






一、现象描述
公司目前calico及kube-controllers涉及多个版本,在kube-controller v3.6.0版本中,当每次从集群删除主机,都会导致controller服务进行重启,如果一次删除多个主机,就会造成服务多次自动重启
二、故障排查
方向一、怀疑是先关机然后再从集群删除机器导致
测试环境进行测试,先从集群删除主机,然后再进行关机观察,发现仍然报错,报错信息相同:
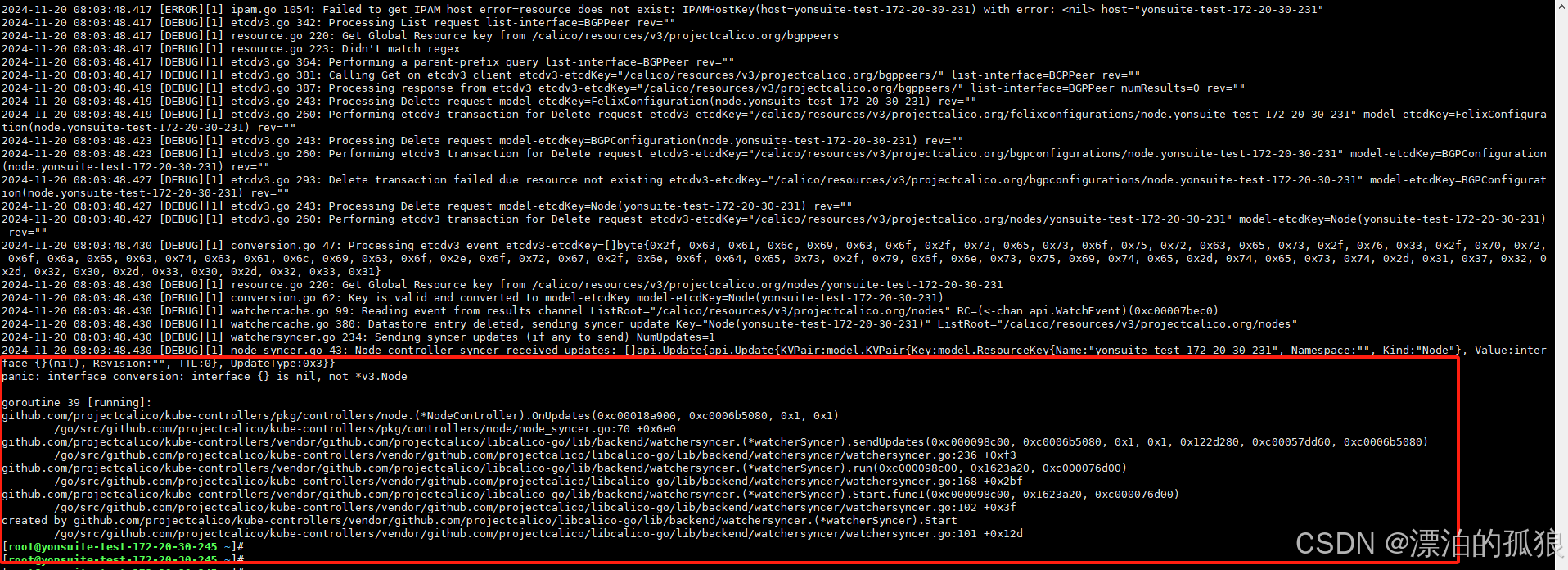
方向二、服务本身存在bug
通过git issue排查,没有找到相关的错误报告
三、源码解读
相关排查代码展示:
代码一、删除缓存,将节点信息同步到通道(watchercache.go)
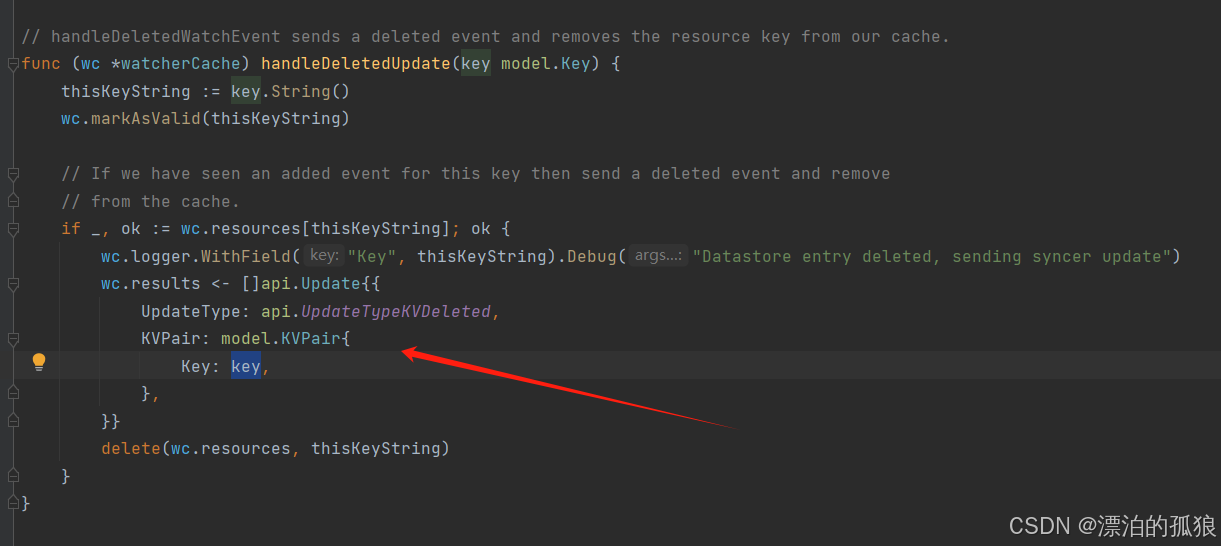
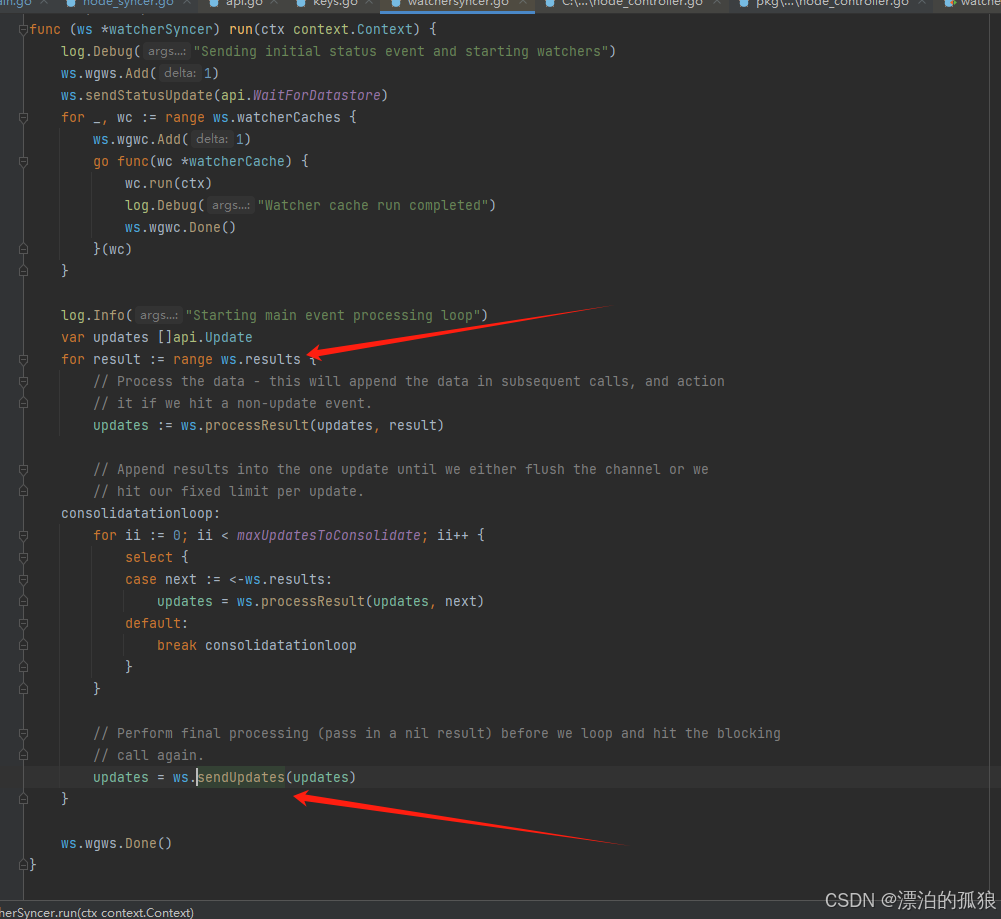
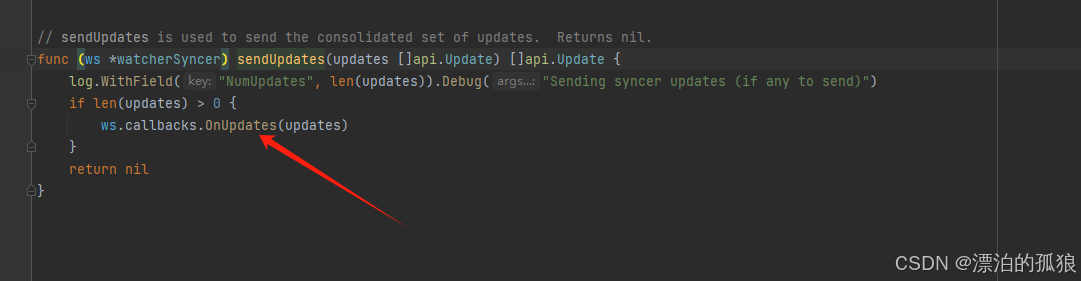
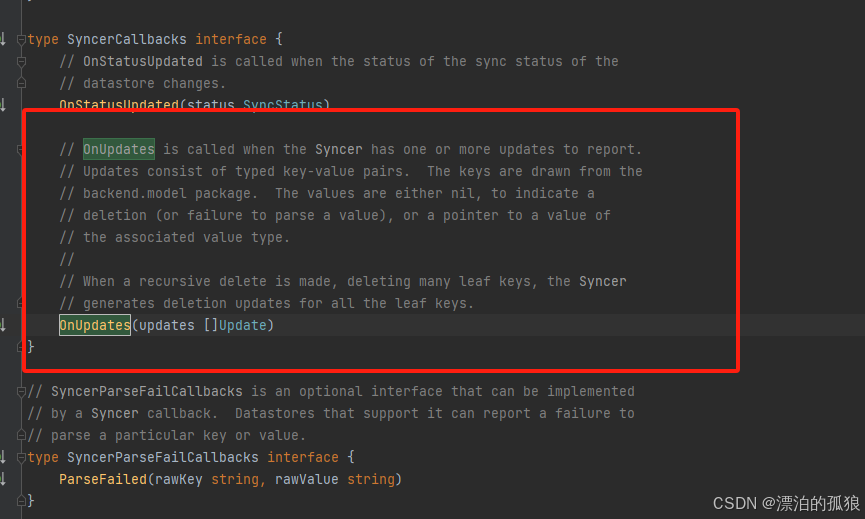
四、源码分析
kube-controller 会实时监听kubernetes集群,当收到集群有删除事件以后,会做出一系列的动作,报错从缓存中删除信息、删除etcd相关网络信息,释放节点网络相关配置,最后节点信息同步
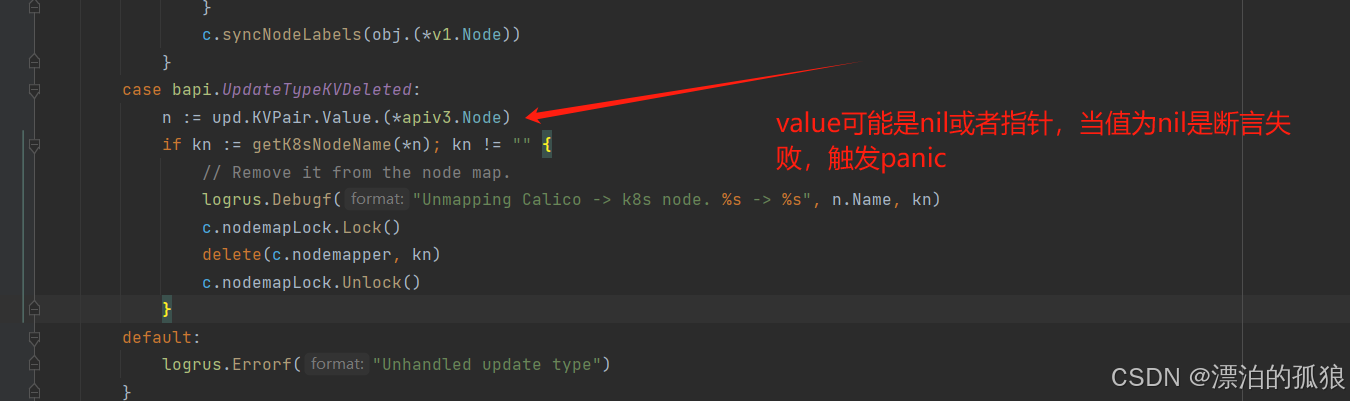
故障原因:节点删除后,通道中传递的value值可能是nil或者指针,但是源码中直接断言了指针的情况,当值为nil的时候,就会触发panic
五、代码调整
代码文件及路径 pkg/controllers/node/node_syncer.go
func (c *NodeController) OnUpdates(updates []bapi.Update) {
logrus.Debugf("Node controller syncer received updates: %#v", updates)
for _, upd := range updates {
switch upd.UpdateType {
case bapi.UpdateTypeKVNew:
fallthrough
case bapi.UpdateTypeKVUpdated:
n := upd.KVPair.Value.(*apiv3.Node)
if kn := getK8sNodeName(*n); kn != "" {
// Create a mapping from Kubernetes node -> Calico node.
logrus.Debugf("Mapping Calico -> k8s node. %s -> %s", n.Name, kn)
c.nodemapLock.Lock()
c.nodemapper[kn] = n.Name
c.nodemapLock.Unlock()
// It has a node reference - get that Kubernetes node, and if
// it exists perform a sync.
obj, ok, err := c.indexer.GetByKey(kn)
if !ok {
logrus.Debugf("No corresponding kubernetes node")
continue
} else if err != nil {
logrus.WithError(err).Warnf("Couldn't get node from indexer")
continue
}
c.syncNodeLabels(obj.(*v1.Node))
}
case bapi.UpdateTypeKVDeleted:
// xc调整start
if upd.KVPair.Value != nil {
logrus.Warnf("KVPair value should be nil for Deleted UpdataType")
}
nodeName := upd.KVPair.Key.(model.ResourceKey).Name
// Try to perform unmapping based on resource name (calico node name).
for kn, cn := range c.nodemapper {
if cn == nodeName {
// Remove it from node map.
logrus.Debugf("Unmapping k8s node -> calico node. %s -> %s", kn, cn)
c.nodemapLock.Lock()
delete(c.nodemapper, kn)
c.nodemapLock.Unlock()
break
}
}
// xc调整end
default:
logrus.Errorf("Unhandled update type")
}
}
}六、重新编码,部署测试
已经兼容了nil的情况,服务没有触发重启,测试通过



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









