









文章目录
这是一个关于如何使用TorchServe部署预先训练的HuggingFace Sentence transformers模型的指南。
任务:语义相似度(回归)
算法模型:Sentence BERT
预训练模型:TinyBERT_L6_ch
框架:torch 1.11
系统环境:Ubuntu 20.04 (云服务器 CPU)
1 获取模型
模型的渠道来自2方面
- 直接获取预训练模型
在huggingface transformers官网上,可以下载相关的预训练模型。 - 在任务数据集上微调后的模型
在本地数据集进行微调后,保存更好效果的模型,得到模型以及配置文件。
from sentence_transformers import SentenceTransformer
smodel = SentenceTransformer(model_dir_path)
smodel.save('model_name')
得到:
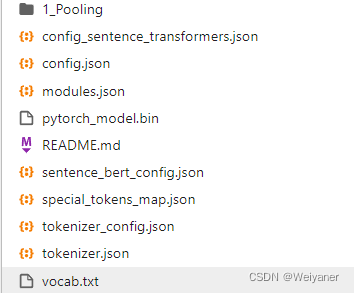
主要是使用里面的三个文件,分别是pytorch_model.bin,config.json,vocab.txt。
2 安装torchserve
TorchServe 由 Java 实现,因此需要最新版本的 OpenJDK 来运行。
apt install openjdk-11-jdk
如果win环境,手动安装参考这里:https://blog.youkuaiyun.com/qq_41873673/article/details/108027074
接下来,为了保证一个干净的环境,为 TorchServe 创建一个新 Conda 环境并激活。
conda create -n torchserve
source activate torchserve
接下来安装 TorchServe 的依赖项。
conda install sentencepiece torch-model-archiver psutil pytorch torchserve torchvision torchtext
如果要使用 GPU 实例,则需要额外的软件包。
conda install cudatoolkit=10.1
现在依赖项已安装完毕,可以克隆TorchServe 存储库。
git clone https://github.com/pytorch/serve.git
cd serve
环境设置完成,接下来继续模型封装。
3 封装模型和接口
封装模型和接口之前需要准备好模型和接口文件
3.1 准备模型
在serve 目录下新建一个文件夹,用来保存上面三个模型相关的文件。
mkdir Transformer_model/TinyBERT_L6_ch
mv pytorch_model.bin vocab.txt config.json Transformer_model/TinyBERT_L6_ch/
3.2 准备接口文件
Handler可以是TorchServe的内置处理器名称或py文件的路径,以处理定制的TorchServe推理逻辑。主要分成三部分,分别是preprocess,inference和postprocess,代表数据的处理,模型推理以及后处理三部分。
TorchServe库支持以下处理程序:image_classifier, object_detector, text_classifier, image_segmenter。
对于语义相似度任务没有配套接口,需要根据个人数据编写。
handler.py
import json
import zipfile
from json import JSONEncoder
import numpy as np
import os
class NumpyArrayEncoder(JSONEncoder):
def default(self, obj):
if isinstance(obj, np.ndarray):
return obj.tolist()
return JSONEncoder.default(self, obj)
class SentenceTransformerHandler(object):
def __init__(self):
super(SentenceTransformerHandler, self).__init__()
self.initialized = False
self.embedder = None
def initialize(self, context):
properties = context.system_properties
model_dir = properties.get("model_dir")
self.embedder = SentenceTransformer(model_dir)
self.initialized = True
def preprocess(self, data):
##
inputs = data[0].get("data")
if inputs is None:
inputs = data[0].get("body")
inputs = inputs.decode('utf-8')
inputs = json.loads(inputs)
sentences= inputs['queries']
return sentences
def inference(self, data):
query_embeddings = self.embedder.encode(data)
return query_embeddings
def postprocess(self, data):
return [json.dumps(data,cls=NumpyArrayEncoder)]
然后通过run_handler.py调用,作为接口
run_handler.py
from handler import SentenceTransformerHandler
_service = SentenceTransformerHandler()
def handle(data, context):
"""
Entry point for SentenceTransformerHandler handler
"""
try:
if not _service.initialized:
print('ENTERING INITIALIZATION')
if data is None:
return None
data = _service.preprocess(data)
data = _service.inference(data)
data = _service.postprocess(data)
return data
except Exception as e:
raise Exception("Unable to process input data. " + str(e))
3.3 封装
在TinyBERT_L4_ch文件夹下,执行封装命令
三个模型文件
1. 模型参数文件(torch) pytorch_model.bin
2. 模型配置文件config.json
3. 词表 vocab.txt 中文21128,英文30522
两个接口文件:
1. handler.py 定义接口函数
2. run_handler.py 调用上面定义的接口类,作为handler传入
封装模型和接口
torch-model-archiver --model-name sbert_tiny4ch \
--version 1.0 \
--serialized-file pytorch_model.bin \
--export-path /root/weiyan/serve/model_store \
--handler run_handler.py \
--extra-files "handler.py,config.json,vocab.txt" \
--runtime python3 -f
封装命令
torch-model-archiver --model-name sbert_tiny4ch --version 1.0 --serialized-file pytorch_model.bin --export-path /root/weiyan/serve/model_store --handler run_handler.py --extra-files "handler.py,config.json,vocab.txt" --runtime python3 -f
在model-store文件夹得到一个sbert_tiny4ch.mar文件。
4 部署模型
4.1 启动torchserve
在serve目录下,新建一个文件夹,存放配置文件config.properties,记录关于模型路径以及文件名称。
mkdir Configs
vi sbert_tiny4_config.properties
sbert_tiny4_config.properties
model_store=/root/weiyan/serve/model_store
load_models=sbert_tiny4ch.mar
启动torchserve
torchserve --ncs --start --ts-config sbert_tiny4_config.properties
然后打印出一系列模型信息
中间如果没有报错,则说明模型部署成功。
4.2 模型推理
使用相关命令查看模型部署情况
1.ping连接状态
curl http://localhost:8080/ping
{
"status": "Healthy"
}
2.模型加载情况
curl http://localhost:8081/models
{
"models": [
{
"modelName": "sbert_tiny4ch",
"modelUrl": "sbert_tiny4ch.mar"
}
]
}
4.3 语义相似度推理
由于SBERT对于querys进行了embeddings表达,所以模型的输出也是embeddings,计算二者的相似度可以在上文的handler.py文件中进行,也可以在获取到推理结果即embeddings之后,再次进行操作。
这里选择后计算相似度
sbert_tiny4ch.py
import requests
import json
from scipy import spatial
sentences = ['我去滑雪',"我要去滑雪"]
data = {'data':json.dumps({'queries':sentences})}
print(data)
response = requests.post('http://localhost:8080/predictions/sbert_tiny4ch',data = data)
print(response)
if response.status_code==200:
vectors = response.json()
sim = 1 - (spatial.distance.cosine(vectors[0], vectors[1]))
print('相似度为:',sim)
执行脚本
python sbert_tiny4ch.py
返回相似度结果
{'data': '{"queries": ["\\u4eca\\u5929\\u53bb\\u6ed1\\u96ea", "\\u6211\\u8981\\u53bb\\u6ed1\\u51b0"]}'}
<Response [200]>
相似度为: 0.9452057554006862
相关报错及解决办法
查询结果404
报错
{
"code": 404,
"type": "ResourceNotFoundException",
"message": "Requested resource is not found, please refer to API document."
}
原因:
使用错了端口,一共三个端口8080,8081,8082,实在不行都试一下。
一般,:8080/predictions。
查看models使用8081。
ping使用8080
查询结果503
prediction错误,一般是封装模型和接口的时候出错,我的经验就是handler.py其中的process函数写错,导致处理数据出现问题,自然就没法返回推理结果。
一般模型都是在本地进行测试后才会部署上线,所以务必保证模型文件本身没有错误。
查看logs
在运行torchserve的目录下,会生成一个logs文件夹,里面自动保存着一些logs,其中model.logs保存着模型的运行信息,包括上面errors的相信信息,可以回溯日志查看,具体什么模型什么错误。
/tmp/models
文件夹下保存着最新运行的模型文件,也就是
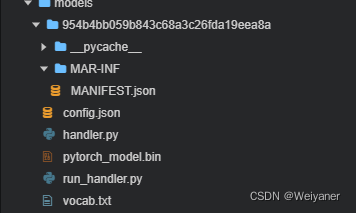



















 470
470

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











