







在上文中,总结了深度学习时代以来的推荐算法发展,主要集中于特征工程上的突破,在尝试了各类型的特征交叉方法之后,似于特征工程对于模型的提升已经到了一个瓶颈期,所以更多的开始寻求结构上的突破,将人工智能其他领域成熟的模型结构引入推荐系统领域中,诸如“注意力机制”,序列模型,强化学习等等。
1 ACF,DIN——注意力机制在推荐上的应用
注意力机制在NLP和语音识别上的成功使得研究者开始考虑其在推荐系统上面的表现。2017年开始,浙大和阿里分别提出了AFM和DIN(2018)模型,作为业界的代表模型。
1.1 AFM——NFM的交叉特征+Attention得分
Attentional Factorization Machines - Learning the Weight of Feature Interactions via Attention Networks (ZJU 2017)
AFM可以看作是在NFM的基础上完善的,上节我们说到NFM时,其特点在于对于特征进行了元素积交叉,再进行SUM pooling的操作。一视同仁对待左右交叉特征,没有考虑特征对结果的影响程度。
注意力机制的作用就在此处,他基于假设:不同交叉特征对于结果的影响程度不同。事实也常常如此,比如预测是否购买键盘的场景中,<sex = female & 购买过鼠标>的重要程度就大于<sex = female & age =30>。基于此,注意力机制通过给每个交叉特征加权来实现。
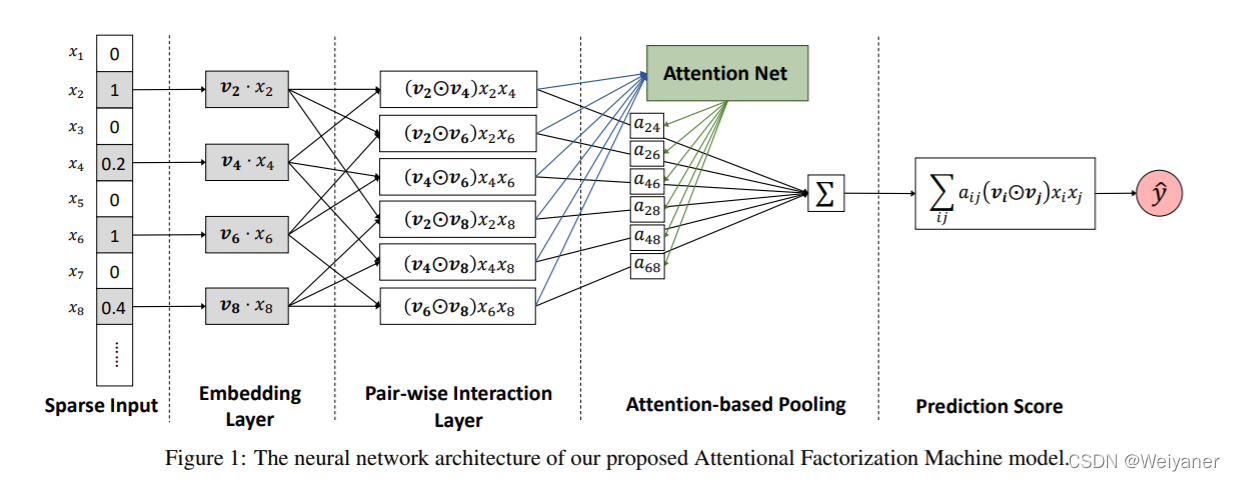 在上方图可以看到,首先特征进行交叉,这里依然采用的NFM的元素积:
在上方图可以看到,首先特征进行交叉,这里依然采用的NFM的元素积:
f P I ( ε ) = { ( v i ⊙ v j ) x i x j } ( i , j ) ∈ R x f_{\mathrm{PI}}(\varepsilon)=\left\{\left(v_{i} \odot v_{j}\right) x_{i} x_{j}\right\}_{(i, j) \in \mathcal{R}_{x}} fPI(ε)={
(vi⊙vj)xixj}(i,j)∈Rx
通过注意力得分后,池化过程为:
f Att ( f P I ( ε ) ) = ∑ ( i , j ) ∈ R x a i j ( v i ⊙ v j ) x i x j f_{\text {Att }}\left(f_{\mathrm{PI}}(\varepsilon)\right)=\sum_{(i, j) \in \mathcal{R}_{\boldsymbol{x}}} a_{i j}\left(v_{i} \odot v_{j}\right) x_{i} x_{j} fAtt (fPI(ε))=(i,j)∈Rx∑aij(vi⊙vj)xixj
对于交叉特征权重a_ij,最简单就是通过一个参数表示,为了防止交叉特征数据稀疏的问题带来权重难以收敛,AFM在Pair_wise Layer和池化层之间使用了Attention Layer来表示注意力得分。
$ a i j = ′ h T ReLU ( W ( v i ⊙ v j ) x i x j + b ) a i j = exp ( a i j ′ ) ∑ ( i , j ) ∈ R x exp ( a i j ′ ) \begin{array}{c}a_{i j=}^{\prime} \boldsymbol{h}^{\mathrm{T}} \operatorname{ReLU}\left(\boldsymbol{W}\left(\boldsymbol{v}_{i} \odot \boldsymbol{v}_{j}\right) x_{i} x_{j}+\boldsymbol{b}\right) \\a_{i j}=\frac{\exp \left(a_{i j}^{\prime}\right)}{\sum_{(i, j) \in \mathcal{R}_{x}} \exp \left(a_{i j}^{\prime}\right)}\end{array} aij=′hTReLU(W(vi⊙vj
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 3774
3774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











