




 本文介绍了使用朴素贝叶斯算法进行垃圾分类的方法。首先讲解了朴素贝叶斯模型的基本原理,包括条件概率和贝叶斯决策理论。接着详细阐述了系统设计,包括数据收集、训练集和测试集的划分、特征向量构建以及如何构建贝叶斯分类器。最后,通过代码实现了分类器训练和测试,展示了一个简单的垃圾邮件和非垃圾邮件分类的例子。
本文介绍了使用朴素贝叶斯算法进行垃圾分类的方法。首先讲解了朴素贝叶斯模型的基本原理,包括条件概率和贝叶斯决策理论。接着详细阐述了系统设计,包括数据收集、训练集和测试集的划分、特征向量构建以及如何构建贝叶斯分类器。最后,通过代码实现了分类器训练和测试,展示了一个简单的垃圾邮件和非垃圾邮件分类的例子。
一、模型方法
本工程采用的模型方法为朴素贝叶斯分类算法,它的核心算法思想基于概率论。我们称之为“朴素”,是因为整个形式化过程只做最原始、最简单的假设。朴素贝叶斯是贝叶斯决策理论的一部分,所以讲述朴素贝叶斯之前有必要快速了解一下贝叶斯决策理论。假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示。
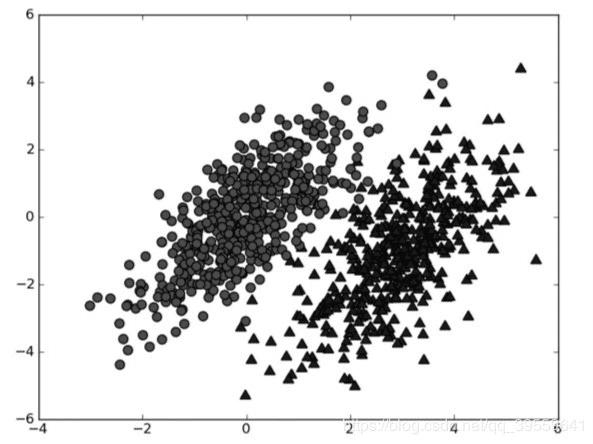
我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中用圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中用三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
如果 p1(x,y) > p2(x,y),那么类别为1。
如果 p2(x,y) > p1(x,y),那么类别为2。
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
在本工程中我们可以使用条件概率来进行分类。其条件概率公式如下:
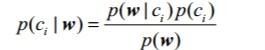
其中粗体w表示这是一个向量,它是有多个值组成。对于类别i表示分类的个数,在本工程中i=0时,c0表示非垃圾邮件。i=1时,c1表示垃圾邮件。w展开为一个个独立特征,那么就可以将上述概率写作p(w0,w1,w2..wN|ci)。这里假设所有词都互相独立,该假设也称作条件独立性假设,它意味着可以使用p(w0|ci)p(w1|ci)p(w2|ci)...p(wN|ci)来计算上述概率,这就极大地简化了计算的过程,这也是被称为朴素贝叶斯的原因。在本工程中wj代表第i个单词特征,而p(wj|ci)则代表了在垃圾邮件(或非垃圾邮件)中,第j个单词出现的概率;而p(w|ci)则表示在垃圾邮件(或非垃圾邮件)中的全体向量特征(单词向量特征)出现的概率;而p(ci| w)则表示在全体向量特征(单词向量特征)下是垃圾邮件(或非垃圾邮件)的概率。本工程项目主要是计算p(ci|w);p(ci)则表示是垃圾邮件(或非垃圾邮件)的概率。
二、系统设计
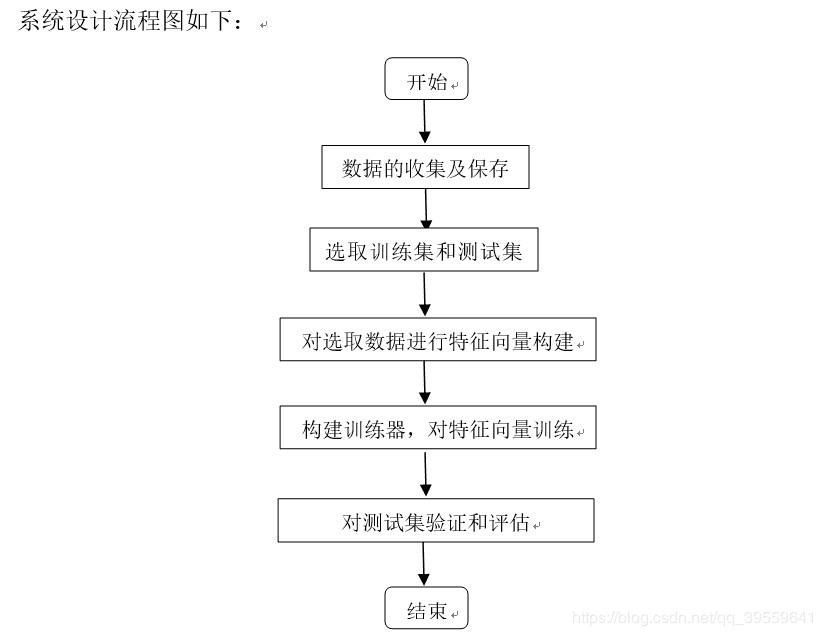
数据的收集及保存
邮件的收集来源于网上,保存在email文件夹中。其中email分两个子文件,一个为ham文件夹(保存非垃圾邮件),另一个为spam文件夹(保存垃圾邮件)。ham与spam中各保存25各邮件
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1351
1351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









