







下一篇从Attention到Bert——2 transformer解读
文章目录
最早,attention诞生于CV领域,真正将其发杨光大的还是在NLP领域,自2018年Google的bert和OPENAI的GPT大火之后,大家才开始注意到背后的transformer以及Attention。
1 Attention的发展历史
Attention 的发展可以粗暴地分为两个阶段。
ref from:https://zhuanlan.zhihu.com/p/77307258
2015-2017年
自从 attention 提出后,基本就成为 NLP 模型的标配,各种各样的花式 attention 铺天盖地。不仅在 Machine Translation,在 Text summarization,Text Comprehend(Q&A), Text Classification 也广泛应用。奠定基础的几篇文章如下:
2015年 ICLR 《Neural machine translation by jointly learning to align and translate》首次提出 attention(基本上算是公认的首次提出),文章提出了最经典的 Attention 结构(additive attention 或者 又叫 bahdanau attention)用于机器翻译,并形象直观地展示了 attention 带来源语目标语的对齐效果,解释深度模型到底学到了什么,人类表示服气。
2015年 EMNLP 《Effective Approaches to Attention-based Neural Machine Translation》在基础 attention 上开始研究一些变化操作,尝试不同的 score-function,不同的 alignment-function。文章中使用的 Attention(multiplicative attention 或者 又叫 Luong attention)结构也被广泛应用。
2015年 ICML 《Show, Attend and Tell: Neural Image Caption Generation with Visual Attention》是 attention(提出hard/soft attention的概念)在 image caption 上的应用,故事圆满,符合直觉,人类再次表示很服气。
在上面几篇奠基之作之上,2016和2017年 attention 开枝散叶,无往不利。Hiearchical Attention,Attention over Attention,multi-step Attention……这些或叫得上名的或叫不上名。
2017年-至今是属于 transformer 的时代。基于 transformer 强大的表示学习能力,NLP 领域爆发了新一轮的活力,BERT、GPT 领跑各项 NLP 任务效果。奠基之作无疑是:
2017年 NIPS《Attention is all you need》提出 transformer 的结构(涉及 self-attention,multi-head attention)。基于 transformer 的网络可全部替代sequence-aligned 的循环网络,实现 RNN 不能实现的并行化,并且使得长距离的语义依赖与表达更加准确(据说2019年的 transformer-xl《Transformer-XL:Attentive Lanuage Models Beyond a fixed-length context》通过片段级循环机制结合相对位置编码策略可以捕获更长的依赖关系)。
2 Attention的原理
Attention 经常会和 Encoder–Decoder 一起说。
参见《一文看懂 NLP 里的模型框架 Encoder-Decoder 和 Seq2Seq》
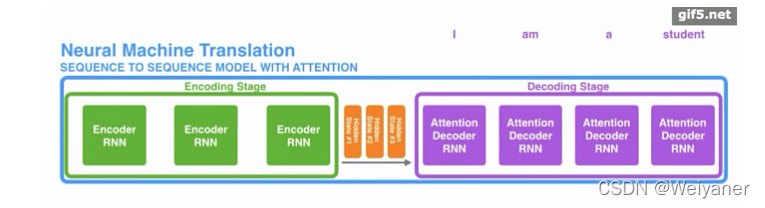
但是,Attention 并不一定要在 Encoder-Decoder 框架下使用的,他是可以脱离 Encoder-Decoder 框架的。
下面的图片则是脱离 Encoder-Decoder 框架后的原理图解。
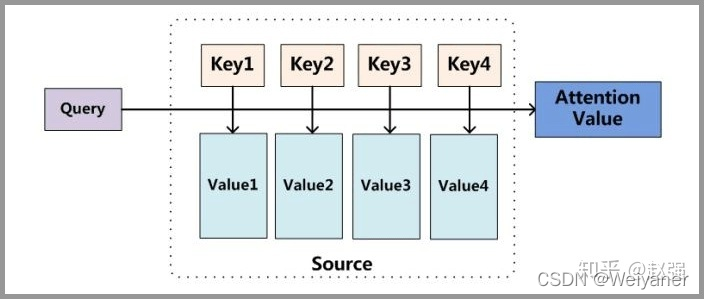
Attention 原理的3步分解:
可以描述query为将查询和一组键key值value对映射到输出y,其中查询、键、值和输出都是向量。输出是作为值的加权和计算的,其中分配给每个值的权重是通过查询与相应键的兼容性函数计算的。
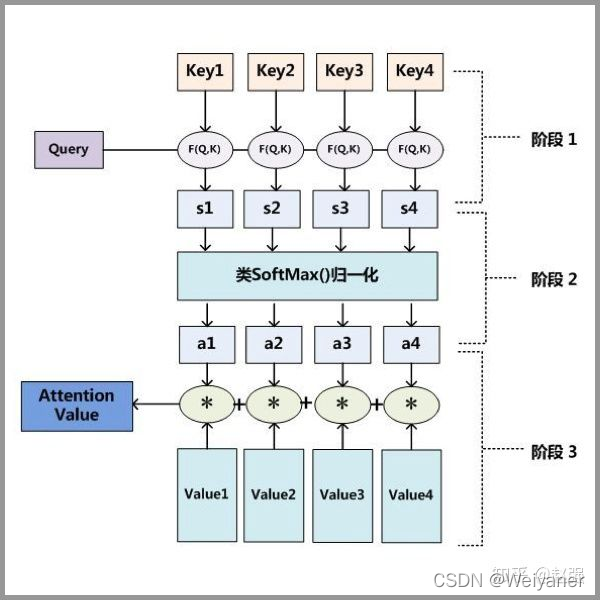
-
第一步: query 和 key 进行相似度计算,得到权值
相似度计算有多种,最简单就是
点乘、矩阵相乘: s ( p , q ) = q T k s(p,q)=q^Tk s(p,q)=qTk
cos函数: s ( q , k ) = q T k ∥ q ∥ ⋅ ∥ k ∥ s(q, k)=\frac{q^{T} k}{\|q\| \cdot\|k\|} s(q,k)=∥q∥⋅∥k∥qTk -
第二步:将权值进行归一化,得到直接可用的权重
α i = softmax ( s ( k i , q ) ) \alpha_{i}=\operatorname{softmax}\left(s\left(k_{i}, q\right)\right) αi=softmax(s(ki,q)) -
第三步:将权重和 value 进行加权求和。
a t t ( q , k , v ) = ∑ i = 1 N α i v i att(q,k,v)=\sum^{N}_{i=1}\alpha_iv_i att(q,k,v)=i=1∑Nαivi
这也就是文中提到的Scaled Dot-Product Attention。
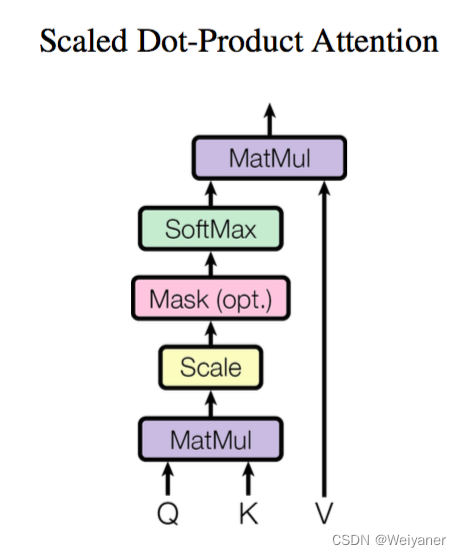
由此推出Attention的公式:
Attention
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











