







java cas
什么是CAS
CAS, compare and swap的缩写,中文意思为 比较并交换。
cas操作包含3个操作数,内存位置V,预期原值A,新值B。 如果内存位置的值和预期原值相匹配,那么处理器会自动将该位置值更新为新值,否则,处理器不做任何操作。
意义
多线程修改共享变量时,线程并非处于阻塞状态,而是处于自旋态,所以并不会出现死锁的情况。
Java中的Atomic原子操作包
juc并发包中原子类,都存放在java.util.concurrent.atomic类路径下:
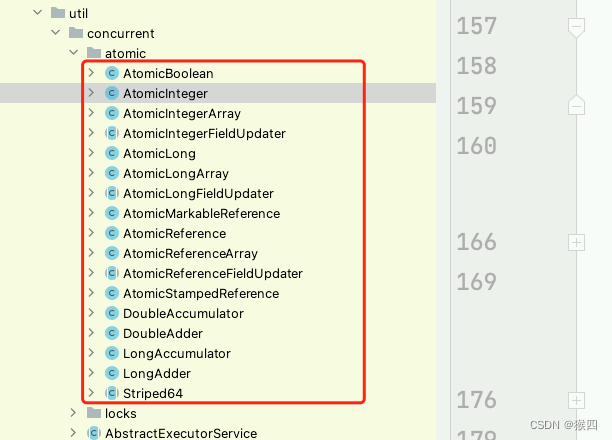
根据操作的目标数据类型,可以将juc包中的原子类分为4类:
- 基本原子类
- 数组原子类
- 原子引用类型
- 字段更新原子类
基本原子类
基本原子类的功能,是通过原子方式更新Java基础类型变量的值,基本原子类主要包括了以下三个:
- AtomicInteger:整型原子类
- AtomicLong:长整型原子类。
- AtomicBoolean :布尔型原子类。
数组原子类
数组原子类的功能,是通过原子方式更新数组里的某个元素的值,数组原子类主要包括以下三个:
- AtomicIntegerArray:整型数组原子类
- AtomicLongArray:长整型数组原子类。
- AtomicReferenceArray :引用类型数组原子类。
引用原子类
引用原子类主要包括了以下三个:
- AtomicReference:引用类型原子类。
- AtomicMarkableReference :带有更新标记位的原子引用类型。
- AtomicStampedReference :带有更新版本号的原子引用类型。
AtomicStampedReference通过引入“版本”的概念,来解决ABA的问题。
字段更新原子类
字段更新原子类主要包括了以下三个:
- AtomicIntegerFieldUpdater:原子更新整型字段的更新器。
- AtomicLongFieldUpdater:原子更新长整型字段的更新器。
- AtomicReferenceFieldUpdater:原子更新引用类型里的字段
源码解析
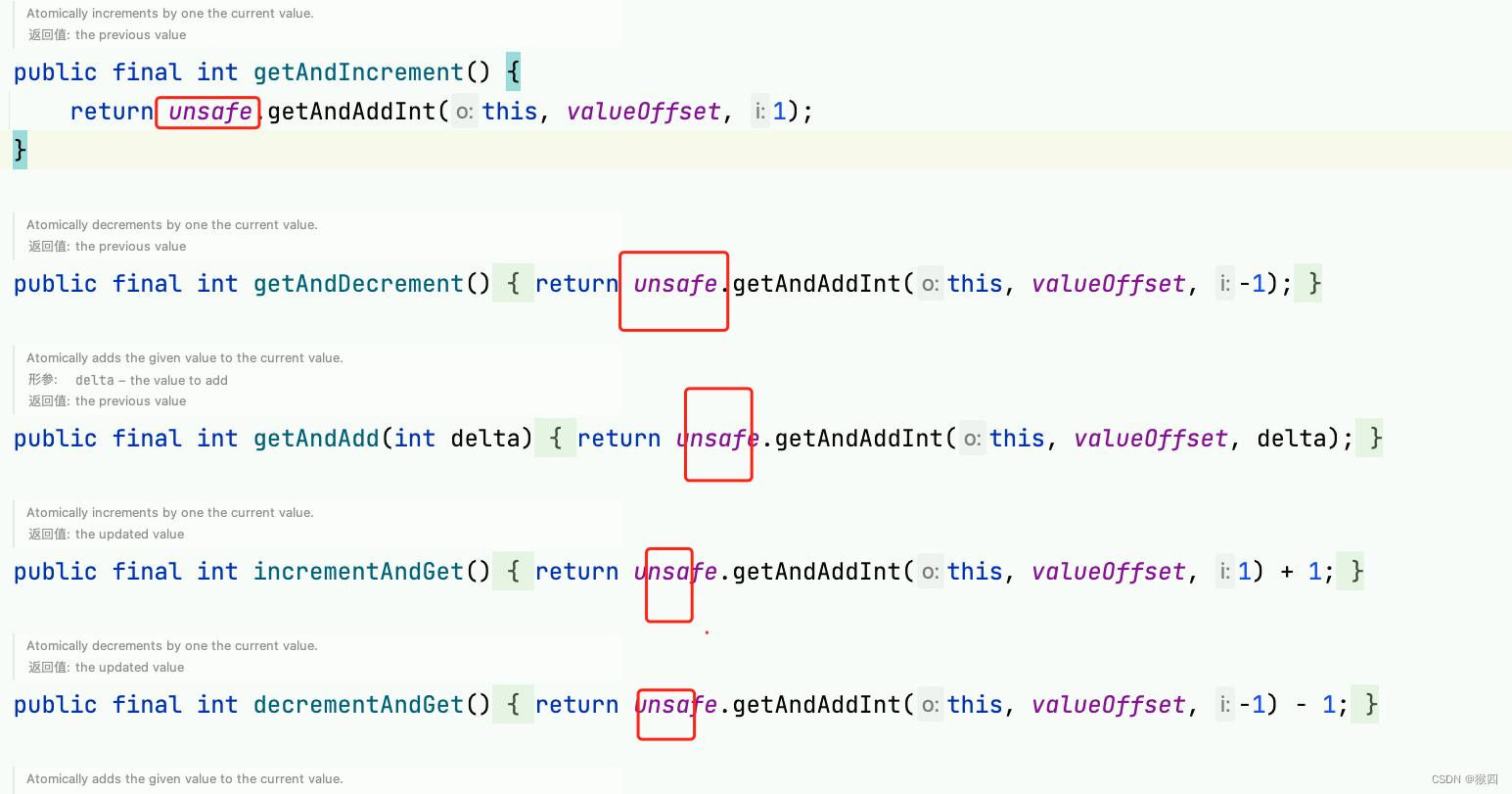
通过源码我们发现AtomicInteger的增减操作都调用了Unsafe 实例的方法,下面我们对Unsafe类做介绍。
unsafe类
Unsafe 是位于 sun.misc 包下的一个类,Unsafe 提供了CAS 方法,直接通过native 方式(封装 C++代码)调用了底层的 CPU 指令 cmpxchg。
Unsafe类,翻译为中文:危险的,Unsafe全限定名是 sun.misc.Unsafe,从名字中我们可以看出来这个类对普通程序员来说是“危险”的,一般应用开发者不会用到这个类。
/*
@param o 包含要修改的字段的对象
@param offset 字段在对象内的偏移量
@param expected 期望值(旧的值)
@param update 更新值(新的值)
@return true 更新成功 | false 更新失败
*/
public final native boolean compareAndSwapObject(Object o, long offset, Object expected, Object update);
public final native boolean compareAndSwapInt( Object o, long offset, int expected,int update);
public final native boolean compareAndSwapLong( Object o, long offset, long expected, long update);
Unsafe 提供的 CAS 方法包含四个入参: 包含要修改的字段对象、字段内存位置、预期原值及
新值。在执行 Unsafe 的 CAS 方法的时候,这些方法首先将内存位置的值与预期值(旧的值)比
较,如果相匹配,那么处理器会自动将该内存位置的值更新为新值,并返回 true ;如果不相匹配,
处理器不做任何操作,并返回 false 。
需要着重说明的是cas比较的是对象的引用。相当于==
cas缺点
ABA问题
- ABA问题。因为CAS需要在操作值的时候检查下值有没有发生变化,如果没有发生变化则更新,但是如果一个值原来是A,变成了B,又变成了A,那么使用CAS进行检查时会发现它的值没有发生变化,但是实际上却变化了。
ABA问题带来的实际问题
ABA问题也并不是都会带来问题,如在AutomicInterger中,就会存在ABA问题,但是对最终结果并不造成影响,所以如果对于值类型的变量,ABA其实并不会造成什么问题,因为我们关注的是最终的值结果。
但如果我们操作的是引用类型,可能会带来意外的结果。
举例说明
ABA导致的链表删除
-
现有一个单项链表,表头为A, 整体为A->B
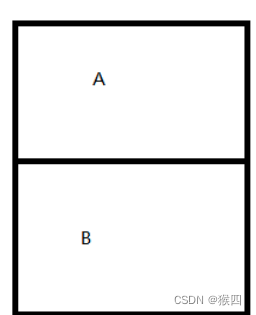
-
此时线程t1想用B替换A,最终链表中只有B
-
在t1执行cas前,t2获得获得cpu执行权限,将A,B删除了(即B.next=null,),在往链表中放入A,C,D,而此时B节点对象处理游离态,
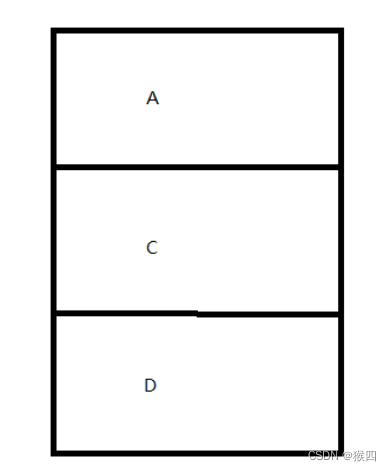
-
然后t1获取了cpu,开始进行cas,因为A还在表头,所以t1执行成功了,替换为B了。但结果呢?
因为B是游离态,所以B.next=null, 此时结果变为:
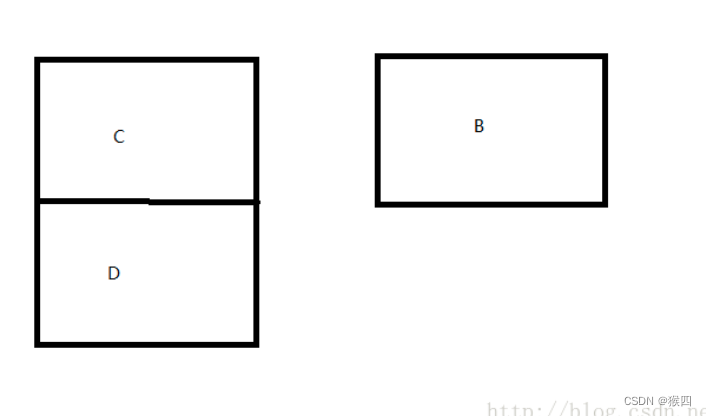
此时链表的结构就被破坏了,解决办法就是如果发现节点被破坏了,就不进行操作了。
只能保证一个共享变量的原子操作
- 只能保证一个共享变量的原子操作。一个比较简单的规避方法为:把多个共享变量合并成一个共享变量来操作。 JDK 提供了 AtomicReference 类来保证引用对象之间的原子性,可以把多个变量放在一个 AtomicReference 实例后再进行 CAS 操作。比如有两个共享变量 i=1、j=2,可以将二者合并成一个对象,然后用 CAS 来操作该合并对象的 AtomicReference 引用。
循环时间长开销大
循环时间长开销大。高并发下N多线程同时去操作一个变量,会造成大量线程CAS失败,然后处于自旋状态,导致严重浪费CPU资源,降低了并发性。
解决 CAS 恶性空自旋的较为常见的方案为:
- 分散操作热点,使用 LongAdder 替代基础原子类 AtomicLong。
- 使用队列削峰,将发生 CAS 争用的线程加入一个队列中排队,降低 CAS 争用的激烈程度。JUC 中非常重要的基础类 AQS(抽象队列同步器)就是这么做的。
优化方式
以空间换时间:LongAdder
LongAdder 的基本思路就是分散热点, 如果有竞争的话,内部维护了多个Cell变量,每个Cell里面有一个初始值为0的long型变量, 不同线程会命中到数组的不同Cell (槽 )中,各个线程只对自己Cell(槽) 中的那个值进行 CAS 操作。这样热点就被分散了,冲突的概率就小很多。
在没有竞争的情况下,要累加的数通过 CAS 累加到 base 上。
如果要获得完整的 LongAdder 存储的值,只要将各个槽中的变量值累加,后的值即可。
使用 AtomicStampedReference 解决 ABA 问题
JDK 的提供了一个类似 AtomicStampedReference 类来解决 ABA 问题。
AtomicStampReference 在 CAS 的基础上增加了一个 Stamp 整型 印戳(或标记),使用这个印戳可以来觉察数据是否发生变化,给数据带上了一种实效性的检验。
AtomicStampReference 的 compareAndSet 方法首先检查当前的对象引用值是否等于预期引用,
并且当前印戳( Stamp )标志是否等于预期标志,如果全部相等,则以原子方式将引用值和印戳
( Stamp )标志的值更新为给定的更新值。

















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









