







简介:这个源码项目是一个基于SpringBoot和Vue3框架构建的在线Markdown文集系统,涵盖Java、Spring Boot、Vue.js以及Markdown解析技术。通过该项目,开发者可以学习到如何搭建后端服务、实现前端交互、进行数据库操作、设计RESTful API、处理认证授权、管理前端路由与状态、部署应用以及进行项目测试。项目的目的是帮助开发者深入理解前后端分离开发模式,并提升使用Spring Boot和Vue 3构建Web应用的能力。 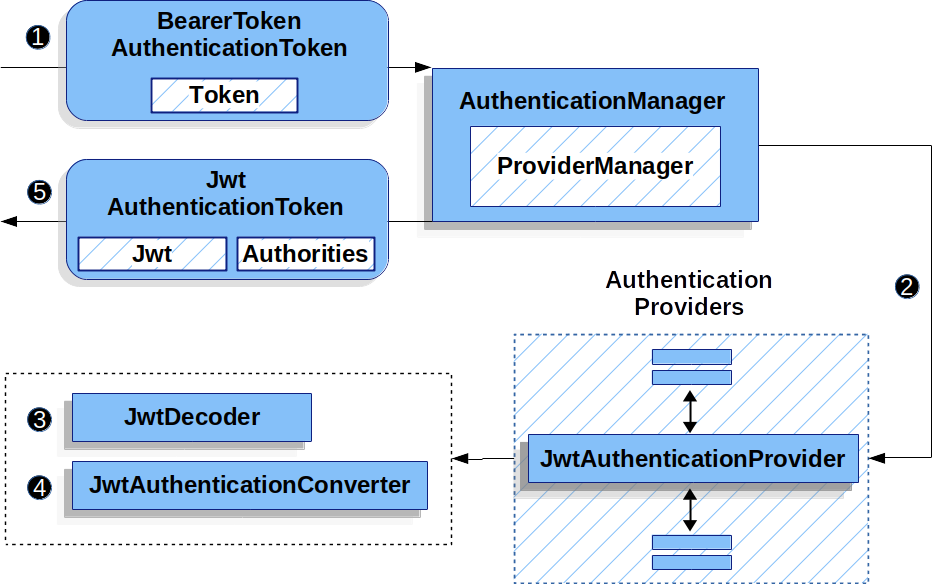
1. Spring Boot后端框架应用
Spring Boot作为Java开发者中广受欢迎的后端框架,通过提供大量自动配置和最小化样板代码的方式极大地简化了企业级应用的开发。它整合了Spring生态系统中的众多模块,并引入了"约定优于配置"的理念,使得开发者能够更加专注于业务逻辑的实现。本章将从基础知识开始,逐步深入探讨Spring Boot的核心特性和最佳实践。
1.1 快速入门Spring Boot
要入门Spring Boot,我们通常从创建一个"Hello, World!"的项目开始。通过Spring Initializr(https://start.spring.io/)可以快速生成项目基础结构。以下是一个简单的例子:
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class, args);
}
}
@RestController
class HelloController {
@GetMapping("/")
String index() {
return "Hello, Spring Boot!";
}
}
上述代码中,我们定义了一个 Application 类并使用 @SpringBootApplication 注解,它是一个组合注解,包括 @Configuration 、 @EnableAutoConfiguration 和 @ComponentScan 。 HelloController 是一个RESTful控制器,提供了一个返回"Hello, Spring Boot!"的HTTP GET请求处理。
在理解了Spring Boot的基础之后,我们可以深入学习如何使用其提供的高级特性,如自动配置、嵌入式服务器、外部化配置、安全控制和数据访问等。这将帮助开发者构建高效、可维护的后端服务。
2. Vue 3前端框架应用
2.1 Vue 3核心特性解析
2.1.1 响应式系统原理
Vue 3的响应式系统是其核心特性之一,相较于Vue 2有了显著的改进。Vue 3的响应式系统不再依赖于 Object.defineProperty() 这一老旧技术,而是通过使用ES6的 Proxy 对象,对数据拦截提供全面的支持。 Proxy 能够拦截对对象属性的读取和写入操作,允许Vue在数据变化时做出响应。
下面是 Proxy 实现响应式的一个简单示例:
let reactiveData = { count: 1 };
const proxy = new Proxy(reactiveData, {
get(target, key) {
console.log('访问属性', key);
return target[key];
},
set(target, key, value) {
console.log('修改属性', key, value);
target[key] = value;
return true; // 表示赋值操作成功
}
});
proxy.count; // 输出 "访问属性 count"
proxy.count = 2; // 输出 "修改属性 count 2"
在这个例子中,我们创建了一个 Proxy 对象,监视了 reactiveData 对象的属性访问和修改。每当属性被读取时, get 方法被调用;每当属性被赋新值时, set 方法被调用。在Vue 3中,这一机制被用于追踪依赖,并在数据发生变化时触发视图的更新。
2.1.2 组合式API介绍
Vue 3引入了组合式API(Composition API),这是一种新的API设计风格,旨在解决Vue 2中options API的一些局限性。组合式API的核心是一个名为 setup 的新组件选项,它是一个接收props和context作为参数的函数,并在函数内部定义响应式状态和方法。这允许开发者灵活地组织逻辑,并有助于逻辑复用。
import { ref, computed } from 'vue';
export default {
setup(props) {
const count = ref(0);
const doubleCount = computed(() => count.value * 2);
function increment() {
count.value++;
}
return {
count,
doubleCount,
increment
};
}
};
在这个 setup 函数中,我们使用 ref 来创建一个响应式的数据 count ,并定义了一个计算属性 doubleCount 。此外,我们还定义了一个方法 increment 用于修改 count 。所有这些在 setup 函数中定义的响应式状态和方法都将被返回并暴露给组件的模板。
2.2 Vue 3项目构建与管理
2.2.1 使用Vite构建项目
Vite是Vue 3推荐的开发服务器,它使用了原生ESM(ECMAScript Modules)导入,能够提供更快的冷启动和热模块替换(HMR)速度。Vite将传统的构建过程拆分为两个阶段:预构建依赖和开发服务器启动。
以下是使用Vite创建一个新项目的命令:
npm create vite@latest my-vue-app -- --template vue
cd my-vue-app
npm install
npm run dev
这段命令将会创建一个名为 my-vue-app 的项目目录,并使用 vue 模板初始化项目。安装完依赖后,可以通过 npm run dev 启动开发服务器。在开发过程中,Vite会自动处理依赖预构建,优化构建性能。
2.2.2 Vue Router与状态管理
在Vue 3中,与路由管理和状态管理相关的库也有所更新,以更好地支持组合式API。Vue Router 4是与Vue 3兼容的路由库,提供了更清晰的路由配置方式和更好的性能。
Vue Router 4的基本使用如下:
import { createRouter, createWebHistory } from 'vue-router';
const routes = [
{ path: '/', component: Home },
{ path: '/about', component: About }
];
const router = createRouter({
history: createWebHistory(),
routes
});
export default router;
在组合式API的场景下,可以在 setup 函数中使用 useRouter 或 useRoute 来访问路由信息或进行导航。
对于状态管理,Vue 3推荐使用其原生的 provide 和 inject 机制,或者使用Vuex 4。Vuex 4对组合式API提供了更好的支持,并且提供了更简洁的API。以下是一个使用Vuex 4的状态管理示例:
import { createStore } from 'vuex';
export const store = createStore({
state() {
return {
count: 0
};
},
mutations: {
increment(state) {
state.count++;
}
}
});
// 在组件中使用
import { useStore } from 'vuex';
export default {
setup() {
const store = useStore();
store.commit('increment');
return {
count: store.state.count
};
}
};
在上述代码中,我们定义了一个 store 来管理应用的状态。在组件中,我们通过 useStore 来获取 store 的实例,并通过提交一个mutation来改变状态。需要注意的是,Vuex 4推荐使用函数式组件风格的API,并且与组合式API有着更好的集成方式。
3. Markdown语法与解析技术
3.1 Markdown基础语法
3.1.1 标题、段落和引用
Markdown 的标题是通过在行首添加井号 # 开始,一个井号代表一级标题,两个代表二级标题,以此类推。例如, # 这是一个一级标题 。标题在视觉上会比普通文本大,并且在文档结构中起到重要作用,方便阅读者快速定位内容。
段落是 Markdown 中最基础的元素,由连续的文本行组成,段落之间默认有一个空行分隔。要创建一个段落,只需用一个或多个空行将一行文本与其他行隔开即可。
引用文本的格式是在句子前面添加一个右尖括号 > 。例如, > 这是一段引用文本 。引用可以嵌套使用,每个新的引用块前面加一个 > 就可以创建更深层级的引用。
这是一个段落。
> 这是一个引用段落。
>
>> 这是一个嵌套引用。
3.1.2 列表、代码块和表格
无序列表使用星号 * 、加号 + 或减号 - 开头,有序列表使用数字接一个英文句点 1. 。例如:
* 项目一
+ 项目二
- 项目三
代码块是使用反引号 ` 包围一段文本,并且通常在语言标识后可以给代码块添加语法高亮。例如,一个 JavaScript 代码块:
const message = 'Hello, Markdown!';
表格则通过竖线 | 和短横线 - 组合定义,竖线分隔各列,短横线分隔表头和其他行。例如:
| 标题一 | 标题二 | 标题三 |
| ------ | ------ | ------ |
| 单元格1 | 单元格2 | 单元格3 |
| 单元格4 | 单元格5 | 单元格6 |
Markdown 的这些基础语法使得文本格式化变得简单,但其真正的力量在于能够快速生成结构化文档,使其在编写技术文档和文章时显得尤为有用。
3.2 Markdown解析器的实现
3.2.1 解析原理概述
Markdown 的解析原理大体可以分为两个步骤:解析与渲染。首先,解析器读取 Markdown 文档,根据 Markdown 的语法规则转换成内部结构,这个结构通常是抽象语法树(Abstract Syntax Tree, AST)。然后,渲染器将 AST 转换成目标格式,比如 HTML,最终展示在网页上。
解析器根据实现方式可以分为两种:
- 解析器生成器 :这一类工具可以生成解析器的代码,比如 PEG.js 和 Marp ,这些工具通常使用特定的语法定义 Markdown 的解析规则。
- 手动编写解析器 :开发者也可以手动编写代码来解析 Markdown 文档。这通常涉及到读取输入文本,使用正则表达式或字符串操作来分割和处理文本,然后构建出 AST。
3.2.2 自定义解析器的应用场景
在某些场景下,现有的 Markdown 解析器无法满足特定的需求,比如需要支持一些定制的语法,或者需要在解析过程中执行一些自定义的逻辑(比如代码高亮、图表生成等)。这时,就需要编写一个自定义的解析器来处理 Markdown 文档。
自定义解析器的实现可以通过多种编程语言,如 JavaScript、Python、Java 等。一个简单的自定义解析器可能涉及以下步骤:
- 词法分析(Lexical Analysis) :将输入的 Markdown 文本分解为一个个词法单元(tokens),如标题、段落、代码块等。
- 语法分析(Syntax Analysis) :根据 Markdown 语法规则分析词法单元序列,构造出 AST。
- 遍历 AST :递归遍历 AST 并在遍历过程中处理每个节点,比如渲染 HTML 或者执行其他逻辑。
- 输出 :根据处理后的 AST 生成最终的文档格式。
以下是一个简单的 JavaScript 实现的自定义解析器示例,演示解析并转换标题格式:
const markdown = `
# Markdown标题
## 子标题
### 更小的标题
`;
// 词法分析函数
function tokenize(markdown) {
// 正则表达式匹配标题
const regex = /^#{1,6}\s+(.*)$/gm;
const tokens = [];
let match;
while ((match = regex.exec(markdown)) !== null) {
tokens.push(match[1]);
}
return tokens;
}
// 语法分析函数
function parse(tokens) {
const ast = [];
tokens.forEach((token, index) => {
// 构建AST树结构
const depth = token.match(/^\#/).length;
const title = token.replace(/^\#/g, '').trim();
ast.push({
type: 'header',
depth: depth,
content: title
});
});
return ast;
}
// 遍历AST并输出为HTML
function render(ast) {
let html = '';
ast.forEach((node) => {
const tag = 'h' + node.depth;
html += `<${tag}>${node.content}</${tag}>\n`;
});
return html;
}
// 主流程
const tokens = tokenize(markdown);
const ast = parse(tokens);
const htmlOutput = render(ast);
console.log(htmlOutput);
输出结果将会是 HTML 格式的标题结构。自定义解析器提供了灵活性,但也需要更多的开发和维护工作。对于大多数情况,使用现成的解析器会更简单、高效。
4. 关系型数据库操作及ORM框架使用
在现代软件开发中,关系型数据库因其稳定性和成熟的事务处理机制,仍然是存储结构化数据的首选。然而,直接使用原生的SQL语句操作数据库往往会使代码耦合度过高,维护困难。这时,对象关系映射(ORM)框架就显得尤为重要,它提供了一种将对象模型映射到关系数据库模型的便捷方式,简化了数据库操作。本章将带你深入了解关系型数据库的基础操作以及如何在项目中应用ORM框架。
4.1 关系型数据库基础
关系型数据库以其表格形式存储数据,每张表都有固定的列,通过主键、外键等约束保证数据的完整性和一致性。要高效地使用关系型数据库,开发者必须首先理解数据库设计原则以及SQL语言。
4.1.1 数据库设计原则
数据库设计是构建高性能、可扩展、易维护的应用程序的关键。设计良好的数据库应当遵循以下原则:
- 规范化 :通过规范化过程减少数据冗余,确保数据的一致性。规范化可以分为多个级别,第一范式(1NF)、第二范式(2NF)、第三范式(3NF)是常见的标准。
- 数据完整性 :定义主键约束、外键约束、检查约束等确保数据的准确性和一致性。
- 索引优化 :适当使用索引可以显著提升查询性能,但索引并非越多越好,需要根据查询模式和更新频率合理设计。
- 分区和分片 :大型数据库可以通过分区和分片技术将数据分布存储,以提升性能和可扩展性。
4.1.2 SQL语言要点
结构化查询语言(SQL)是与关系型数据库交互的标准方式。以下是一些SQL编写的关键点:
- 数据定义语言(DDL) :使用
CREATE、ALTER、DROP等命令来操作数据库结构。 - 数据操作语言(DML) :通过
INSERT、UPDATE、DELETE操作数据记录。 - 数据查询语言(DQL) :
SELECT语句是数据查询的核心,结合JOIN、WHERE、GROUP BY等子句可以实现复杂查询。 - 事务控制语言(TCL) :使用
COMMIT、ROLLBACK、SAVEPOINT等命令管理事务,保证数据操作的原子性、一致性、隔离性和持久性。
4.2 ORM框架的应用
对象关系映射框架极大地简化了数据库操作,让开发者能以面向对象的方式操作关系数据库。接下来,我们将深入了解MyBatis-Plus框架,这是一个增强版的MyBatis框架,提供了大量实用的特性。
4.2.1 MyBatis-Plus框架简介
MyBatis-Plus是在MyBatis的基础上只做增强不做改变,为简化开发、提高效率而生。它具备如下特点:
- 通用 CRUD 操作 :自动实现 CRUD 接口,让开发者摆脱繁琐的接口编写。
- 代码生成器 :强大的代码生成工具,减少大量重复代码编写工作。
- 性能分析插件 :提供性能分析插件,方便了解 SQL 执行性能。
- 逻辑删除 :支持逻辑删除功能,使得数据删除操作可逆。
- 分页插件 :提供多种分页方式,支持常见的数据库。
4.2.2 实体类映射与操作实践
在MyBatis-Plus中,实体类与数据库表之间通过注解或XML文件映射。以注解为例,以下是一个简单的用户实体类映射示例:
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
@TableName("user")
public class User {
@TableId
private Long id;
private String name;
private String email;
// getter and setter
}
通过上述注解,MyBatis-Plus知道如何将 User 类的对象映射到名为 user 的数据库表中,并且 id 字段是表的主键。
在操作实践中,我们通常会使用Service层的CRUD接口,例如:
@Autowired
private UserService userService;
public User getUserById(Long id) {
return userService.getById(id);
}
public boolean saveUser(User user) {
return userService.save(user);
}
public boolean updateUser(User user) {
return userService.updateById(user);
}
public boolean deleteUser(Long id) {
return userService.removeById(id);
}
以上是使用MyBatis-Plus进行基本的数据库操作示例。而使用该框架,开发者可以不必编写繁琐的CRUD代码,直接调用Service层的方法即可实现数据库的基本操作。
本章介绍了关系型数据库的基本操作以及如何通过MyBatis-Plus框架简化数据库操作。数据库设计原则和SQL语言要点是数据库操作的基础,而MyBatis-Plus框架作为ORM实践提供了高效、简洁的数据库交互方式。通过本章内容,你可以了解到数据库的基础知识和框架使用技巧,从而在实际开发中更加游刃有余。
5. RESTful API设计与实现
5.1 RESTful设计原则
5.1.1 资源的定义与定位
RESTful架构风格中,所有的内容都被视为资源,每个资源都有一个唯一的资源标识符(URI)。在设计RESTful API时,资源的定义和定位至关重要,它影响了API的可读性、可用性和维护性。资源应当被命名得尽可能的简洁明了,例如 /users 表示用户列表资源,而 /users/{userId} 表示特定用户资源。
资源的定义应当基于业务逻辑,而不是数据存储细节。例如,不应该将“订单”资源命名为“订单表”,因为“表”是一个数据库概念,不直接对应于业务逻辑中的订单概念。资源定位应当层次清晰、易于导航,以便于客户端开发者理解和使用API。
5.1.2 HTTP方法与状态码的选择
在RESTful API设计中,HTTP方法(GET, POST, PUT, DELETE等)被用来表达客户端对资源的意图,而HTTP状态码(如200 OK, 404 Not Found)则提供了操作结果的反馈。正确地选择HTTP方法和状态码是实现RESTful API的关键。
GET方法用于获取资源,例如,获取用户列表可以使用GET请求 /users 。POST方法通常用于创建新资源,例如,创建新用户可以使用POST请求 /users 。PUT方法用于更新资源(如果资源不存在,则创建资源),而DELETE方法用于删除资源。
在实际操作中,必须考虑幂等性和安全性。幂等性意味着同样的请求执行多次与执行一次具有相同的效果,例如,多次使用PUT方法更新资源应该不会对资源状态产生更多改变。安全性意味着请求不会改变资源的状态,例如,使用GET方法获取资源信息是安全的。
5.2 接口的安全与性能优化
5.2.1 跨域处理与安全性加固
在前后端分离的架构中,API接口可能会遇到跨域请求的问题。跨域资源共享(CORS)是一种安全机制,它限制了哪些网站可以访问Web应用服务器上的资源。解决跨域问题通常需要在服务器端配置CORS策略,允许来自特定域的请求。
安全性加固还包括了防止常见的Web攻击,如SQL注入、XSS攻击和CSRF攻击。要防范这些攻击,需要对用户输入进行验证和过滤,确保不会执行恶意代码。
5.2.2 接口缓存与并发控制
为了提高RESTful API的性能,接口缓存是一个重要的优化措施。可以使用HTTP缓存控制头(如 Cache-Control )来指示客户端或代理缓存API响应,减少不必要的服务器请求。
对于频繁变更的资源,可以通过使用版本号、时间戳或ETag(实体标签)来管理缓存。ETag允许服务器指定一个资源的唯一标识,如果在后续请求中资源没有改变,则返回304 Not Modified响应,表示缓存仍然有效。
并发控制也是提升性能的关键点,尤其是在高并发环境下。合理使用乐观锁或悲观锁机制,可以有效避免数据不一致问题。乐观锁通常通过资源的版本号或时间戳来实现,而悲观锁则需要在数据库层面进行控制,例如使用事务和行锁。
示例代码块:
下面的代码块展示了如何在Spring Boot应用中实现一个简单的RESTful接口,该接口演示了如何使用HTTP方法和状态码,同时包含了跨域处理和安全性加固的实践。
@RestController
@RequestMapping("/api/users")
public class UserController {
@Autowired
private UserService userService;
// 获取用户列表
@GetMapping
public ResponseEntity<List<User>> getUsers() {
List<User> users = userService.findAll();
return ResponseEntity.ok(users);
}
// 创建用户
@PostMapping
public ResponseEntity<User> createUser(@RequestBody User user) {
User createdUser = userService.save(user);
return new ResponseEntity<>(createdUser, HttpStatus.CREATED);
}
// 更新用户信息
@PutMapping("/{id}")
public ResponseEntity<User> updateUser(@PathVariable Long id, @RequestBody User userDetails) {
User updatedUser = userService.update(id, userDetails);
return ResponseEntity.ok(updatedUser);
}
// 删除用户
@DeleteMapping("/{id}")
public ResponseEntity<Void> deleteUser(@PathVariable Long id) {
userService.deleteById(id);
return ResponseEntity.noContent().build();
}
// 跨域配置
@Bean
public CorsFilter corsFilter() {
UrlBasedCorsConfigurationSource source = new UrlBasedCorsConfigurationSource();
CorsConfiguration config = new CorsConfiguration();
config.setAllowCredentials(true);
config.addAllowedOrigin("http://example.com"); // 允许的域
config.addAllowedHeader("*");
config.addAllowedMethod("*");
source.registerCorsConfiguration("/**", config);
return new CorsFilter(source);
}
}
在上述代码中, UserController 类定义了四个RESTful方法,分别对应于获取用户列表、创建新用户、更新用户信息和删除用户的功能。每个方法都返回了相应的HTTP状态码,以正确地反映操作结果。 corsFilter 方法则配置了跨域资源共享,允许特定的域进行跨域请求。
表格示例:
| HTTP方法 | URI路径 | 功能 | 幂等性 | 安全性 | |-----------|----------|----------|------------|------------| | GET | /api/users | 获取用户列表 | 是 | 是 | | POST | /api/users | 创建新用户 | 否 | 否 | | PUT | /api/users/{id} | 更新用户信息 | 是 | 否 | | DELETE | /api/users/{id} | 删除用户 | 是 | 否 |
此表格说明了不同HTTP方法的资源路径和功能,以及它们是否满足幂等性和安全性。这些信息有助于客户端开发者更好地理解API的行为,并据此设计客户端代码。
以上章节内容介绍了RESTful API设计的基本原则和实践,包括资源的定义与定位、HTTP方法与状态码的选择,以及接口的安全与性能优化措施。通过这些实践,能够开发出既安全又高效的API接口。
6. 用户认证与授权机制
在现代的Web应用中,用户认证与授权机制是保障系统安全的基础。本章节将从认证与授权的基本概念出发,深入解析其在实际开发中的应用策略,并讨论如何实现安全、高效的用户管理。
6.1 认证机制的实现
认证是确认用户身份的过程,它的目的是确保只有合法用户可以访问系统资源。在本节中,我们将重点探讨两种流行的认证机制:JWT和OAuth2.0。
6.1.1 JWT认证流程解析
JSON Web Tokens(JWT)是一种用于双方之间安全传输信息的简洁的、URL安全的表示声明的方式。JWT认证流程通常包含以下步骤:
- 用户登录 :用户通过输入用户名和密码尝试登录系统。
- 生成Token :一旦用户身份验证成功,服务端将生成一个JWT Token,并将其返回给用户。
- 保存Token :用户将此Token保存在客户端,通常存储在localStorage或cookie中。
- Token传输 :当用户访问需要认证的资源时,携带此Token。
- Token验证 :服务端接收到请求后,解析Token,并验证其有效性。
- 权限控制 :如果Token有效,服务端根据Token中携带的权限信息,决定用户是否有权访问资源。
JWT认证代码示例(Java)
// 使用Spring Security和JWT的认证流程
public class JwtAuthenticationFilter extends OncePerRequestFilter {
@Override
protected void doFilterInternal(HttpServletRequest request,
HttpServletResponse response,
FilterChain filterChain) throws ServletException, IOException {
String token = request.getHeader("Authorization");
if (token != null && token.startsWith("Bearer ")) {
try {
// 验证Token的合法性并解析用户信息
Claims claims = Jwts.parserBuilder()
.setSigningKey("your-secret-key".getBytes(StandardCharsets.UTF_8))
.build()
.parseClaimsJws(token.replace("Bearer ", ""))
.getBody();
String username = claims.getSubject();
// 设置SecurityContext中的认证信息
UsernamePasswordAuthenticationToken auth = new UsernamePasswordAuthenticationToken(
username, null, new ArrayList<>());
SecurityContextHolder.getContext().setAuthentication(auth);
} catch (Exception e) {
// Token无效或过期等异常处理
response.sendError(HttpServletResponse.SC_UNAUTHORIZED);
return;
}
}
filterChain.doFilter(request, response);
}
}
在上述Java代码中, JwtAuthenticationFilter 扩展了 OncePerRequestFilter 以保证每个请求都会被过滤一次。如果请求头中包含有效的JWT Token,那么就解析Token中的用户信息,并将其设置在 SecurityContextHolder 中。这是Spring Security框架中处理认证信息的标准方式。
6.1.2 OAuth2.0协议应用
OAuth 2.0是一个开放标准,允许用户授权第三方应用访问他们存储在其他服务提供者上的信息,而无需将用户名和密码提供给第三方应用。OAuth2.0的认证流程涉及四种角色:资源拥有者、资源服务器、客户端和认证服务器。
以下是OAuth2.0的认证流程:
- 资源拥有者授权 :用户访问客户端应用并同意授权。
- 获取授权码 :客户端应用向认证服务器请求授权码,通过重定向的方式将用户导向认证服务器。
- 交换Token :客户端应用使用授权码向认证服务器请求访问令牌。
- 访问资源 :客户端使用访问令牌请求资源服务器的受保护资源。
OAuth2.0认证流程图
sequenceDiagram
participant U as 用户
participant C as 客户端应用
participant A as 认证服务器
participant R as 资源服务器
U->>C: 访问客户端应用
C->>A: 请求授权码
A->>U: 用户授权
U->>A: 授权码
A->>C: 发放访问令牌
C->>R: 使用令牌请求资源
R->>C: 返回资源
通过使用标准的协议,开发者可以简化认证流程,并利用现有的库和工具轻松集成到自己的应用中。对于复杂的多服务应用,OAuth2.0是推荐的解决方案。
6.2 授权策略的设计
授权是验证用户是否有权限执行特定操作的过程。本节将深入探讨授权策略,特别是基于角色的访问控制(RBAC)和动态权限管理的实现。
6.2.1 基于角色的访问控制(RBAC)
RBAC(Role-Based Access Control,基于角色的访问控制)是一种权限控制机制,它将权限与角色相关联,用户通过被赋予一定的角色从而拥有相应的权限。
在RBAC模型中,通常包含以下实体:
- 用户(User) :系统中的一个账户实体。
- 角色(Role) :一组权限的集合。
- 权限(Permission) :对系统资源的具体操作。
- 会话(Session) :用户与系统交互时的临时状态。
RBAC数据库设计示例
| Table | Fields | | ---------- | ------------ | | users | id, username, password, ... | | roles | id, rolename, description, ... | | permissions| id, permission_name, description, ... | | user_roles | user_id, role_id | | role_permissions | role_id, permission_id |
通过设计这样的数据库结构,开发者可以灵活地为不同的用户分配不同的角色,以及为角色配置不同的权限,从而实现复杂的权限控制逻辑。
6.2.2 动态权限管理实现
随着应用的迭代和业务的发展,静态的权限模型可能无法满足需求。动态权限管理提供了一种更为灵活的方式,可以动态地调整用户权限。
实现动态权限管理通常涉及以下几个步骤:
- 权限数据模型设计 :构建一个权限模型,包括用户、角色、权限和资源的数据结构。
- 权限计算 :根据用户的角色和权限数据动态计算用户访问资源的权限。
- 权限缓存 :为了避免重复计算权限,通常会使用缓存机制优化性能。
- 权限更新机制 :当权限数据发生变化时,需要及时更新缓存,保证权限信息的准确性。
动态权限管理可以在很多方面扩展应用,例如:
- 根据用户的行为动态调整权限。
- 支持更细粒度的权限控制,如基于字段的数据访问权限。
- 提高系统的灵活性和可维护性。
通过上述分析,我们可以看到用户认证与授权机制是构建安全应用不可或缺的环节。无论是使用JWT进行轻量级的认证,还是采用OAuth2.0实现复杂的授权流程,或是通过RBAC和动态权限管理策略维护系统的权限控制,每种方法都有其应用场景和优势。开发者应根据实际需求和业务场景灵活选择适合的认证与授权机制。
7. 应用部署与持续集成/持续部署(CI/CD)
在当今快速发展的IT行业中,应用部署与持续集成/持续部署(CI/CD)已经成为提高软件交付效率和质量的重要实践。这一章节将介绍应用部署的策略以及如何构建一个有效的CI/CD流程。
7.1 应用部署策略
应用部署是软件开发周期中至关重要的一环,它涉及到将应用代码发布到生产环境,以便用户可以使用。部署策略的选择将直接影响应用的可用性和可靠性。
7.1.1 容器化部署的优势
容器化技术如Docker为应用部署带来了革命性的变化。容器封装了应用及其依赖,使得应用可以在任何支持容器运行的环境中一致地运行。这大大简化了开发、测试和生产环境的一致性问题,同时也提高了应用的可移植性。
- 环境一致性: 容器技术确保了应用在开发、测试和生产环境的一致性,避免了因环境差异导致的问题。
- 资源隔离: 容器为应用提供了一个独立的运行空间,不同容器之间互不影响。
- 快速启动: 相比传统的虚拟机,容器能更快地启动,提高了部署的效率。
- 微服务支持: 容器化非常适合微服务架构,每个服务可以独立地进行部署和扩展。
7.1.2 Docker与Kubernetes基础
Docker是目前最流行的容器化技术,而Kubernetes是一个开源的容器编排平台,用于自动化容器应用的部署、扩展和管理。
Docker
Docker的基本概念包括镜像(image)和容器(container):
- 镜像: 镜像是一个可执行包,包含了运行应用程序所需的所有内容——代码、运行时、库、环境变量和配置文件。
- 容器: 容器是从镜像创建的应用实例。可以在本地容器中运行、迁移和扩展。
Docker的基本命令包括构建镜像(docker build)、运行容器(docker run)、查看容器(docker ps)等。
Kubernetes
Kubernetes提供了对容器编排的强大支持,包括但不限于:
- 服务发现和负载均衡: Kubernetes可以使用DNS名或自己的IP地址暴露容器,当容器的IP地址发生变化时,Kubernetes的服务发现机制会自动更新。
- 存储编排: 自动挂载所选存储系统,如本地存储、公共云提供商等。
- 自我修复: 自动重启失败的容器、替换和重新调度容器当节点死亡时、杀死不响应用户定义的健康检查的容器等。
- 自动部署和回滚: 用户可以描述期望的状态,例如哪些容器应该运行,Kubernetes将自动进行必要的操作来达到这个状态。
Kubernetes的核心对象有Pod、Service、Deployment、StatefulSet等,每个对象通过YAML或JSON文件进行定义。
7.2 CI/CD流程构建
持续集成(CI)和持续部署(CD)是现代软件开发实践中的核心概念,CI/CD流水线可以帮助团队快速、有效地构建、测试和发布软件。
7.2.1 Jenkins持续集成流程
Jenkins是一个开源的自动化服务器,广泛用于实现持续集成和持续部署的自动化。Jenkins通过插件的方式提供了丰富的功能。
- 安装和配置: 安装Jenkins,安装必要的插件,配置安全和环境变量。
- 源代码管理: 集成代码仓库(如Git),Jenkins可以拉取最新的代码。
- 构建触发器: 配置触发器,如代码提交、计划任务等,以启动构建过程。
- 构建步骤: 定义构建步骤,如编译代码、运行单元测试、打包等。
- 构建后操作: 构建完成后执行的操作,如通知开发者、发布到测试服务器、生成报告等。
7.2.2 GitHub Actions的实践应用
GitHub Actions是GitHub平台提供的持续集成和持续部署服务,它允许开发者在仓库中自动化软件开发工作流。
- 创建工作流文件: 在仓库的
.github/workflows目录下创建YAML文件定义工作流。 - 定义触发条件: 指定触发工作流的条件,例如push事件、pull request事件或计划任务。
- 设置工作流任务: 使用action市场提供的大量预构建操作或自定义脚本,实现代码构建、测试、部署等步骤。
- 测试与部署: 通过工作流设置,可以自动运行测试脚本和部署应用到指定服务器。
GitHub Actions使得CI/CD流程和代码仓库紧密集成,增强了开发过程的协作性和可维护性。
通过理解并应用容器化技术、Docker、Kubernetes以及CI/CD流程构建工具,开发者能够更加高效地管理和部署应用程序,满足快速变化的市场需求。
简介:这个源码项目是一个基于SpringBoot和Vue3框架构建的在线Markdown文集系统,涵盖Java、Spring Boot、Vue.js以及Markdown解析技术。通过该项目,开发者可以学习到如何搭建后端服务、实现前端交互、进行数据库操作、设计RESTful API、处理认证授权、管理前端路由与状态、部署应用以及进行项目测试。项目的目的是帮助开发者深入理解前后端分离开发模式,并提升使用Spring Boot和Vue 3构建Web应用的能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









