







目录
fastText是Facebook AI Research在16年开源的一个文本分类器。 其特点就是fast,可以作为文本分类的baseline模型。相对于其它文本分类模型,如SVM,Logistic Regression和neural network等模型,fastText在保持分类效果的同时,大大缩短了训练时间。
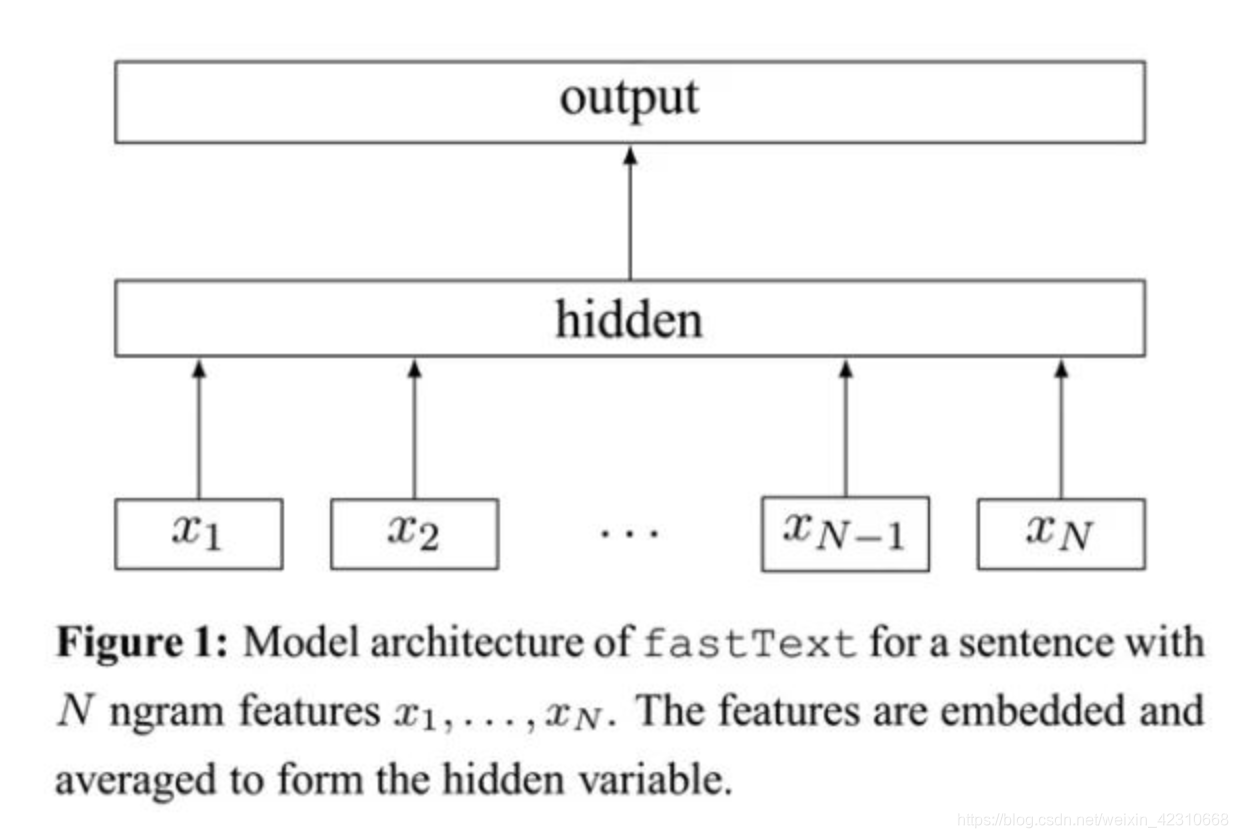
fastTest基本结构
fastText优势
- 适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇”,特别是与深度模型对比,fastText能将训练时间由数天缩短到几秒钟。使用一个标准多核 CPU,得到了在10分钟内训练完超过10亿词汇量模型的结果。此外, fastText还能在五分钟内将50万个句子分成超过30万个类别。
- 支持多语言表达:利用其语言形态结构,fastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。它还使用了一种简单高效的纳入子字信息的方式,在用于像捷克语这样词态丰富的语言时,这种方式表现得非常好,这也证明了精心设计的字符 n-gram 特征是丰富词汇表征的重要来源。FastText的性能要比时下流行的word2vec工具明显好上不少,也比其他目前最先进的词态词汇表征要好。
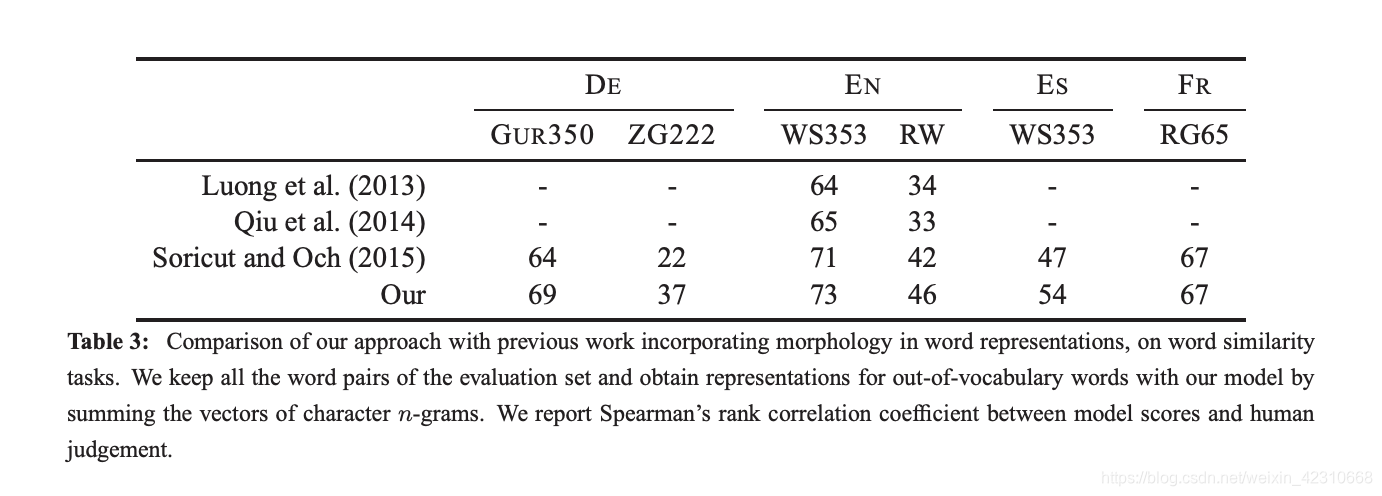
- fastText专注于文本分类,在许多标准问题上实现当下最好的表现(例如文本倾向性分析或标签预测)。FastText与基于深度学习方法的Char-CNN以及VDCNN对比:

- 比word2vec更考虑了相似性,比如 fastText 的词嵌入学习能够考虑 english-born 和 british-born 之间有相同的后缀,但 word2vec 却不能(具体参考paper)。
fastText原理
fastText 方法包含三部分:模型架构、层次 Softmax 和 N-gram 特征。
- fastText 模型输入一个词的序列(一段文本或者一句话),输出这个词序列属于不同类别的概率。
- 序列中的词和词组组成特征向量,特征向量通过线性变换映射到中间层,中间层再映射到标签。
- fastText 在预测标签时使用了非线性激活函数,但在中间层不使用非线性激活函数。
- fastText 模型架构和 Word2Vec 中的 CBOW 模型很类似。不同之处在于,fastText 预测标签,而 CBOW 模型预测中间词。
模型架构
fastText的模型架构类似于CBOW,两种模型都是基于Hierarchical Softmax,都是三层架构:输入层、 隐藏层、输出层。CBOW模型又基于N-gram模型和BOW模型,此模型将上下文作为输入,去预测中间词。fastText的模型则是将整个文本作为特征去预测文本的类别。
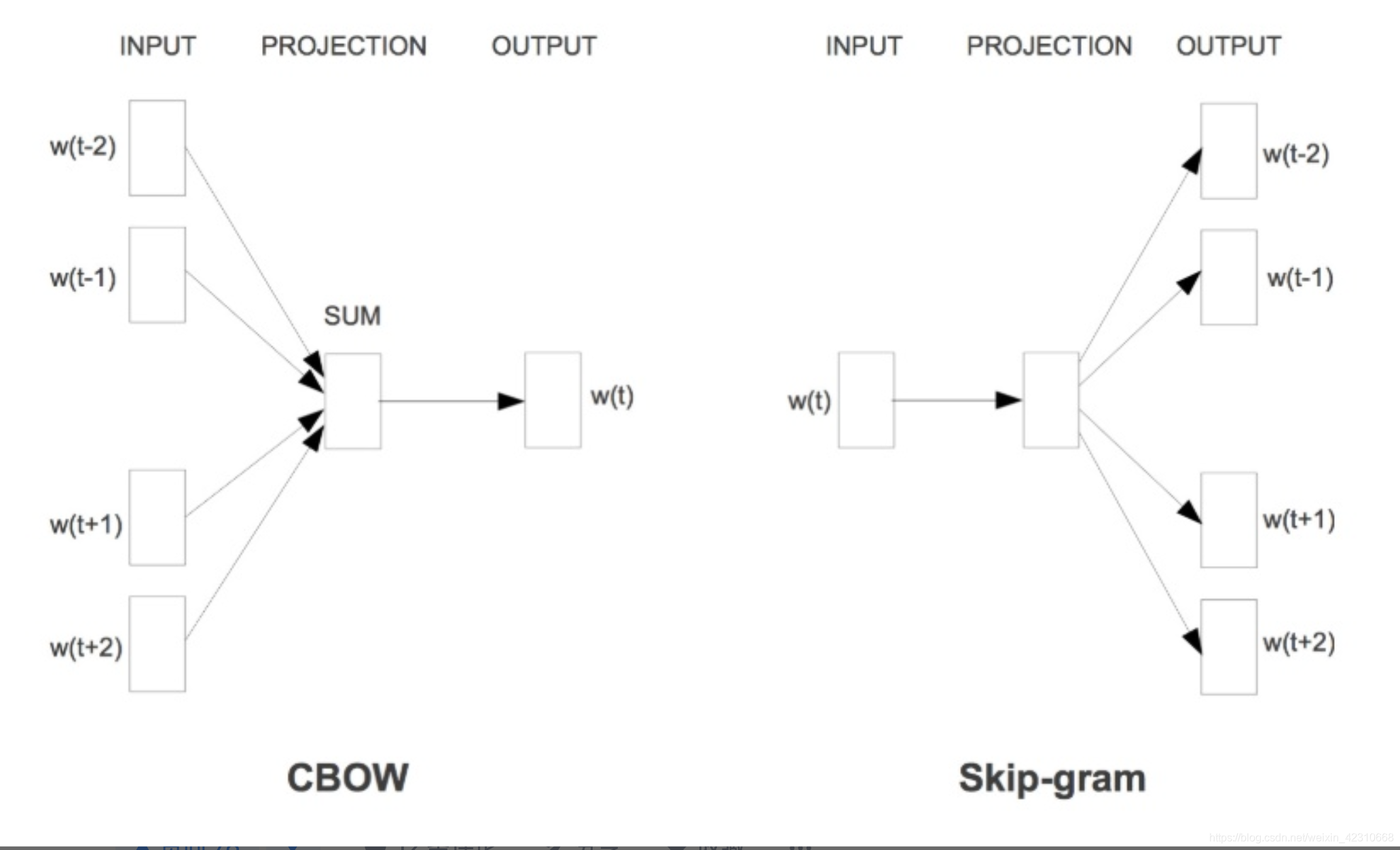
层次softmax
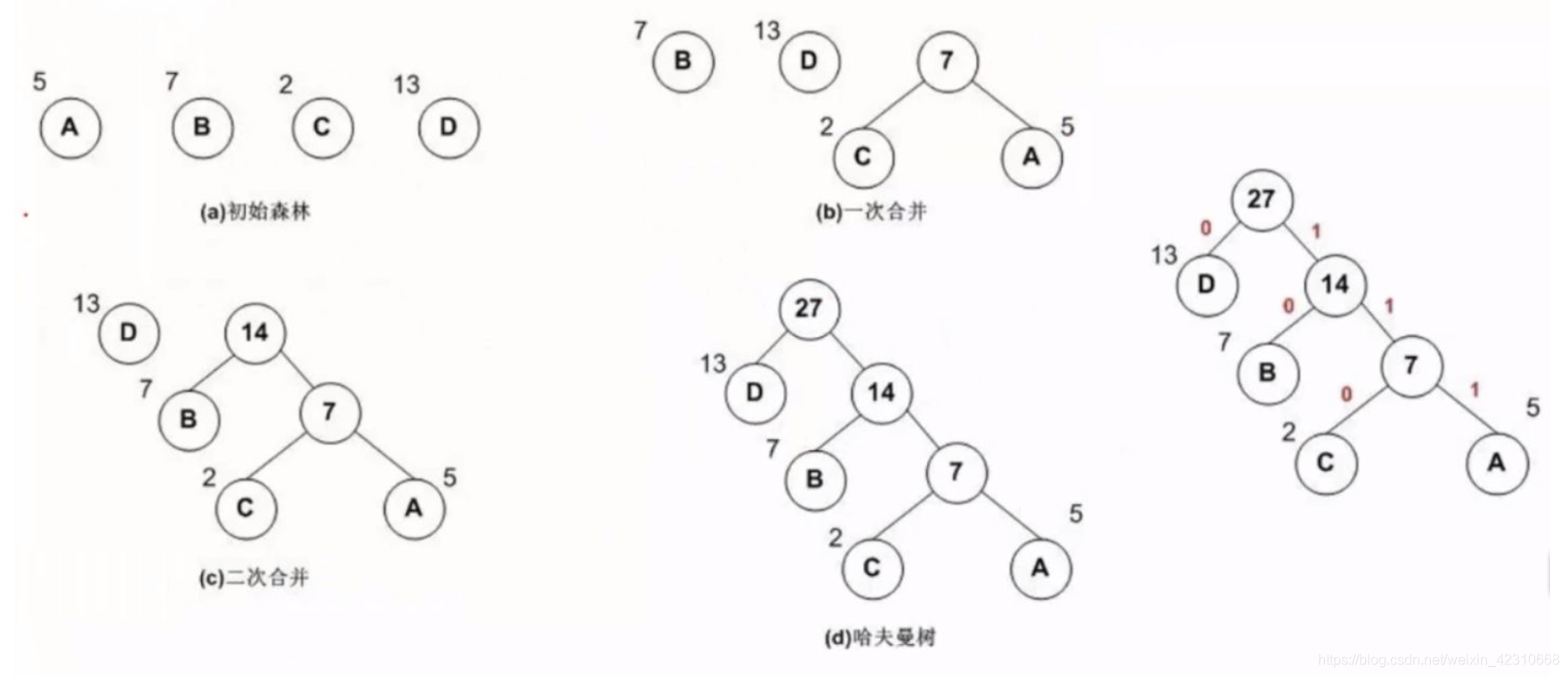
将输入层中的词和词组构成特征向量,再将特征向量通过线性变换映射到隐藏层,隐藏层通过求解最大似然函数,然后根据每个类别的权重和模型参数构建Huffman树,将Huffman树作为输出。
在进行最优化的求解过程中:从隐藏层到输出的Softmax层的计算量很大,因为要计算所有词/label的Softmax概率,再去找概率最大的值。fastText 模型使用了Hierarchical Softmax来解决这个问题。对于有大量类别的数据集,fastText使用了一个分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,fastText 模型使用了层次 Softmax 技巧。层次 Softmax 技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。具体数学推导,详见https://zhuanlan.zhihu.com/p/56139075
考虑到线性以及多种类别的对数模型,这大大减少了训练复杂性和测试文本分类器的时间。同时Huffman树有一个原则:最重要的放在最前面。因此对于频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。
fastText的N-gram特征
常用的特征是词袋模型(将输入数据转化为对应的Bow形式)。但词袋模型不能考虑词之间的顺序,因此 fastText 还加入了 N-gram 特征。
*“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。 如果加入 2-Ngram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然,为了提高效率,我们需要过滤掉低频的 N-gram。 *
在fastText 中一个低维度向量与每个单词都相关。隐藏表征在不同类别所有分类器中进行共享,使得文本信息在不同类别中能够共同使用。这类表征被称为词袋(bag of words)(此处忽视词序)。在 fastText中也使用向量表征单词 n-gram来将局部词序考虑在内,这对很多文本分类问题来说十分重要。
FastText词向量与word2vec对比¶
FastText其实是对word2vec中 cbow + h-softmax的灵活使用,其灵活主要体现在两个方面:
- 模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用;
- 模型的输入层:word2vec的输入层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容;
两者本质的不同,体现在 h-softmax的使用:
- Word2vec的目的是得到词向量,该词向量 最终是在输入层得到,输出层对应的 h-softmax 也会生成一系列的向量,但最终都被抛弃,不会使用。
- fasttext则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)。
参考:
https://blog.youkuaiyun.com/qq_16633405/article/details/80578431
https://blog.youkuaiyun.com/sinat_26917383/article/details/54850933

















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









