






损失函数e最小即为要求的的随机梯度下降在假设只有一个参数时,可以理解为一个二次函数一条开口向上的曲线,最低点为(斜率最低处)为损失最低处,此时的w为训练出最准确的函数。
那么如何寻找最低点,就用一种梯度下降方法,不断的通过某种下降方法求w
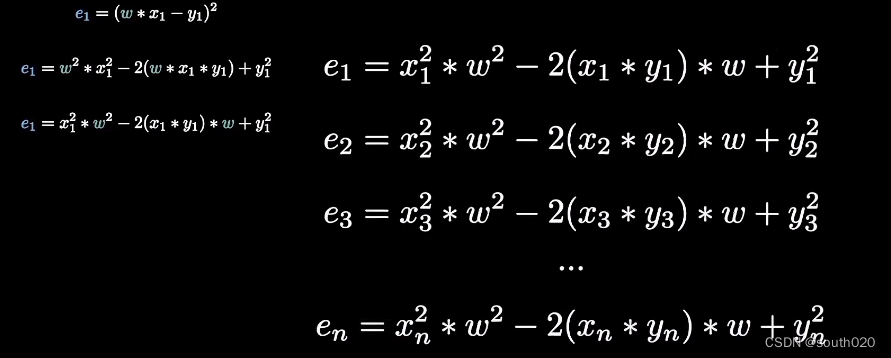

import torch
from d2l import torch as d2l
from torch.utils import data
#创建一个数据集
true_w = torch.tensor([2, -3.4])
true_b = 4.2
features, labels = d2l.synthetic_data(true_w, true_b, 1000)
print(features)
#读取数据集
def load_array(data_arrays, batch_size, is_train=True): # @save
"""构造一个PyTorch数据迭代器"""
#TensorDataset 类构建一个数据集对象TensorDataset
# 是 PyTorch 提供的用于处理张量数据集的类。通过传递 *data_arrays,
# 将特征和标签数据作为参数传递给 TensorDataset,从而创建了一个包含特征和标签样本的数据集对象。
dataset = data.TensorDataset(*data_arrays)
# DataLoader 类来创建一个数据加载器对象。该对象会将数据集划分为指定大小的批次,并在每个迭代步骤中返回一个批次的数据。
# 在上面的例子中,我们指定批次大小为 32,并设置 shuffle=True 来在每个迭代步骤中对数据进行洗牌,以增加训练的随机性。
return data.DataLoader(dataset, batch_size, shuffle=is_train)
#DataLoader 类来创建一个数据加载器对象。该对象会将数据集划分为指定大小的批次,并在每个迭代步骤中返回一个批次的数据。
# 在上面的例子中,我们指定批次大小为 32,并设置 shuffle=True 来在每个迭代步骤中对数据进行洗牌,以增加训练的随机性。
batch_size = 10
data_iter = load_array((features, labels), batch_size)
next(iter(data_iter))
from torch import nn
#创建了一个简单的神经网络模型,使用 nn.Sequential 构建。
# nn.Linear(2, 1) 表示输入维度为 2,输出维度为 1 的线性层。这个线性层作为我们模型的唯一层。
net = nn.Sequential(nn.Linear(2, 1))
net[0].weight.data.normal_(0, 0.01)
net[0].bias.data.fill_(0)
#定义了损失函数。nn.MSELoss() 创建了一个均方误差损失函数的实例,用来计算预测值和真实值之间的平均平方差。
loss = nn.MSELoss()
trainer = torch.optim.SGD(net.parameters(), lr=0.03)
#训练
num_epochs = 5
for epoch in range(num_epochs):
for X, y in data_iter:
l = loss(net(X) ,y)
trainer.zero_grad()
l.backward()#进行反向传播计算梯度。通过调用 backward() 函数,根据损失 l 自动计算模型参数的梯度。
trainer.step()
# 计算整个数据集上的损失。将所有样本的特征 features 和标签 labels 输入模型 net 进行预测,并计算预测值与真实值之间的损失。
l = loss(net(features), labels)
print(f'epoch {epoch + 1}, loss {l:f}')
#训练后的结果
w = net[0].weight.data
print(w)
print('w的估计误差:', true_w - w.reshape(true_w.shape))
b = net[0].bias.data
print(b)
print('b的估计误差:', true_b - b)

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









