- HA架构是为了解决单点问题
- 通过JN集群共享状态
- 通过ZKFC选举active
- 监控状态,自动备援
HA环境架构
- 我准备了三台阿里云服务器,上图所有内容分布在三台服务器上,环境进程部署情况
进程部署情况
| Hadoop001 | zookeeper | NN | ZKFC | JN | DN |
| Hadoop002 | zookeeper | NN | ZKFC | JN | DN |
| Hadoop003 | zookeeper | - | - | JN | DN |
1、在HA架构中,我们放弃了SecondaryNameNode(后面简称:SNN),从而部署两个NameNode节点进行实时同步
2、两个NameNode(下面简称:NN)中只有一个active状态节点提供服务,一个standby状态节点待提供服务
- DN同时向两个NN发送心跳和快报告
ACTIVE NN: 操作记录写道自己的editlog,同时写JN集群,接收DN的心跳和快报告 - Standby NN: 同时接受JN集群的日志,显示读取执行log操作(重演),是的自己的元数据和active NN节点保持一致,并同时接收DN的心跳和块报告
- JounalNode:用于active standby NN节点的同步数据,一般部署2n+1个节点
- ZKFC:单独的进程,监控NN的健康状态,向ZK集群顶起发送心跳,是的自己可以被选举;当自己被ZK集群选举为active状态时,zkfc进程通过RPC协议使NN节点的状态变为active,从而对外提供服务,这个过程使无感知的。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









