







 本文记录了一次Oracle 11.2.0.4 RAC数据库在Redhat 6.9上遇到的业务连接异常事件。故障发生时,数据库在执行统计信息收集任务时出现错误12751,导致MMON进程异常,AWR报告缺失,严重影响数据库性能。二节点在主节点停机后尝试接管业务,但由于光纤链路问题和ASM磁盘组异常,导致数据库实际上不可用。最终通过拔掉一根光纤解决问题。建议进行光纤故障分析、数据库补丁升级和深度巡检。
本文记录了一次Oracle 11.2.0.4 RAC数据库在Redhat 6.9上遇到的业务连接异常事件。故障发生时,数据库在执行统计信息收集任务时出现错误12751,导致MMON进程异常,AWR报告缺失,严重影响数据库性能。二节点在主节点停机后尝试接管业务,但由于光纤链路问题和ASM磁盘组异常,导致数据库实际上不可用。最终通过拔掉一根光纤解决问题。建议进行光纤故障分析、数据库补丁升级和深度巡检。
第一部分 背景
晚上接到客户反馈,一套Oracle11.2.0.4 rac for redhat6.9数据库业务连接异常,第一时间介入,于当晚紧急处理,并恢复数据库正常运行。随后对数据库相关日志进行分析,定位此次发生故障原因,并提出相关建议。
第二部分 故障分析
从数据库的日志来看:
晚上接到客户反馈,一套Oracle11.2.0.4 rac for redhat6.9数据库业务连接异常,第一时间介入,于当晚紧急处理,并恢复数据库正常运行。随后对数据库相关日志进行分析,定位此次发生故障原因,并提出相关建议。
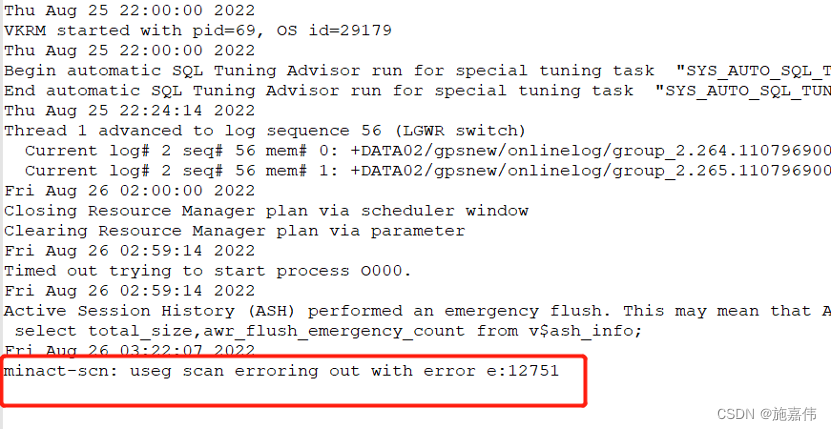
晚上02:00:00 数据库开始自动任务,收集统计信息。
晚上03:22:07 数据库报错:minact-scn: useg scan erroring out with error e:12751。这个报错意思是:当数据库中存在长和大的事务时,MMON开始强烈(aggressively)扫描undo表空间,导致错误和不能生成AWR。MMON进程与AWR直接相关,这个进程负责为AWR(Automatic Workload Repository)收集数据。当存在大量后台任务等待服务的队列或服务器资源耗尽的情况时,MMON可能会暂停操作。
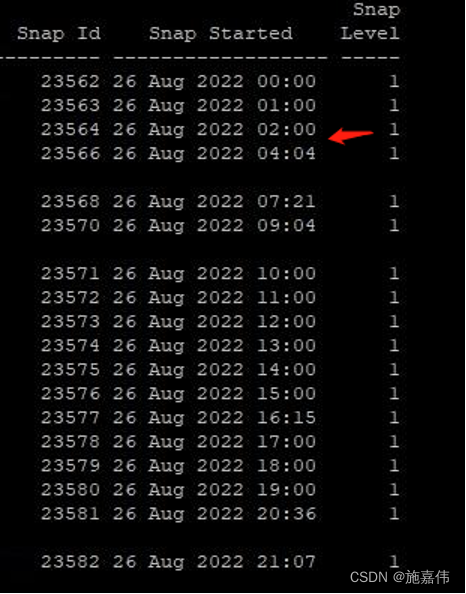
可以看到awr 报告缺失三点的部分。后续五点的awr 也无法生成。说明此段时间数据库十分繁忙,由于缺少相关快照,后当时时间内没有人能查看数据库相关状态,所以此段时间内数据库发生了什么无法排查。但是数据库在如此繁忙的情况下影响正常连接,也是合理的。
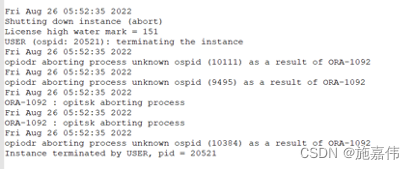
现场发生无法连接后,05:52:35对数据库进行关机并重启。随后大约在06:11:51左右机器重启起来,从数据库集群日志来看,由于gpnp 进程异常,直到07:07左右数据库才完全启动。
而这段时间数据库二节点的情况是这样的:
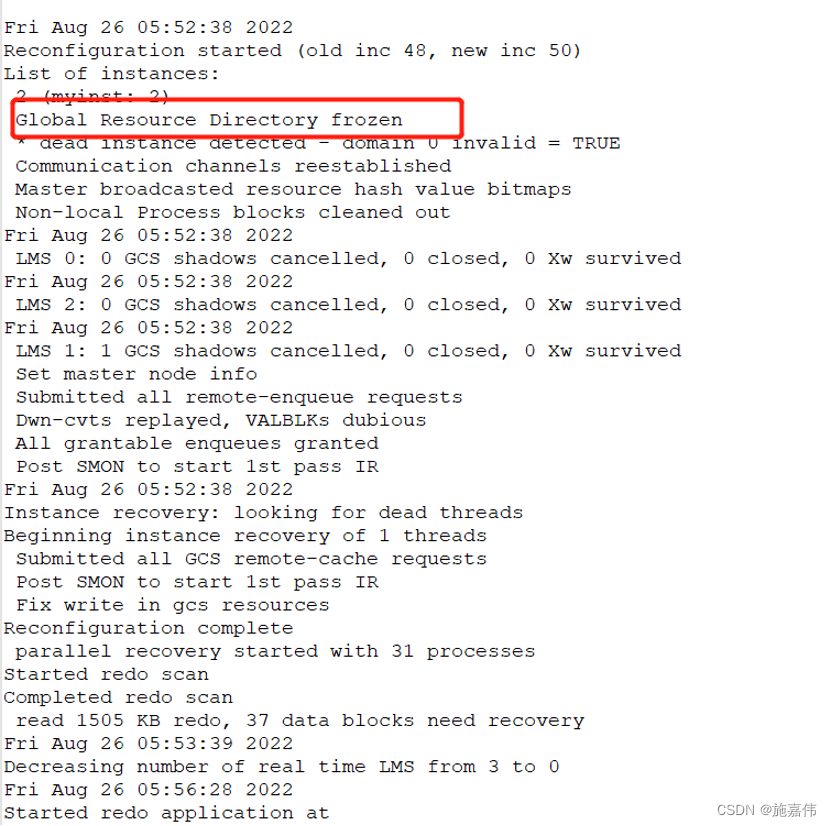
在一节点的停机后约3秒,二节点开始资源重组,随后接管业务。但是由于二节点的部分光纤链路异常,二节点无法满足接管业务的需求。
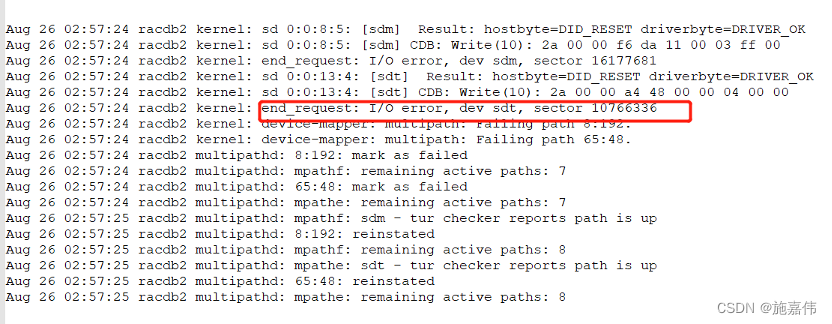
从操作系统日志可以看出,在当天凌晨,系统就报错了io 错误。
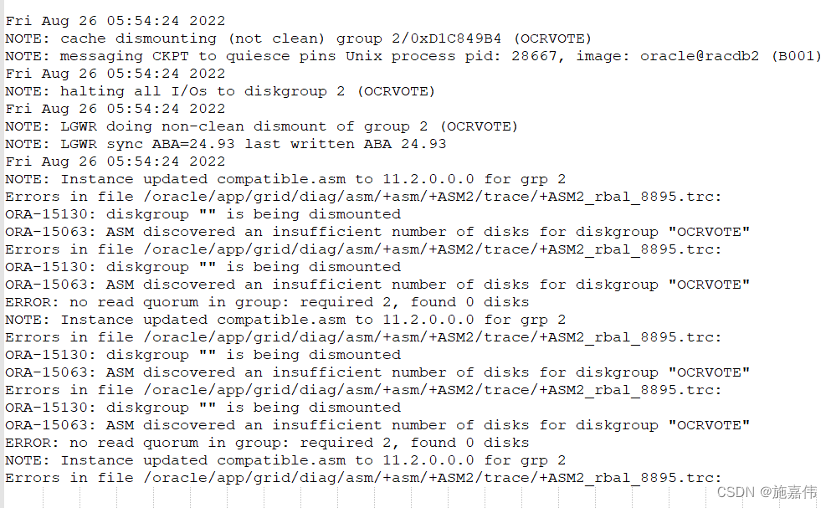
在接管业务没多久,数据库asm磁盘组就异常了。导致表面上看数据库是open 状态,实际数据库不可用。
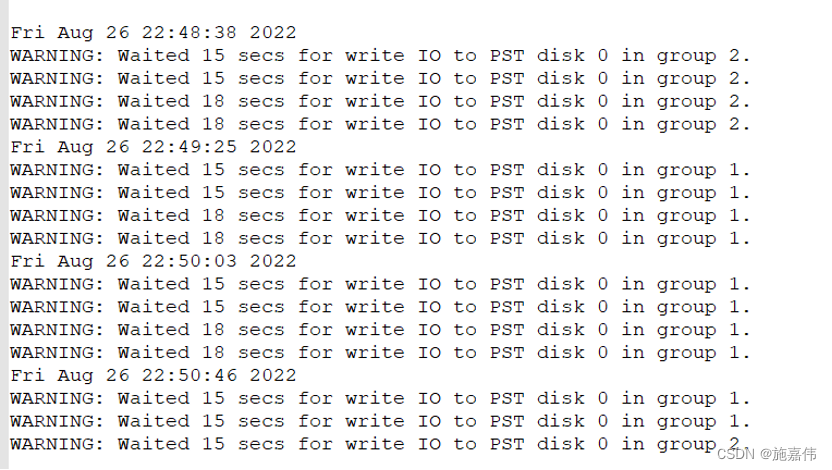
直到美创工程师处理故障的时候,拉起二节点数据库,asm 实例还在报磁盘心跳超时。在沟通中,现场人员拔掉了一根光纤。随后数据库恢复正常连接。在今天的测试中,也发现,当插入那根光纤后系统日志会报io错误。
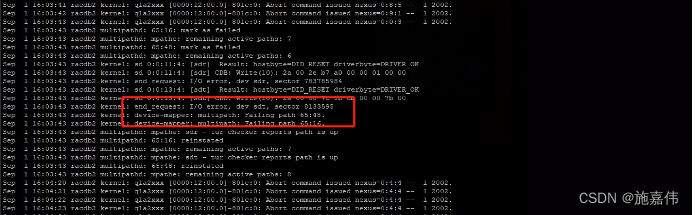
至于为啥,数据库在停机过程中多次出现无法关闭或者无法拉起的情况,根据相关数据库日志来看:
- ORA-01089: immediate shutdown in progress - no operations are permitted
关库的时候,数据库还有连接未释放 - kkjcre1p: unable to spawn jobq slave process, slot 0, error 1089
命中Oracle bug23102157 - ORA-00600: internal error code, arguments: [4194], [], [], [], [], [], [], [], [], [], [], []
暴力关机导致undo 损坏
第三部分 总结
从本次故障的事后日志分析来看,是由多重因素导致整个集群故障的出现。但是在故障发生前没无法获取有效的数据库状态和业务当时连接数据库的异常报错,导致数据库连接异常问题无法得到有效分析,在分析故障中我们发现数据库未打补丁,且部分参数需要分析后在进行优化。
第四部分 建议
- 建议对那条光纤进行故障分析
- 建议数据库进行补丁升级
- 建议对数据库进行一次深度巡检,并对部分参数进行


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









