







功能需求(functional requirement)
我们需要设计一个类似于dropbox的系统。这个系统可以支持以下功能:
- 支持用户登录和身份识别
- 登录用户可以创建一份文件,可以修改自己创建的文件,可以浏览自己创建的文件,可以自己创建的文件
- 登录用户可以分享自己的文件给另一个登录用户,权限分为只读和可以读写两种
- 登录用户可以编辑其他用户与他分享的文件如果他拥有读写权限;登录用户可以浏览其他用户与他分享的文件如果他拥有只读权限
- 登录用户拥有的文件如果被其他用户修改,该用户可以收到通知
非功能需求(non-functional requirement)
我们系统需要满足如下非功能需求:
- 可以支持十万名用户使用该系统,每名用户可以创建100分文件,每个文件最大不可以超过1G
- 可以支持一万名用户同时在线使用该系统
- 每份文件可以分享给最多一万名用户
- 每个操作的延迟不能超过一秒
- 每个通知的端到端延迟不能超过十秒
高层设计(high level design)
系统架构和数据流
创建文件
我们可以将我们的系统设计为网络服务器。用户可以通过浏览器打开我们的应用的网站,然后通过该网站进行一系列操作。创建文件的系统架构如下图所示。
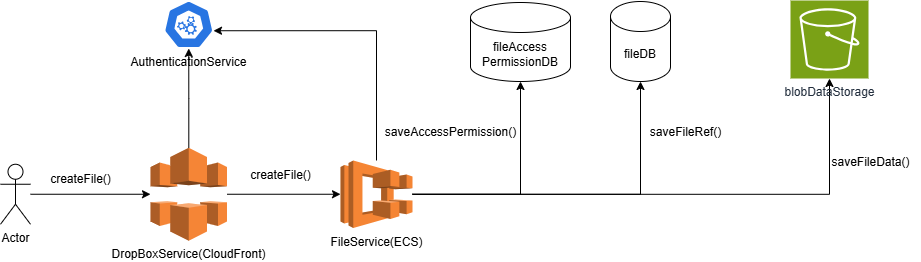
- DropBoxService:这是一个前端网络素材存储器,也就是存储类如HTML,CSS,和JS,甚至可以包括图片在内的网页静态素材。用CloudFront实现
- FileService:这是一个后端的服务器。它可以提供API,或者提供Restful接口,使用户可以通过DropBoxService调用这个服务器的API来实现创建文件的请求。用ECS(Fargate)实现。
- AuthenticationService: 提供用户的身份验证功能。可以由第三方服务提供。
- fileAccessPermissionDB: 提供每个用户和他所可以访问的文件的访问权限信息。
- fileDB: 保存文件的信息和到文件内容的索引。可以用Dynamo DB实现。
- blobDataStorage:保存文件的内容信息。
读取文件
数据流和创建文件相似。忽略详细内容。
修改文件
数据流和创建文件相似。忽略详细内容。
删除文件
数据流和创建文件相似。忽略详细内容。
分享文件
分享文件的数据流如下所示:
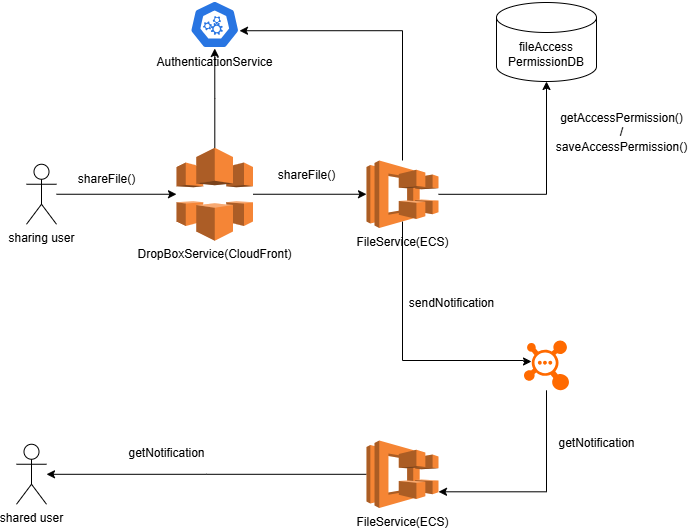
在用户分享文件时,我们首先要查询fileAccesspermissionDB,确保该用户拥有对该文件分享的权力。然后我们将被分享的用户对该文件的访问权限记录或者更新到fileAccessPermissionDB里。然后我们向该用户的消息队列发送一个通知。当被分享用户下一次登录系统时,我们首先查询是否在消息队列里有通知。如果有,我们就将该通知显示给该用户。需要注意的是,这意味着我们需要为每一个用户单独创建属于他的消息队列。这样可能会受到消息队列创建数量的限制。替代的解决方案可以是将通知存储在一个数据库中。然后用户需要定期的去poll他是否有通知存在在数据库中。如果有,将通知读出,同时删除该通知。
文件修改的通知
这个实现并不难,可以在文件被修改的时候,向该文件的owner发送一条通知。
低层设计
API设计
我们可以实现如下的API:
- string getFile(string fileId);
- string createFile(string fileName, byte[] content);
- void updateFile(string fileId, byte[] content);
- void deleteFile(string fileId);
- void shareFile(string fileId, string targetUserId, string permissionType);
我们在API的parameter里不需要提供用户的ID信息。因为我们可以假定我们可以从API携带的token里得到的用户的验证信息。
数据库设计
系统中各个数据库的表的schema设计如下:
- fileDB:记录文件的基本信息
| 列名 | 类型 | 注释 |
|---|---|---|
| fileId | string | primary key |
| reference | string | S3文件的URL |
| owner | string | 文件的拥有者 |
- fileAccessPermissionDB:记录文件访问权限
| 列名 | 类型 | 注释 |
|---|---|---|
| userId | string | partition key |
| fileId | string | sort key |
| accessType | string | readOnly 或者 readWrite |
扩展
当文件比较大时,更新文件和读取文件会有不同的性能问题。比较好的做法是将大文件分割成不同的部分(chunk)。在读取文件时,我们可以一部分一部分的读取。而在文件修改时,我们只需要将被修改的chunk写回到blob storage即可。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









