







ConcurrentHashMap比HashMap并发好,比HashTable效率高,因为HashTable在对数据操作的时候都会上锁。
ConcurrentHashMap 在 JDK1.7 和 JDK1.8 的实现方式是不同的。
JDK1.7
JDK1.7 中的 ConcurrentHashMap 是segment+数组+链表的结构,即 ConcurrentHashMap 把哈希桶数组切分成小数组(Segment ),每个小数组有 n 个 HashEntry 组成。
原理上来说,ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。
不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。
每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
就是说如果容量大小是16他的并发度就是16,可以同时允许16个线程操作16个Segment而且还是线程安全的。
JDK1.8
在数据结构上, JDK1.8 中的ConcurrentHashMap 选择了与 HashMap 相同的数组+链表+红黑树结构;在锁的实现上,抛弃了原有的 Segment 分段锁,采用CAS+synchronized实现更加细粒度的锁,如果多个线程访问的链表头结点不同,则不会冲突。
ConcurrentHashMap的put方法的执行逻辑
JDK1.7
- 尝试自旋获取锁。
- 如果重试的次数达到了上限则改为阻塞锁获取,保证能获取成功。
JDK1.8
- 根据key计算出hashcode。
- 判断是否需要进行初始化。
- 定位到Node,拿到首节点,判断首节点:
- 如果为null,则通过CAS的方式尝试添加,失败则自旋保证成功。
- 如果hashcode == MOVED == -1,说明其他线程在扩容,参与一起扩容。
- 如果都不满足,则利用synchronized锁写入数据。
4. 如果数量大于阈值则要转换为红黑树。
ConcurrentHashMap的get方法的执行逻辑
JDK1.7
将key通过hash之后定位到具体的segment,再通过一次hash定位到具体的元素上。、
由于HashEntry中的value属性是用volatile关键词修饰的,保证了内存可见性,所以每次获取时都是新值,整个过程不用加锁。
JDK1.8
- 根据计算出来的hashcode寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 都不满足那就按照链表的方式遍历获取值。
为什么Hashtable和ConcurrentHashMap是不允许键或值为 null 的,HashMap 的键值则都可以为 null?
ConcurrentHashmap和Hashtable都是支持并发的,这样会有一个问题,当你通过get(k)获取对应的value时,如果获取到的是null时,你无法判断,它是put(k,v)的时候value为null,还是这个key从来没有做过映射。HashMap是非并发的,可以通过contains(key)来做这个判断。而支持并发的Map在调用contains(key)和get(key),Map可能已经不同了。
但是HashMap却做了特殊处理。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}多线程下安全的操作 map还有其他方法吗?
还可以使用Collections.synchronizedMap方法,对方法进行加同步锁。
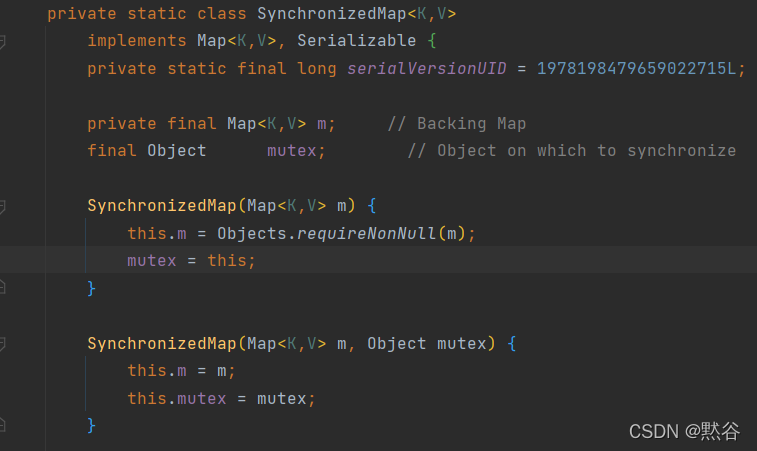
如果传入的是 HashMap 对象,其实也是对 HashMap 做的方法做了一层包装,里面使用对象锁来保证多线程场景下,线程安全,本质也是对 HashMap 进行全表锁。
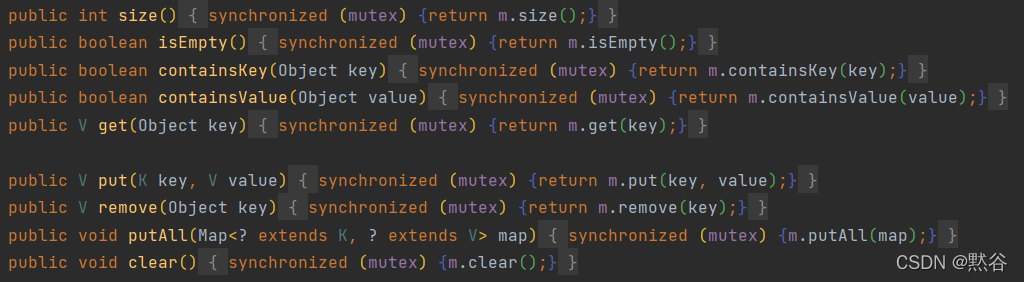
在竞争激烈的多线程环境下性能依然也非常差,不推荐使用!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









