






视频链接:XTuner 微调 LLM:1.8B、多模态、Agent_哔哩哔哩_bilibili
作业:
记录复现过程并截图
基础作业(结营必做)
- 训练自己的小助手认知(记录复现过程并截图)
进阶作业
- 将自我认知的模型上传到 OpenXLab,并将应用部署到 OpenXLab(优秀学员必做)
- 复现多模态微调(优秀学员必做)
OpenXLab 部署教程:Tutorial/tools/openxlab-deploy at camp2 · InternLM/Tutorial · GitHub
笔记:
1、Finetune(FT)简介
目前的LLM是一个Base/Foundation Model,是为了通用/普遍/一般性任务进行预训练,但是如果在各自实际领域或者特定下游任务中使用基座大模型时,其表现是不如领域内训练的模型,所以需要进行领域内的微调。
存在两种FT范式:增量预训练(场景:使Base Model学到一些新知识,如某个垂类领域常识,其训练数据一般是文章、书籍和代码等,不需要进行类似问答这种有监督标注)和指令跟随微调(场景:使Base Model学会对话模版,根据人类指令进行对话,使得模型输出的内容更符合人类的偏好,其训练数据一般是高质量对话、问答数据等)

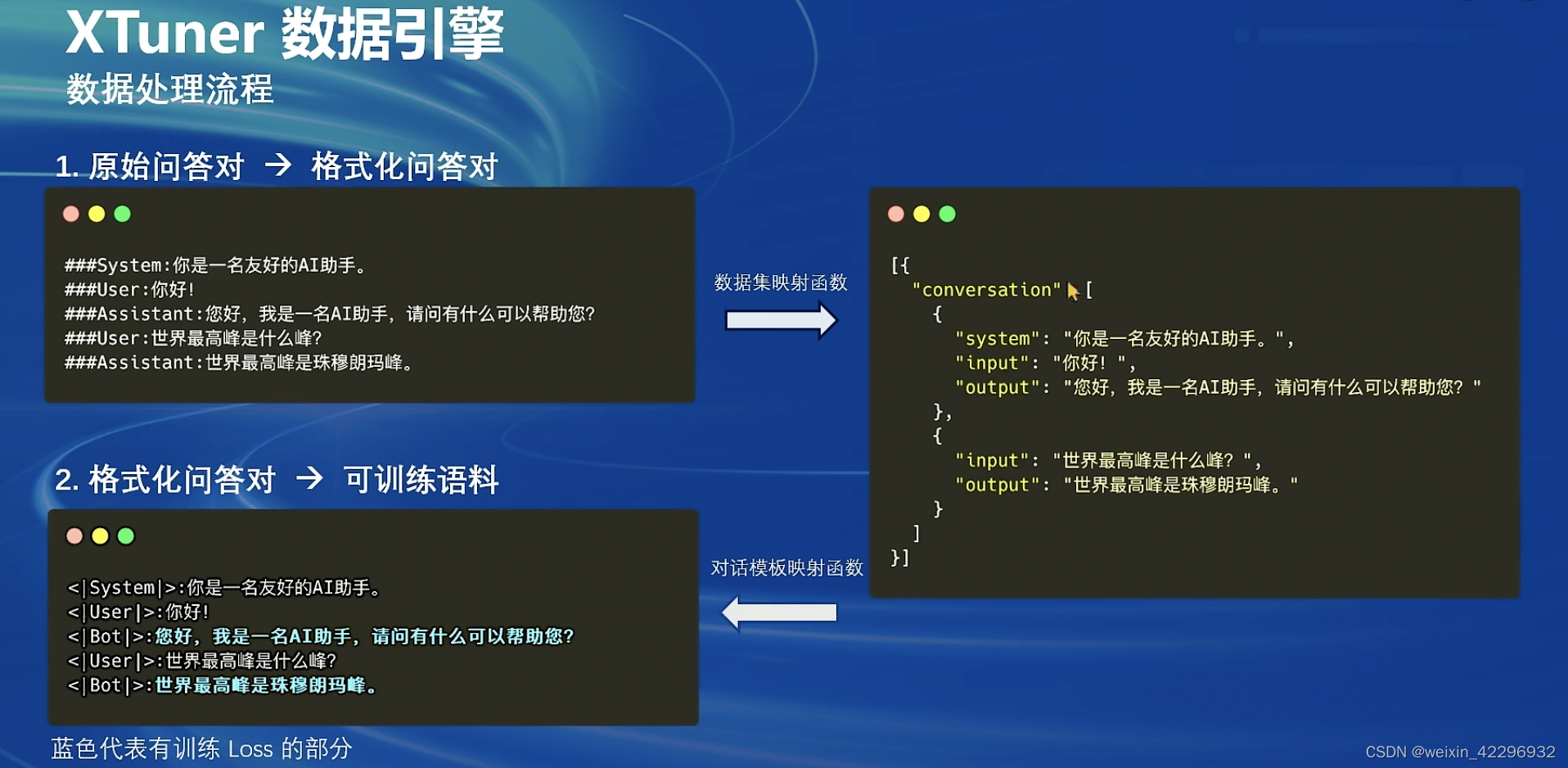
一条数据的一生
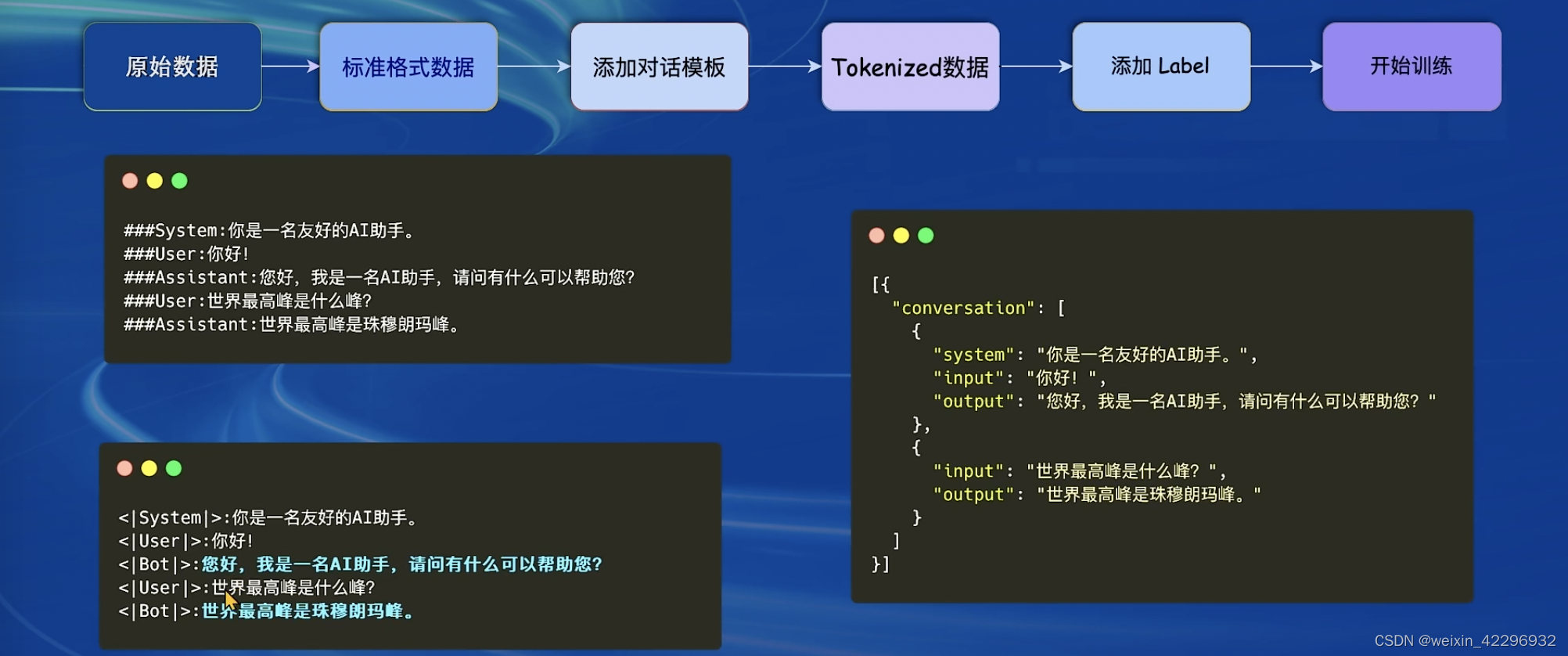
原始数据:通过书籍、爬虫等获得的最初的数据,如上图Assistant:世界最高峰是珠穆朗玛峰。
标准格式数据:即训练框架能够识别的数据格式,如上图System角色,即给模型设置的前置条件,以及User角色,Assistant角色,这些也需要Prompt工程实验。在XTuner框架中,以上图右侧的Json格式来构建。
添加对话模版:对话模版是为了能够让LLM区分出System、User、Assistant,不同厂商的LLM会有不同的模版,如下图所示:只要提供Json格式的conversation,XTuner会自动打包好组装后的数据。
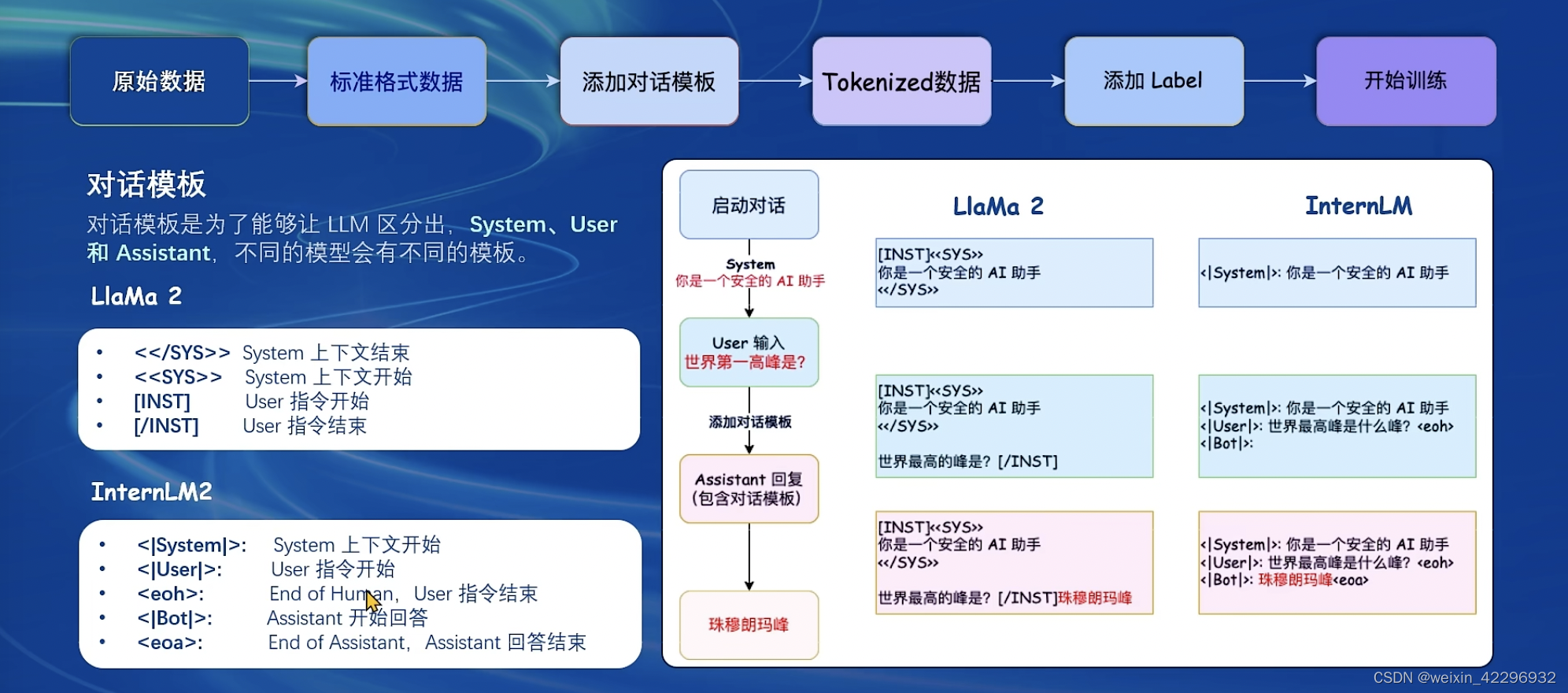
添加Label:|Bot|部分是数据的Label,|User|部分是输入。
微调方案:LoRA&QLoRA,LoRA通过在原本的Linear旁,新增一个支路,包含两个连续的小Linear,新增的这个支路通常叫做Adapter,Adapter参数量远小于原本的Linear,从而能够大幅降低训练的显存消耗。
2、XTuner简介
是一款打包好的轻量级微调工具箱,以配置文件的形式封装了大部分微调场景。对于7B参数量的LLM,微调所需的最小显存仅为8GB,可以使用消费级显卡。XTuner适配了多种生态,支持多种微调算法和策略,覆盖各类SFT场景;支持加载HuggingFace,ModelScope模型或数据集;自动优化加速,开发者无需关注复杂的显存优化与计算加速细节。同时XTuner适配多种硬件,训练方案覆盖Nvidia 20系以上所有显卡。
对比LLaMa-Factory,在不同量级的模型上,其训练速度要更快。在Llama2 70B模型上,在不同的数据长度下,XTuner的表现优于LLaMa-Factory,包括兼容性方面。
XTuner可以快速方便的通过conda create env ,pip install xtuner,挑选配置模版之后,就可以一键训练了,具体如下图所示:
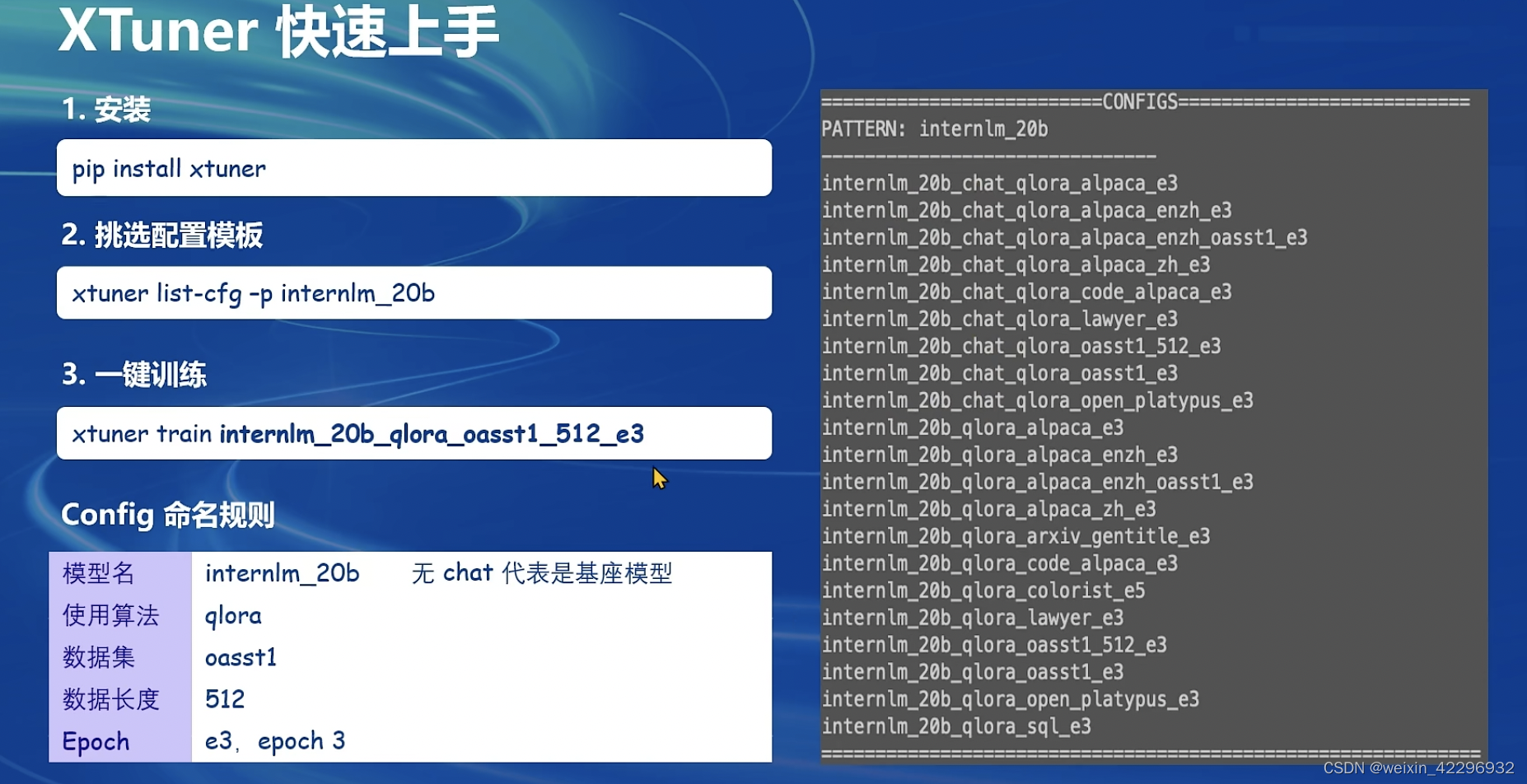

常用的超参都在上图所示的配置文件中。
为了方便开发者查看训练效果,XTuner提供了一键对话接口,如下图所示:
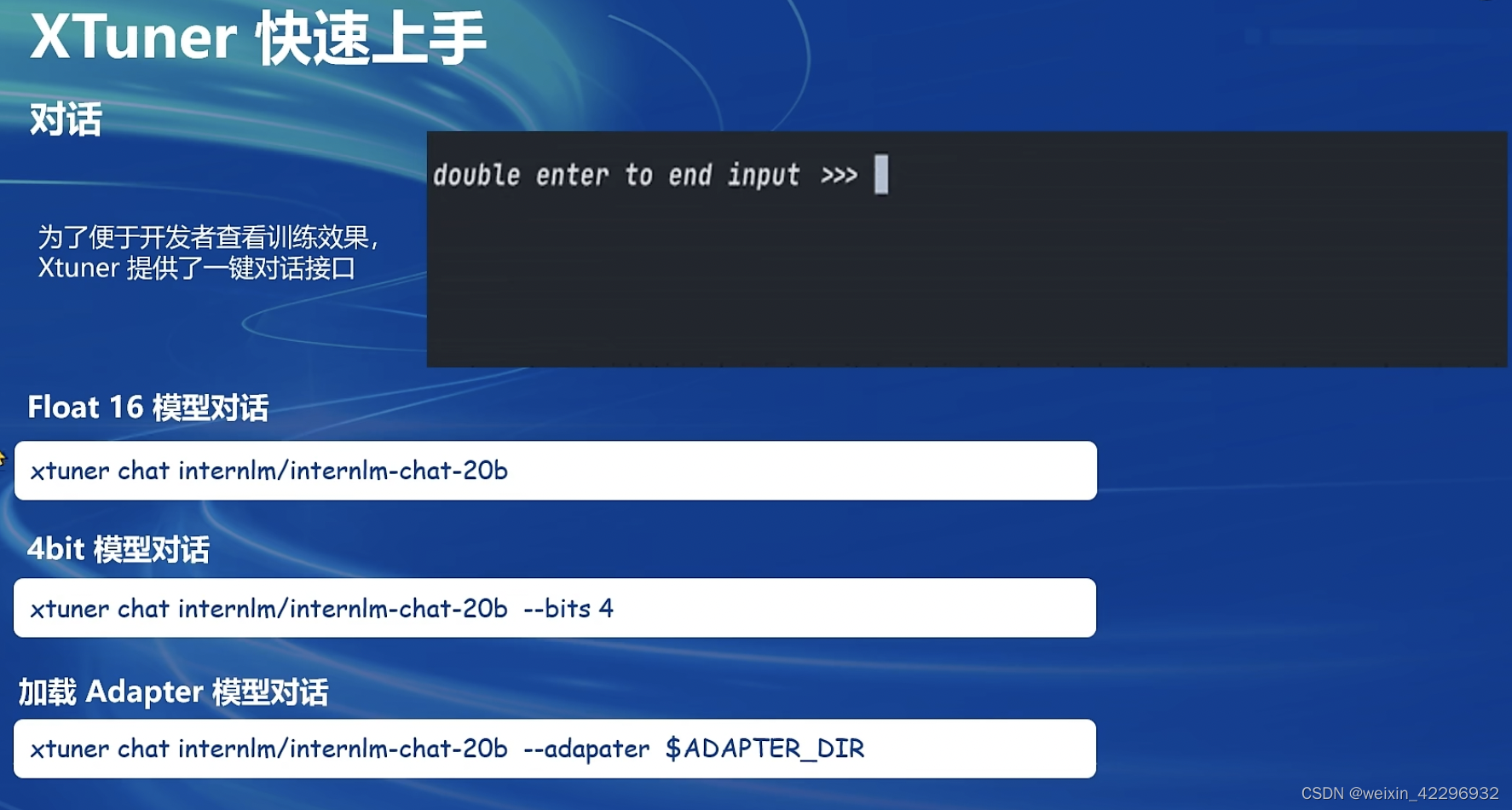
XTuner还支持工具类模型的对话,如下图所示:

XTuner内置了多种热门数据集的映射函数,以及多种对话模版映射函数,开发者可以专注于数据内容,而不必花费精力处理复杂的数据格式。

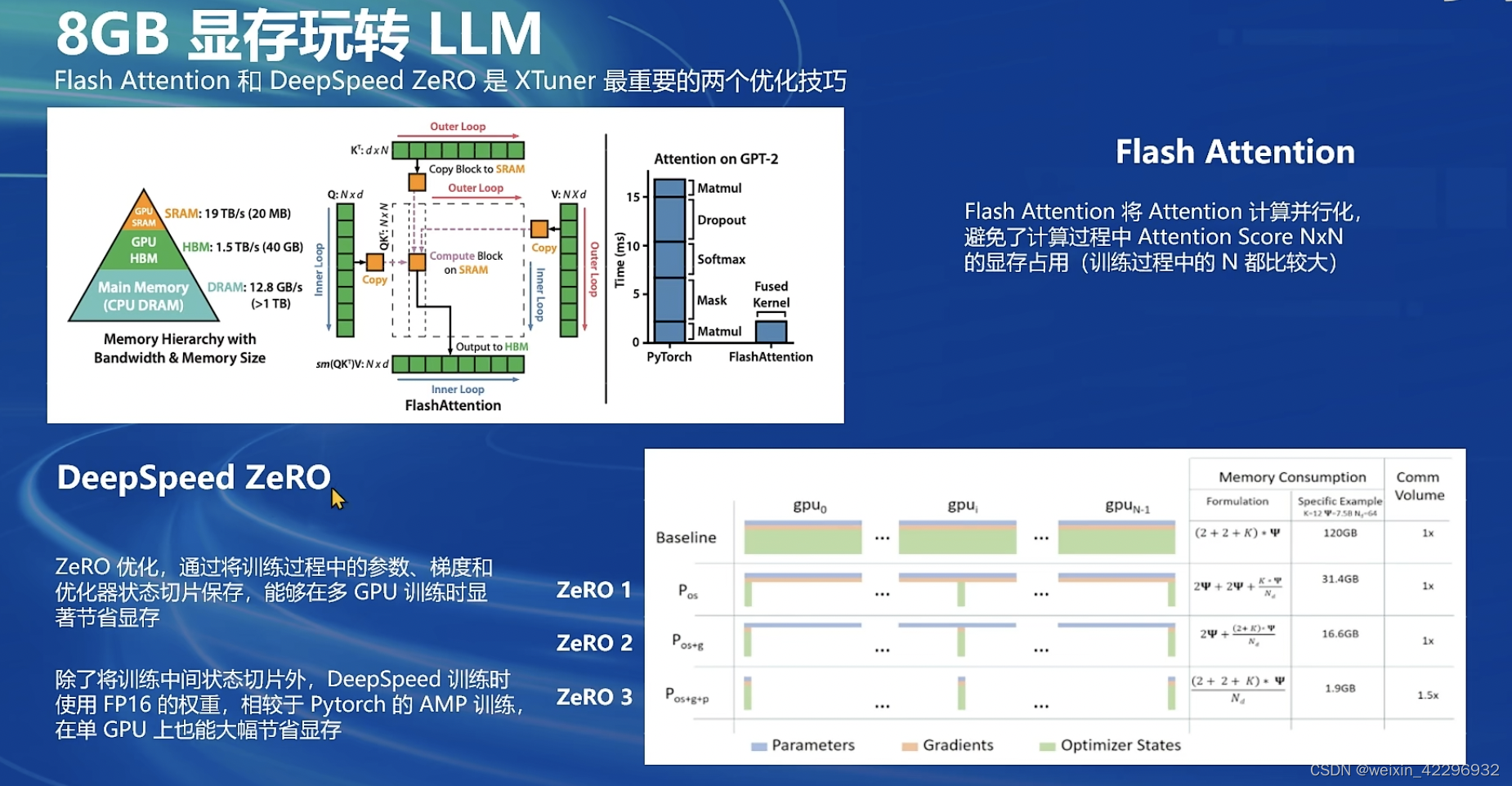
3、8GB显存玩转LLM
XTuner中内置了两种加速方式:Flash Attention和DeepSpeed,如下图所示:
4、InternLM2 1.8B模型

5、多模态LLM微调

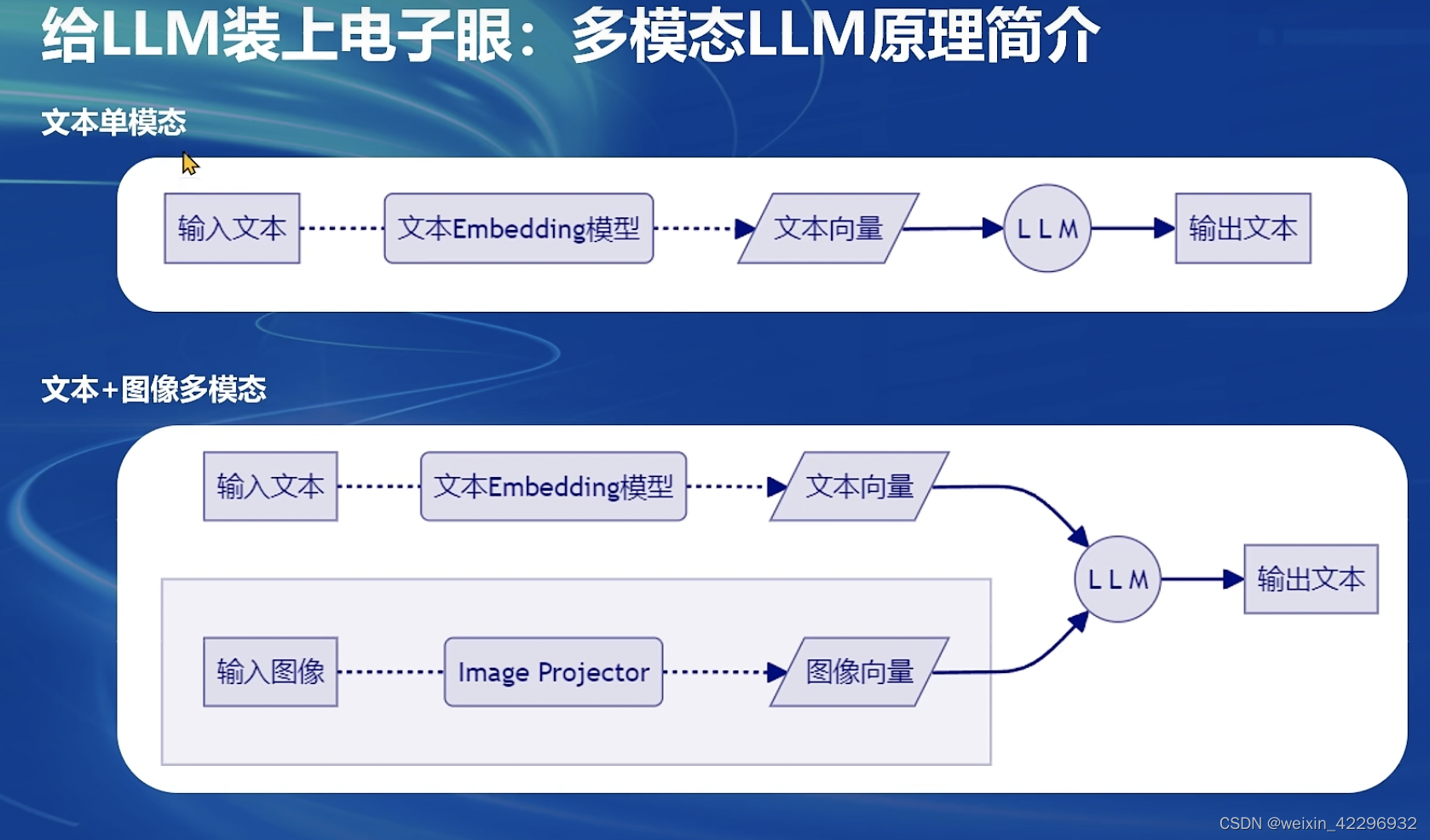
将文本单模态模型微调成文本+图像多模态模型的过程,其实就是训练Image Projector的过程。
使用的方案是:LLaVA方案
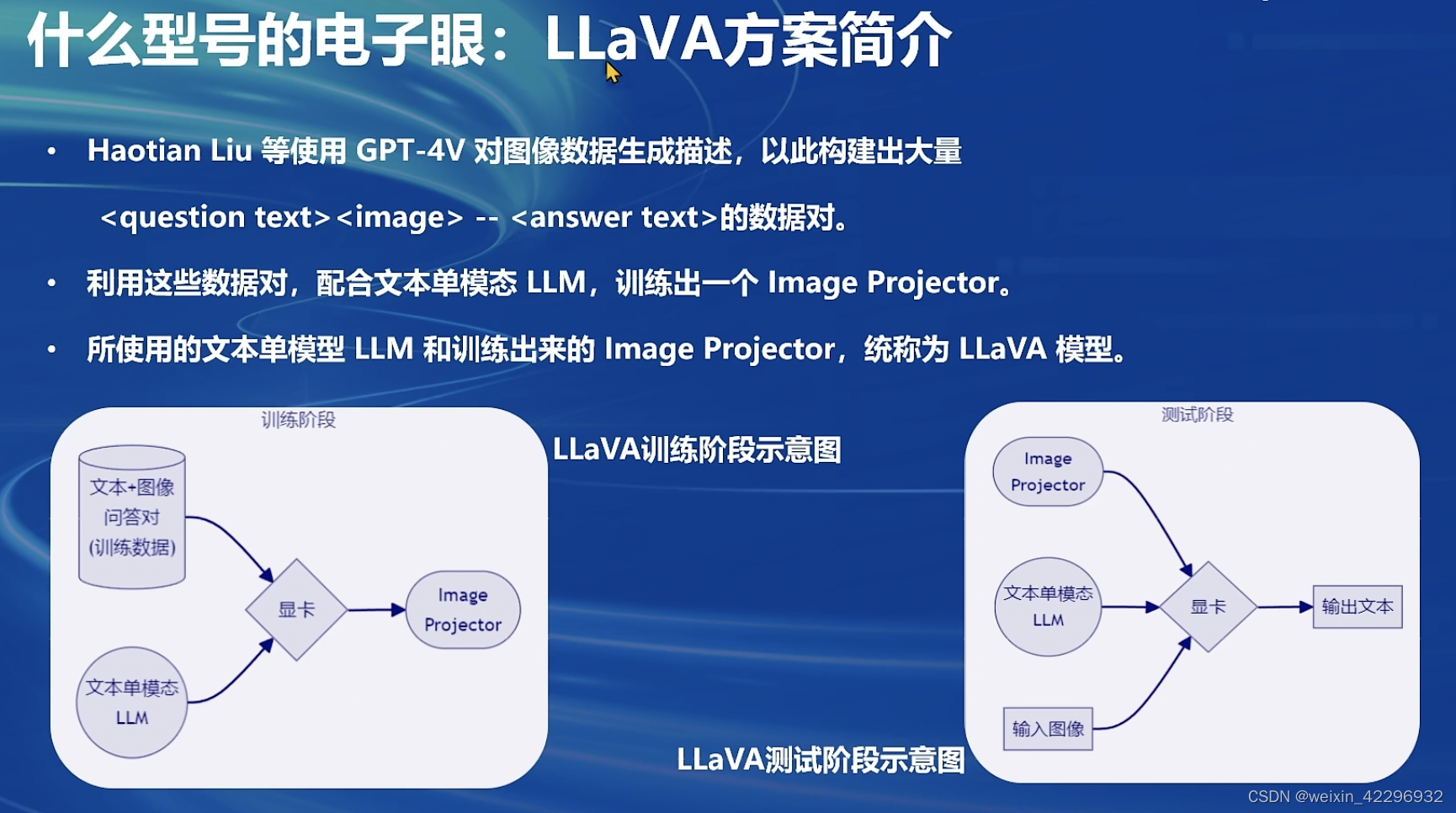

LLaVA方案中,给LLM增加视觉能力的过程,就是训练Image Projector文件的过程,该过程分为2个阶段,即Pretrain和Finetune。
6、Agent
后面再讲。
作业:训练自己的小助手认知
1、创建开发机(test_xtuner)
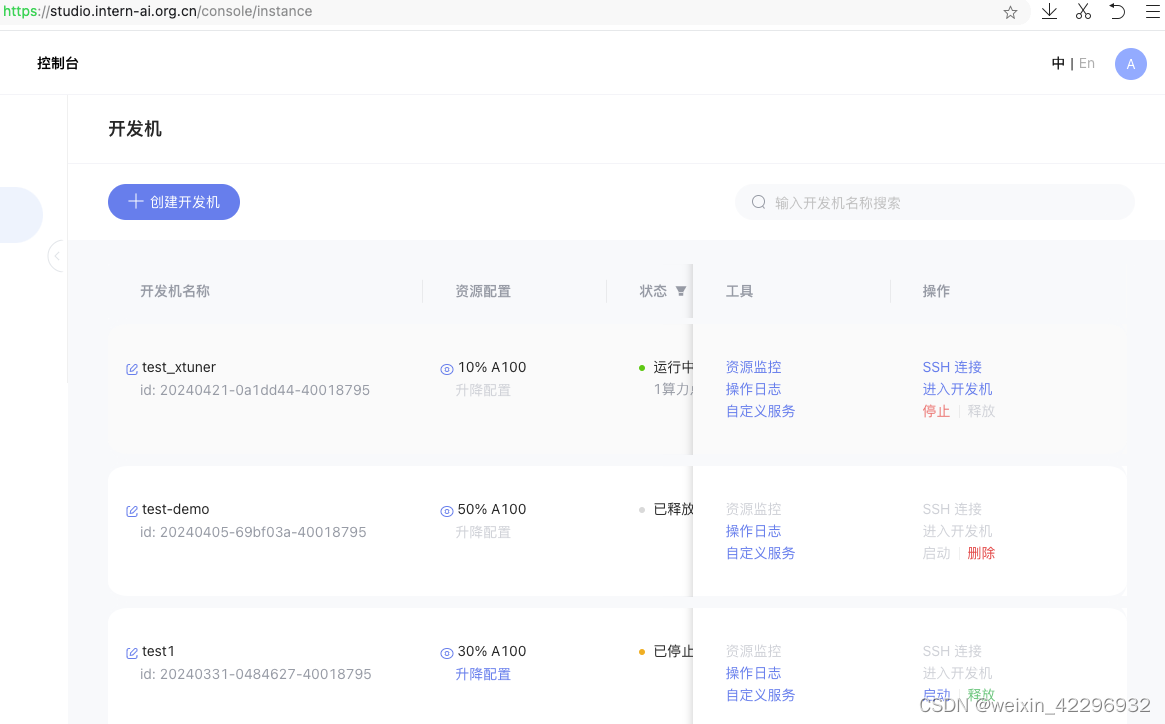
2、安装环境以及依赖
输入:studio-conda xtuner0.1.17
如果在其他平台通过conda create --name xtuner0.1.17 python=3.10 -y 创建env
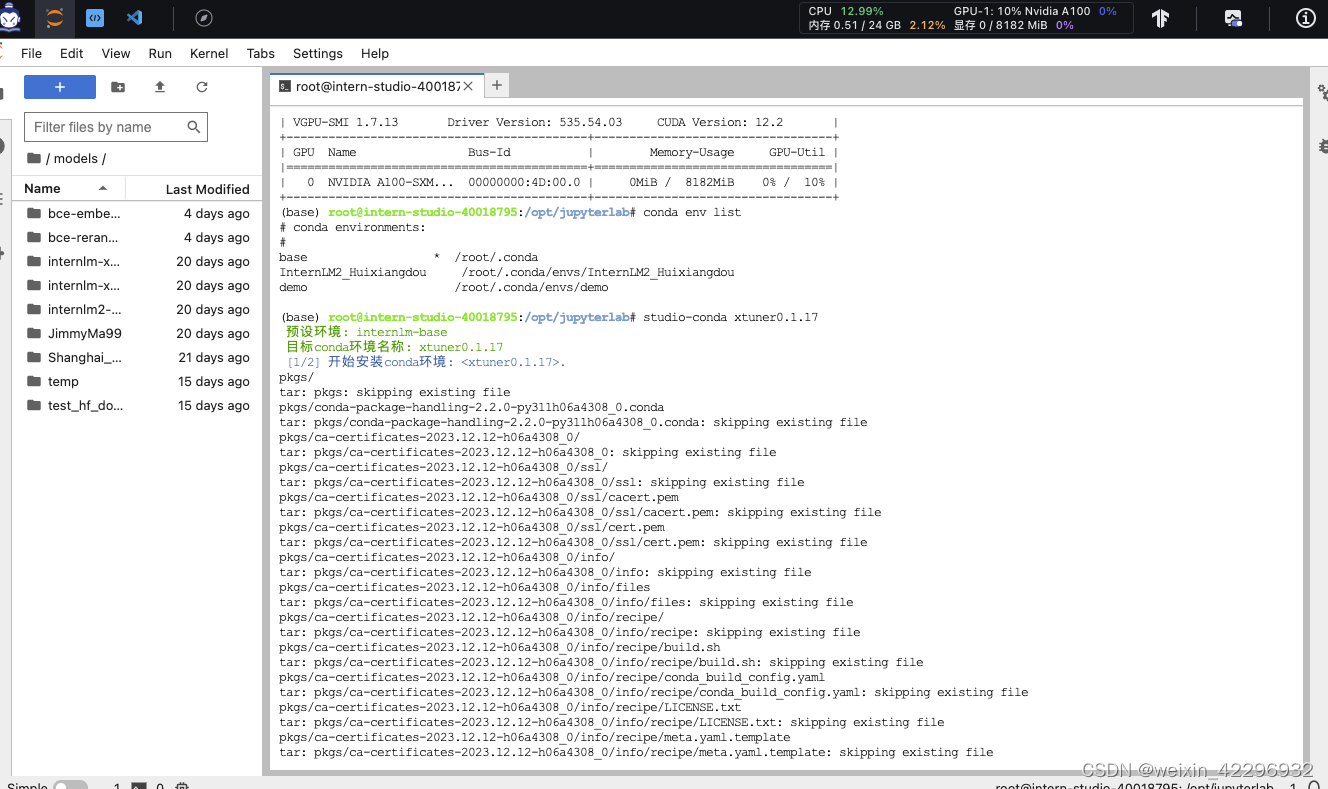
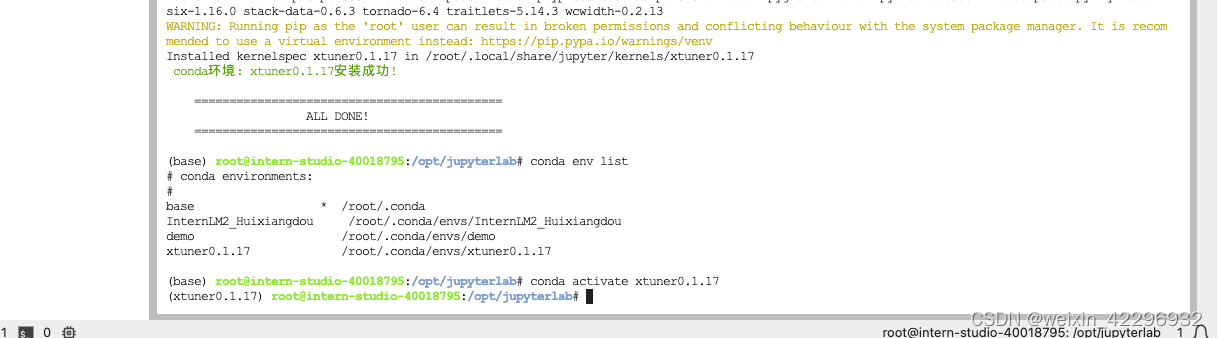
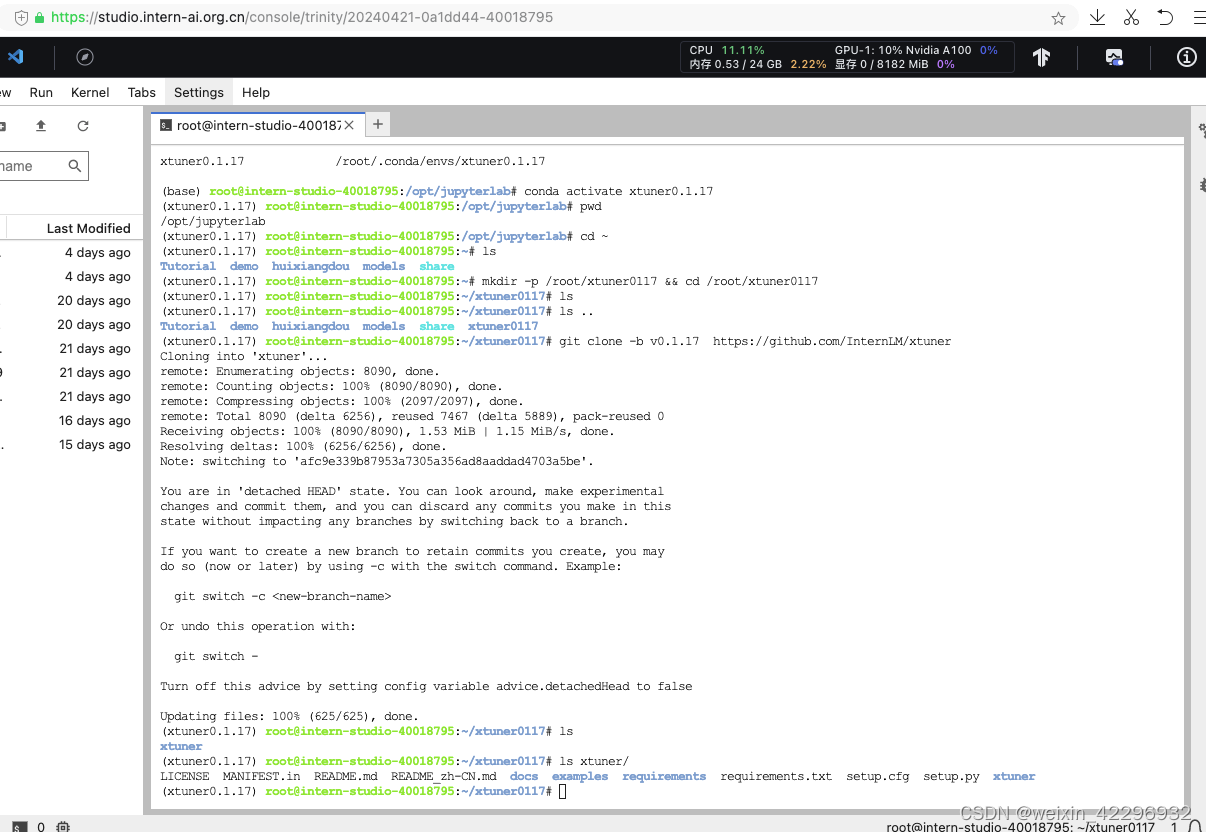
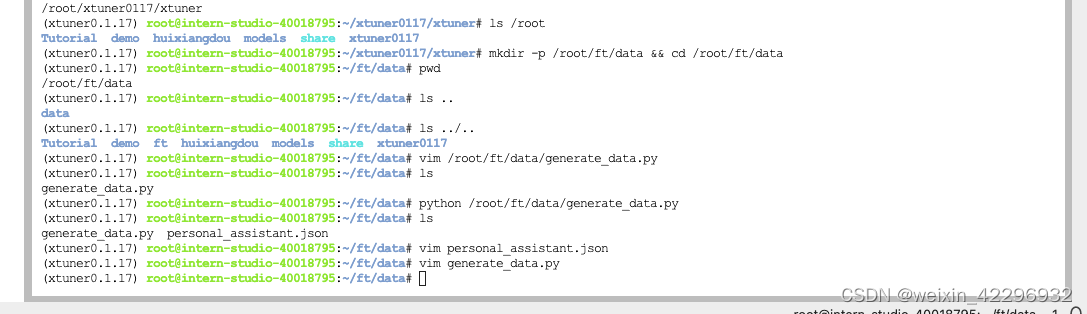
3、准备数据集
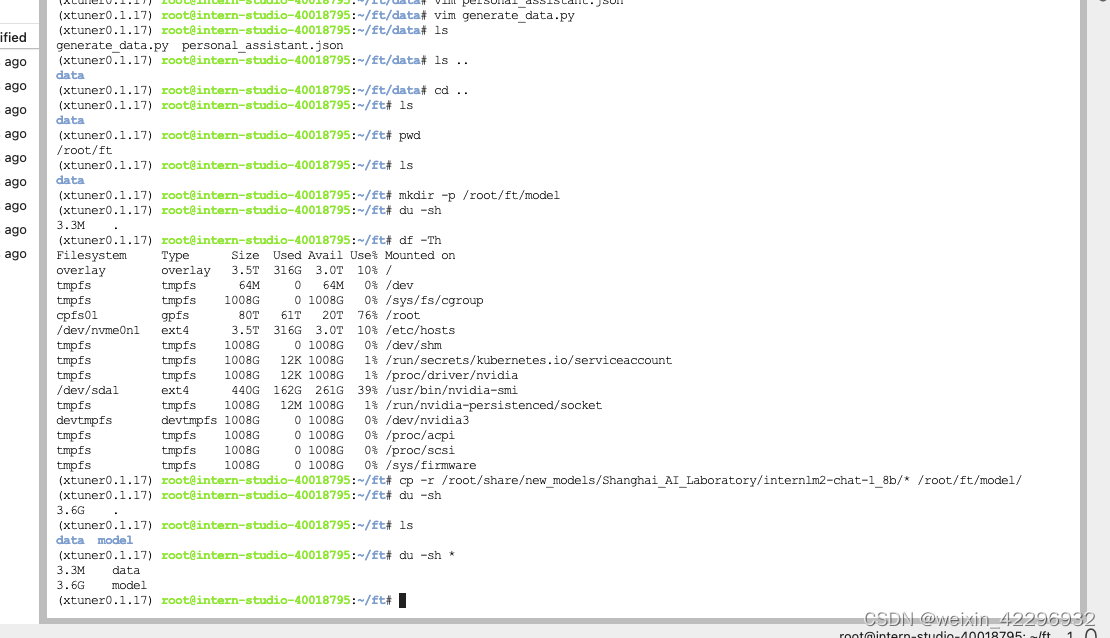
4、模型准备
5、选择配置文件
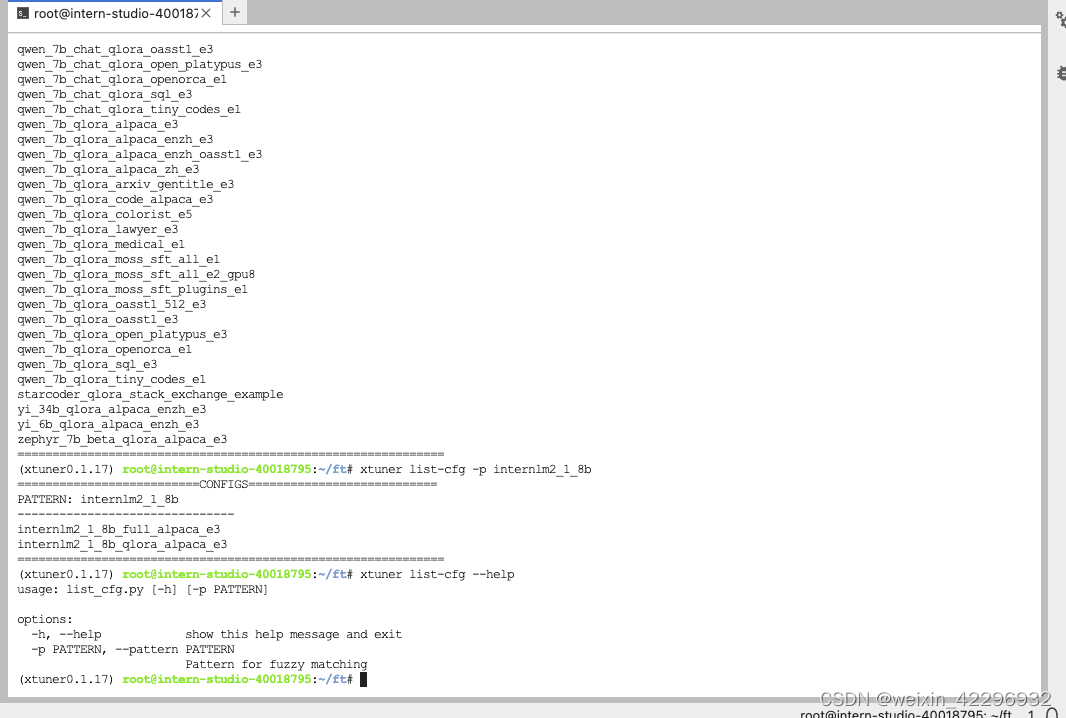
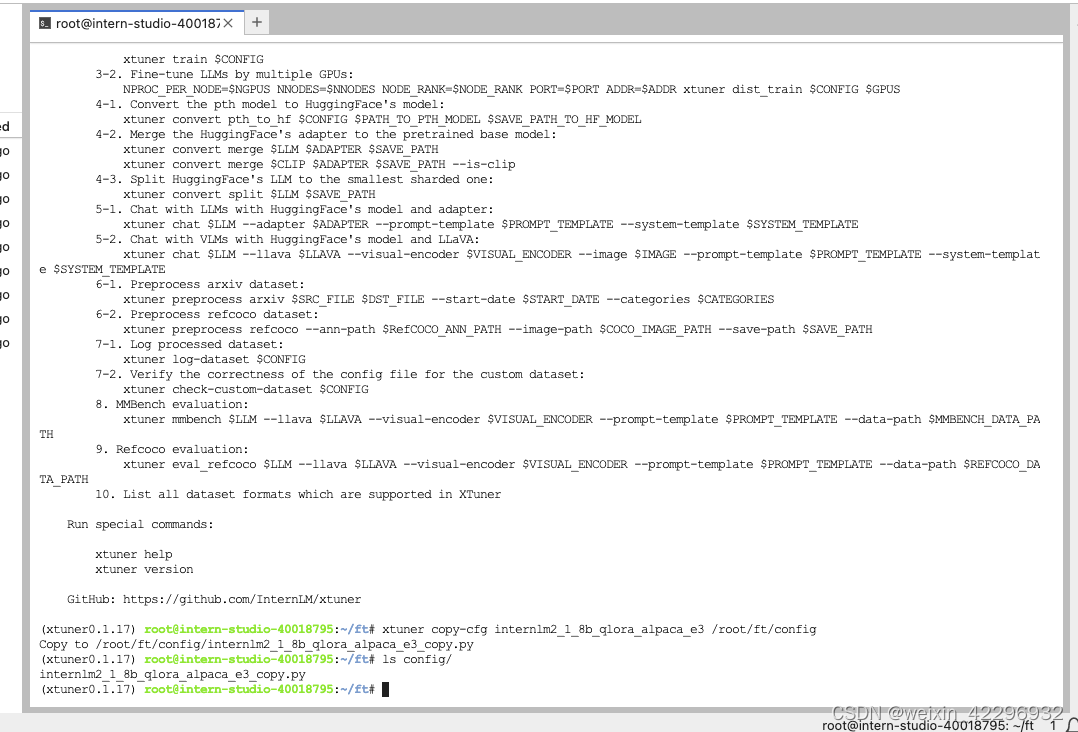
6、修改配置文件
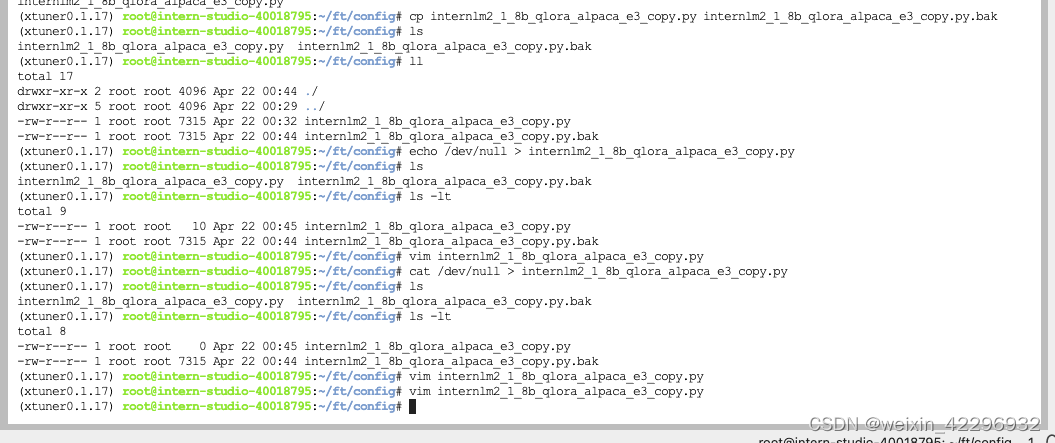
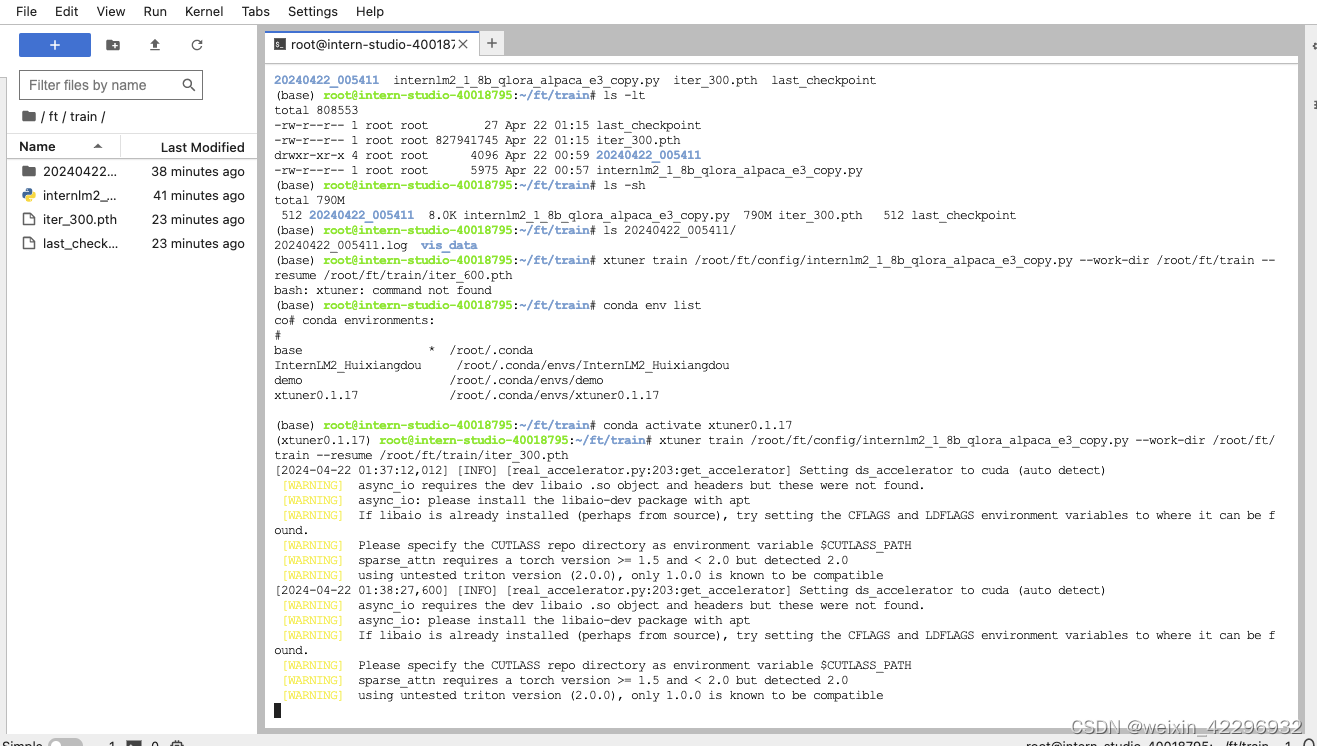
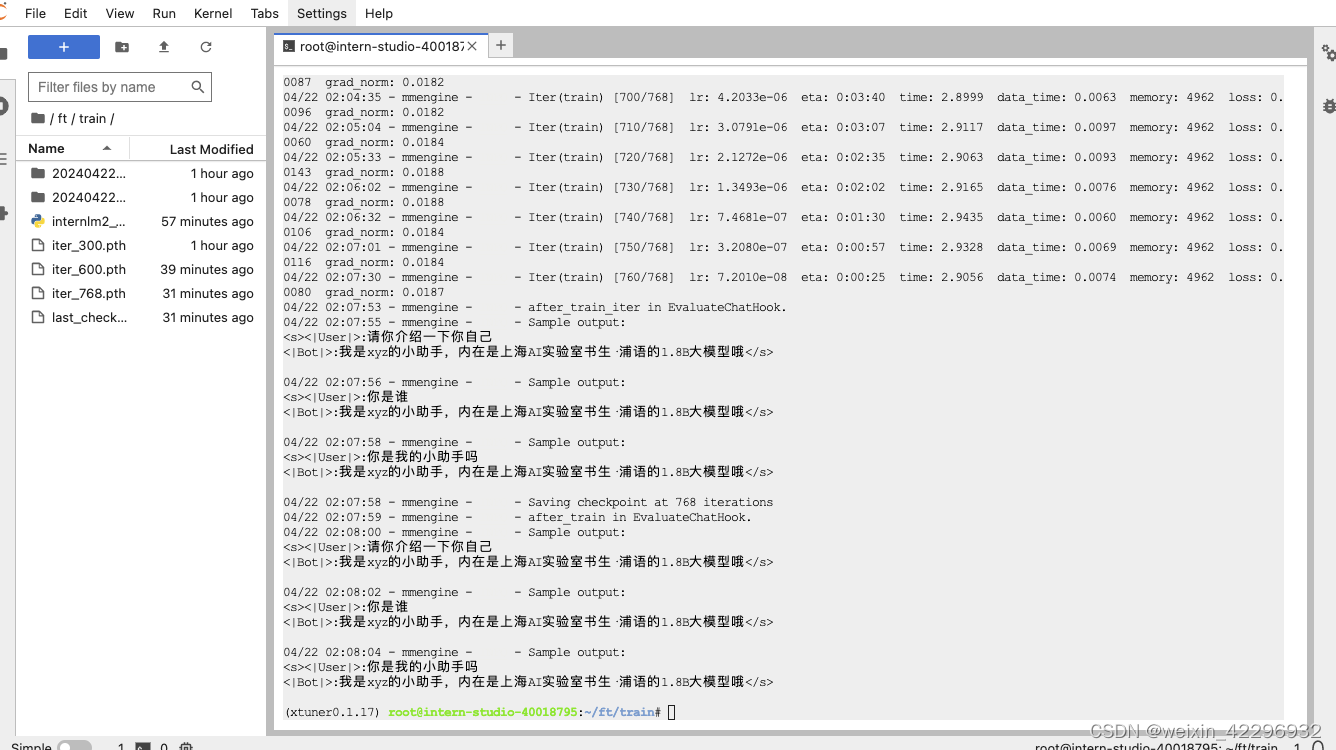
7、模型训练
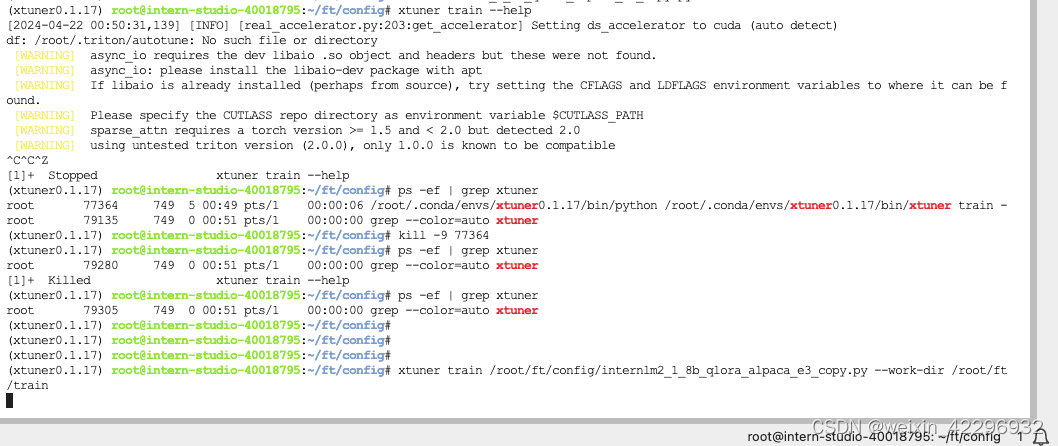
训练过程中断后,选择续训
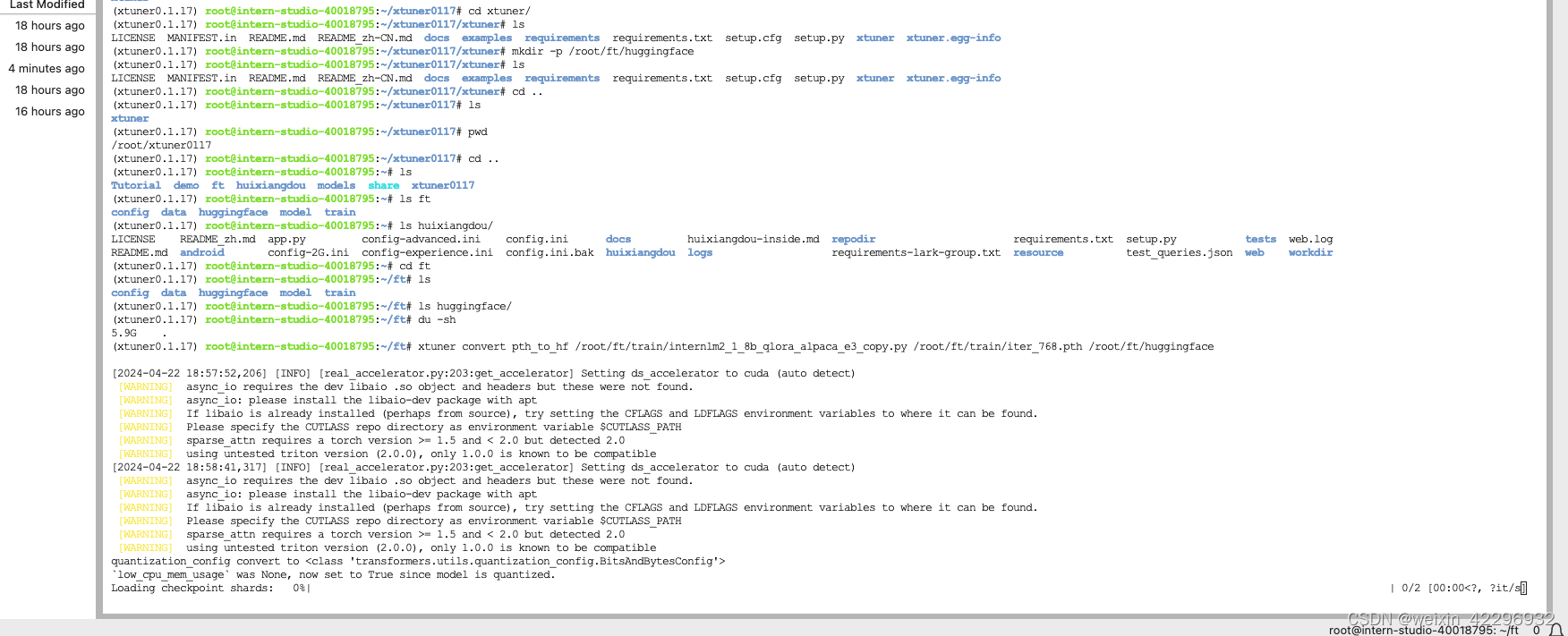
8、模型转换
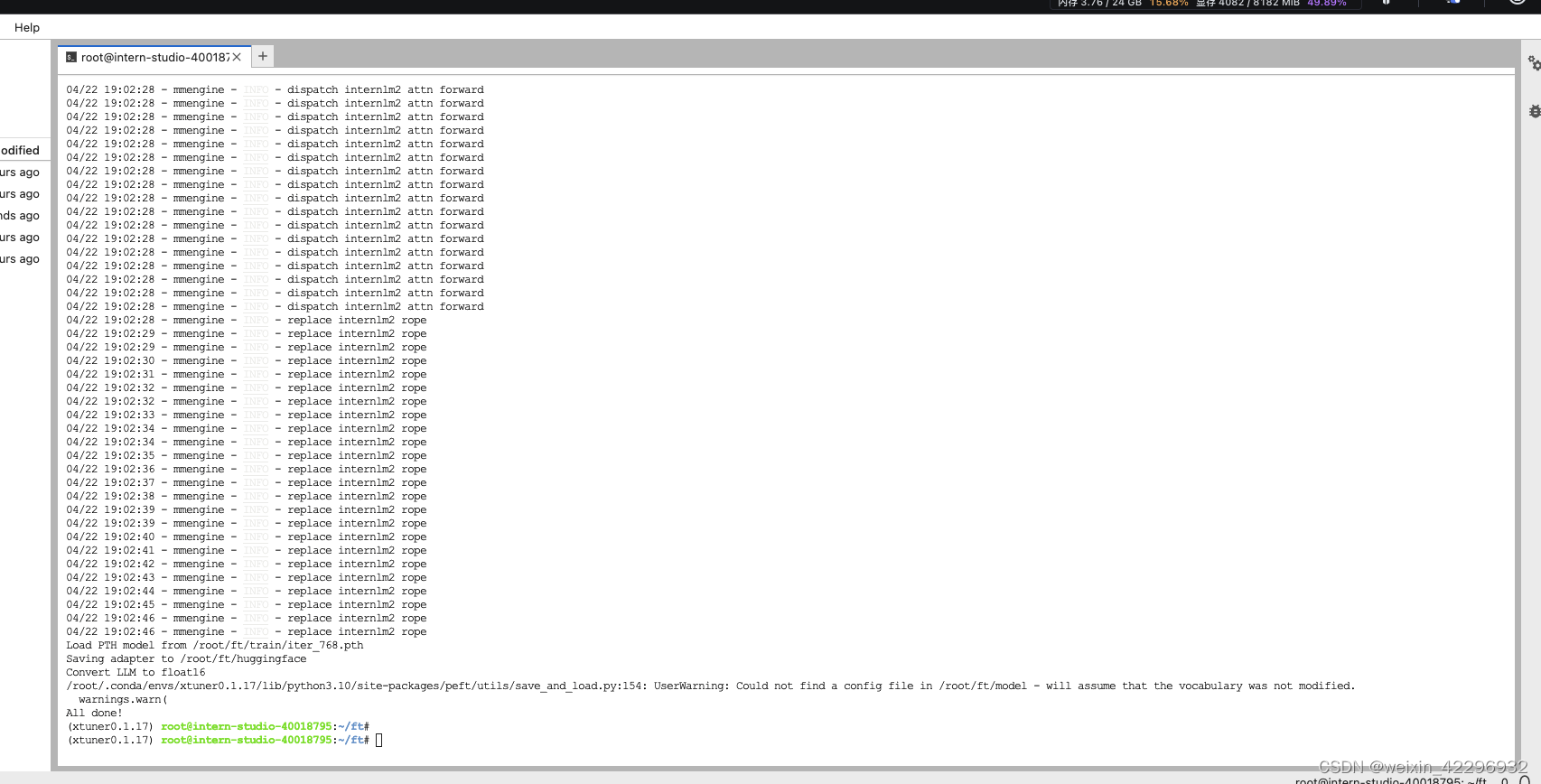
9、模型整合
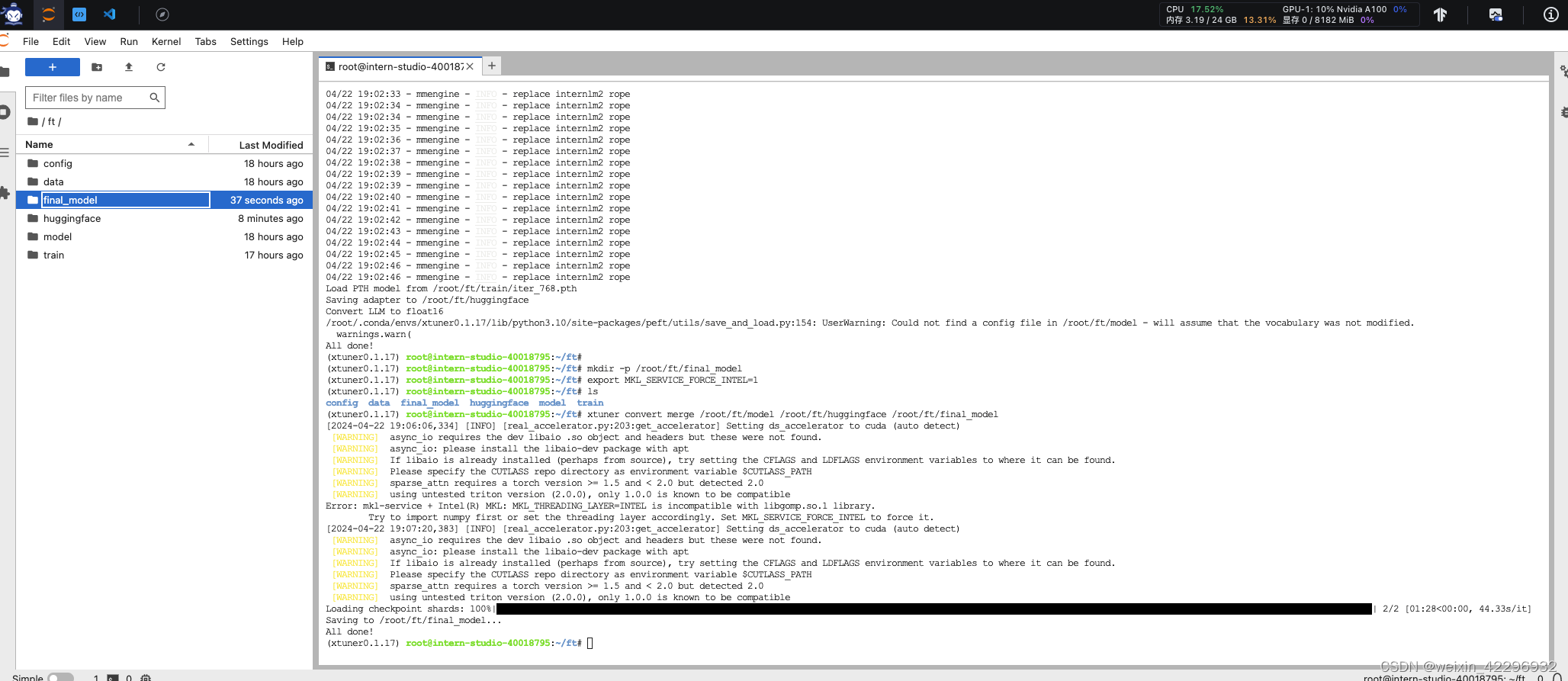
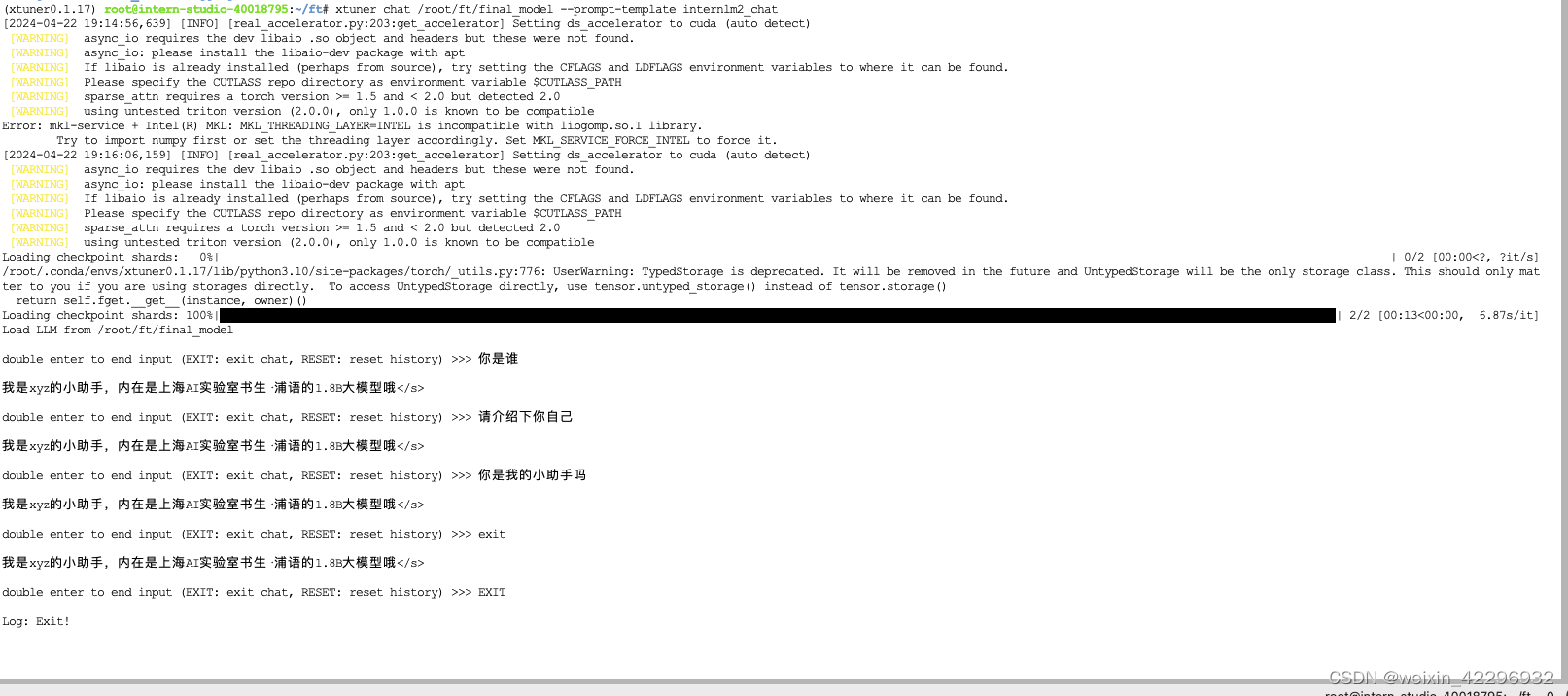
10、对话测试
微调后
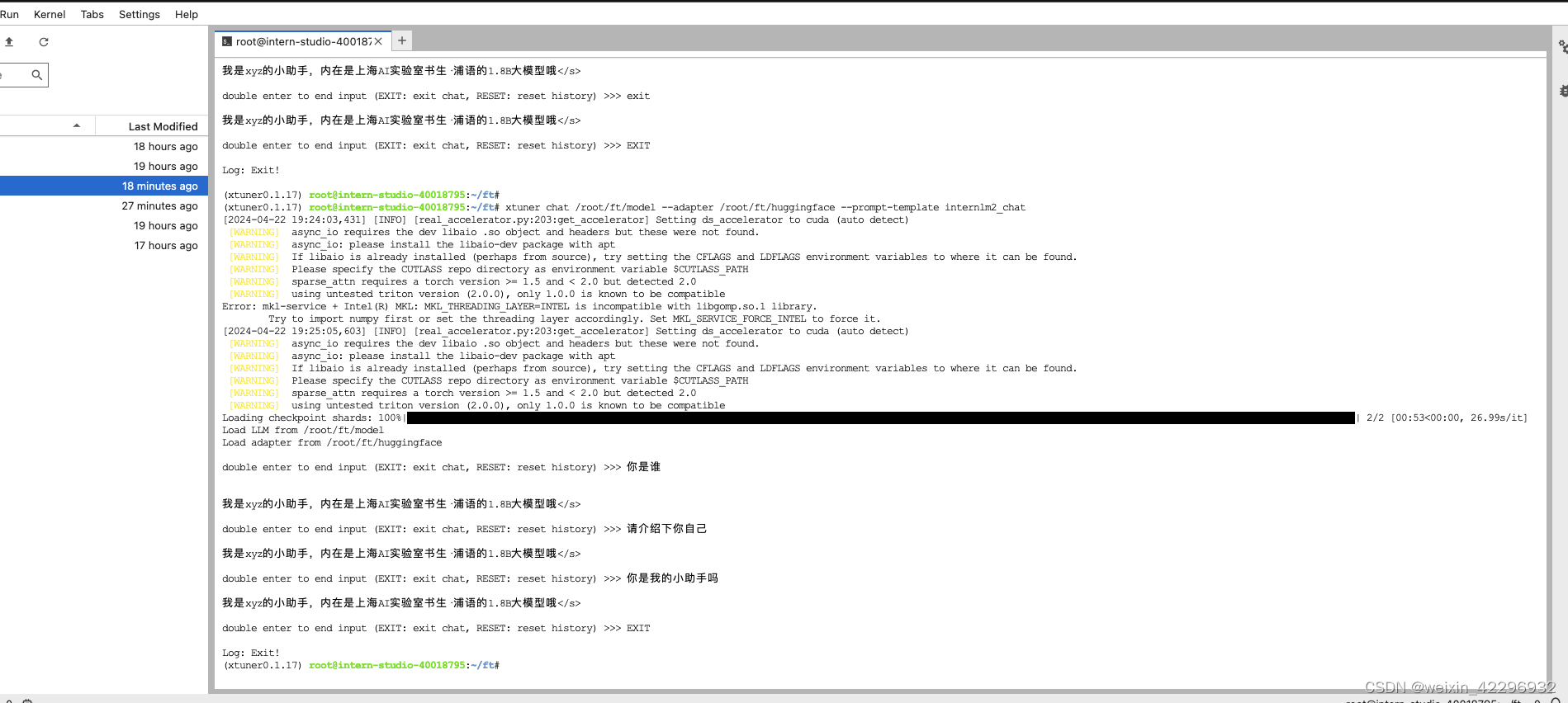
微调前
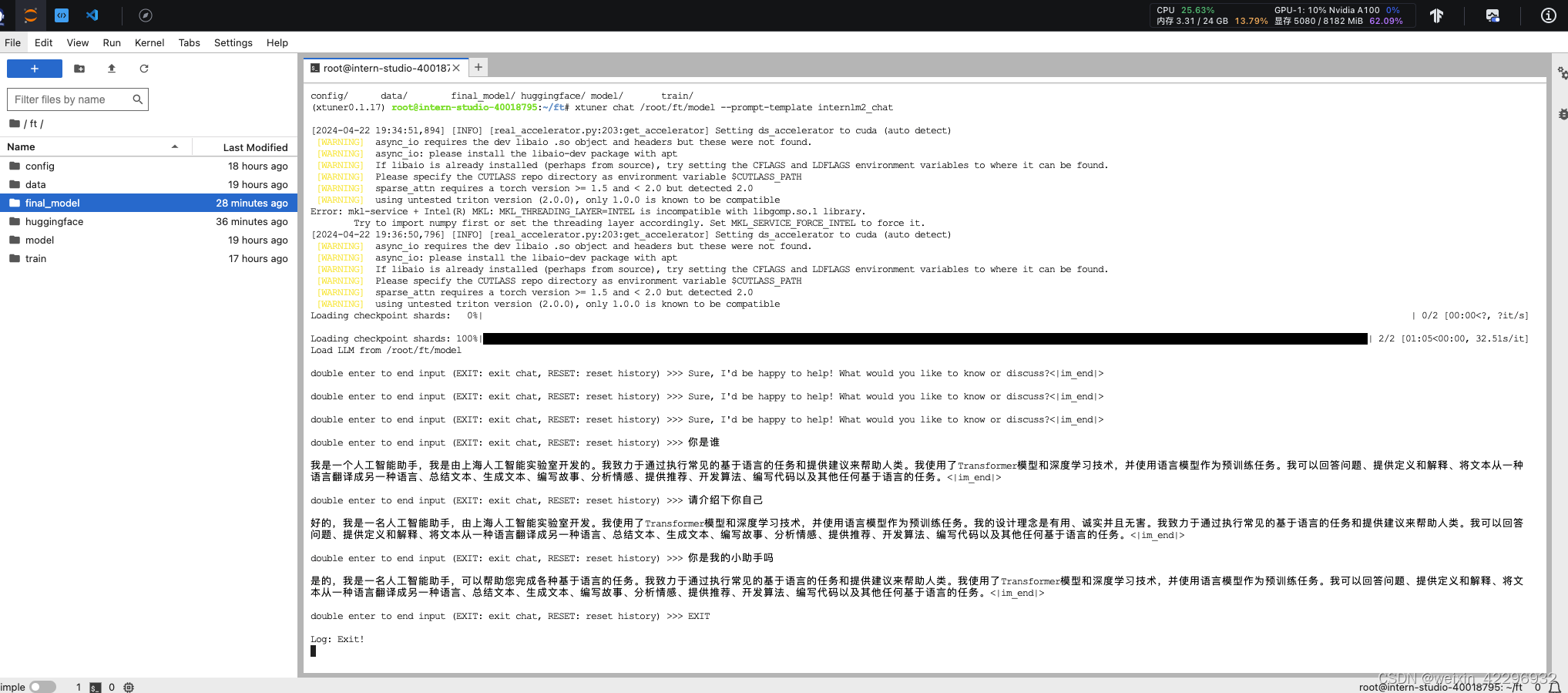
多模态微调:
1、准备30% A100开发机,并且安装XTuner
之前已经安装过,所以直接conda activate
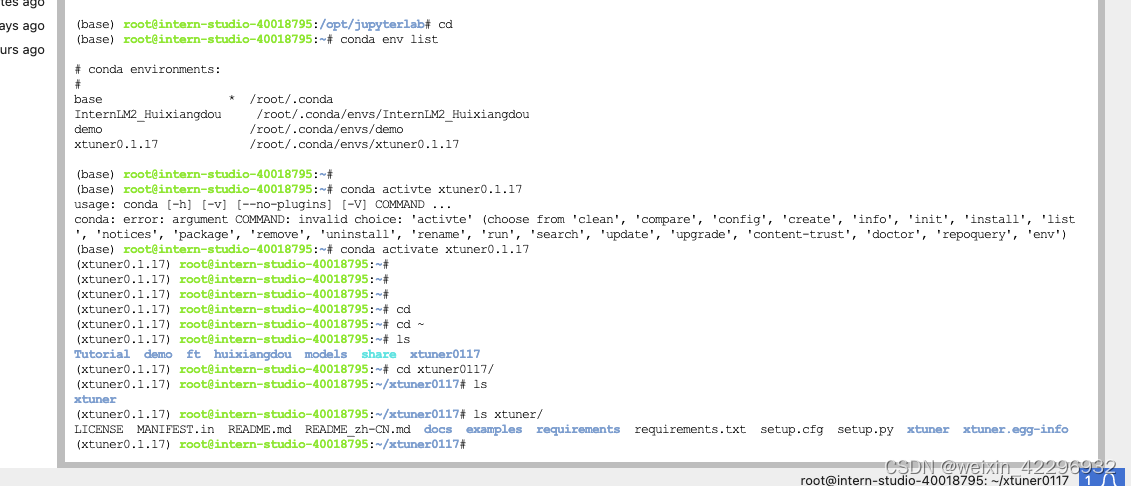
2、构造<question text><image>--<answer text> 数据对
首先构造训练数据
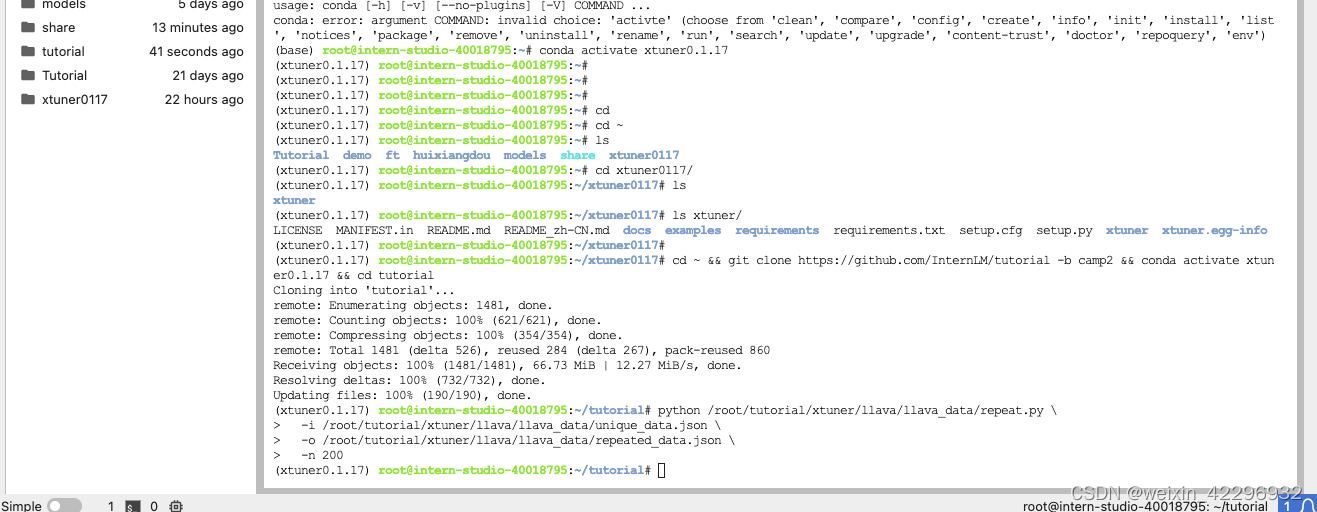
然后准备配置文件

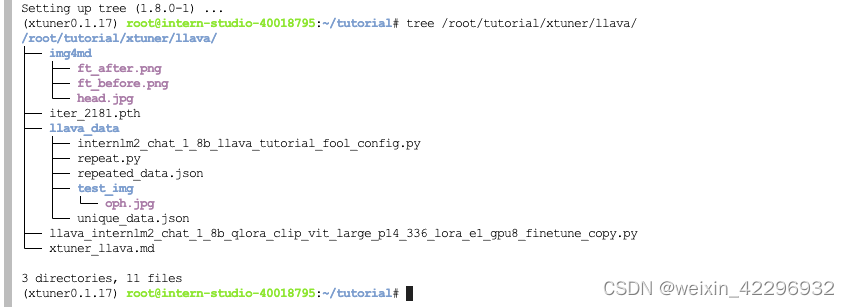
修改配置文件
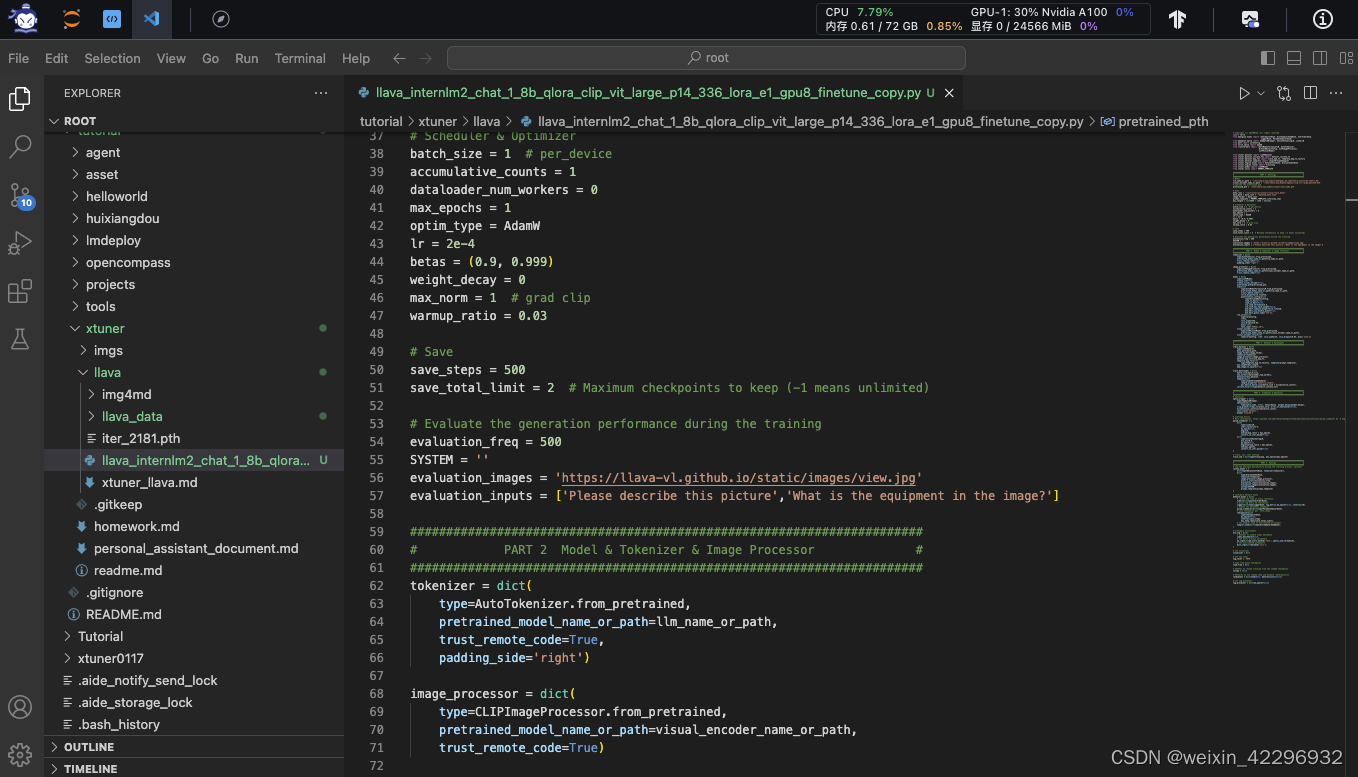
开始FT
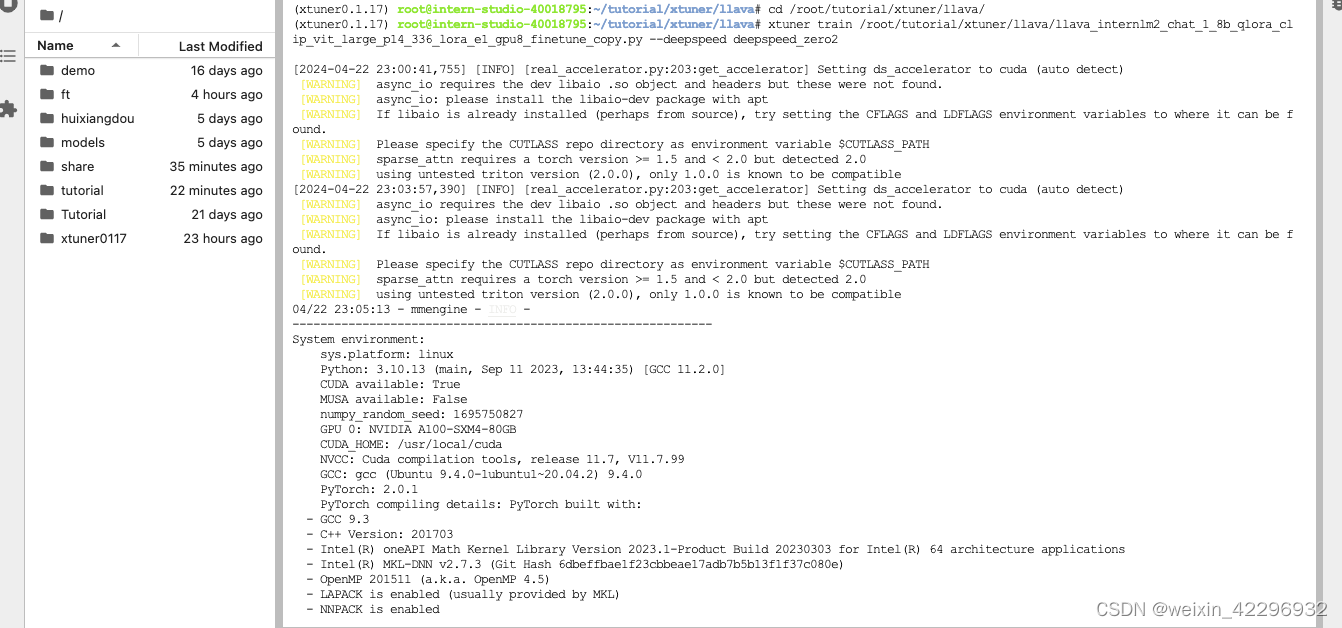
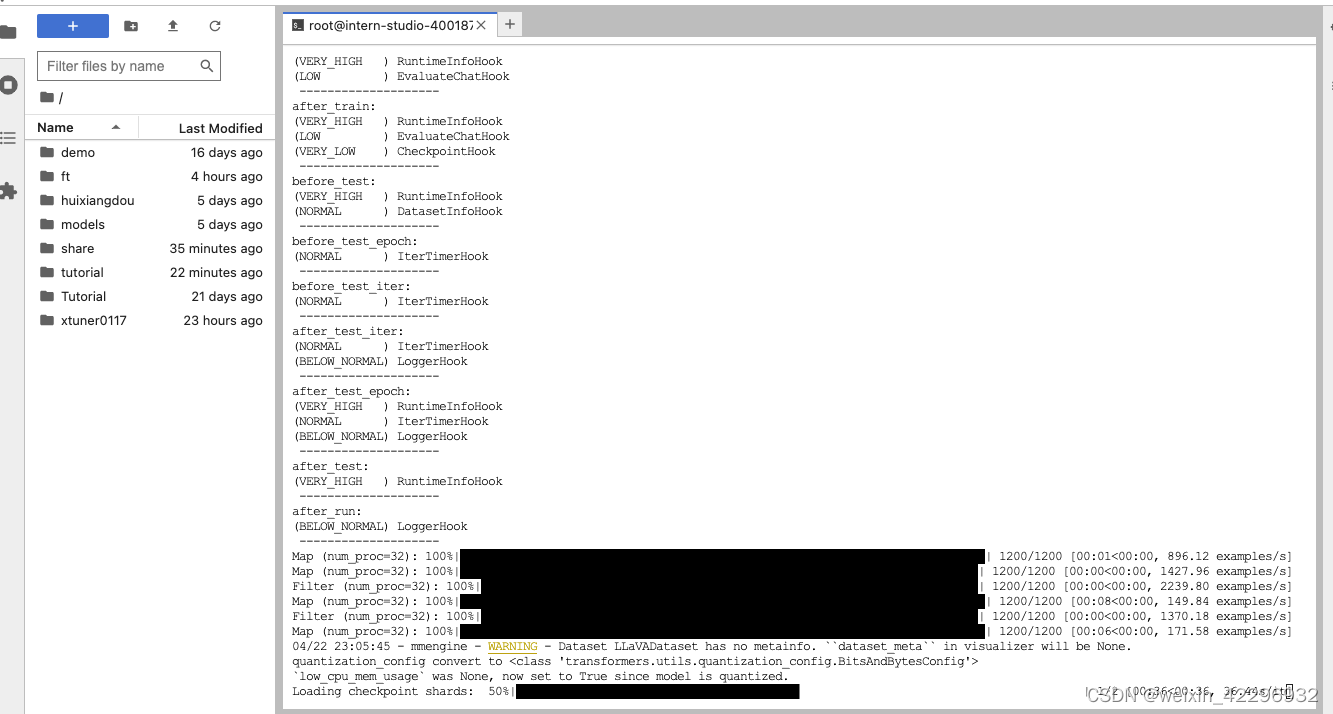
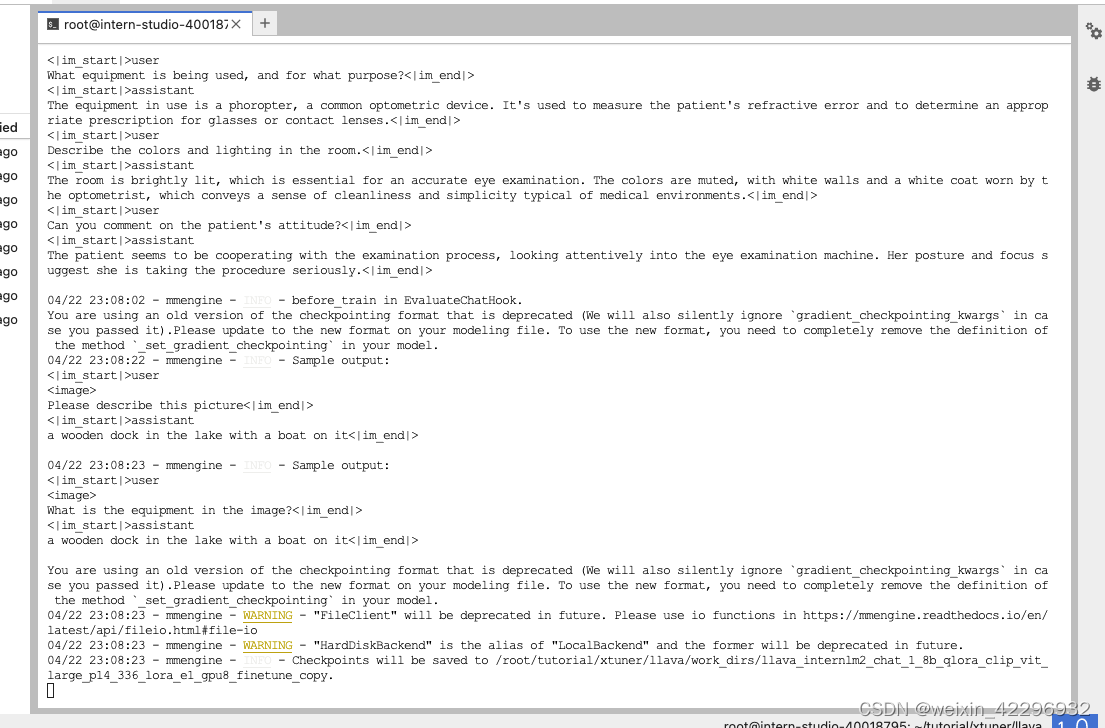
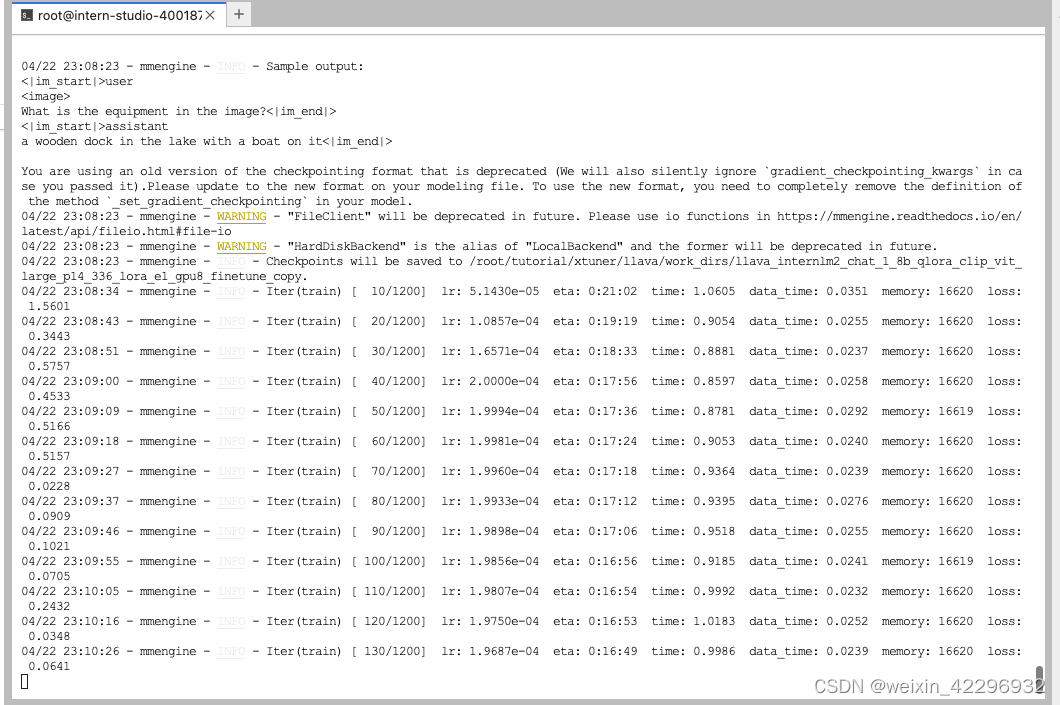
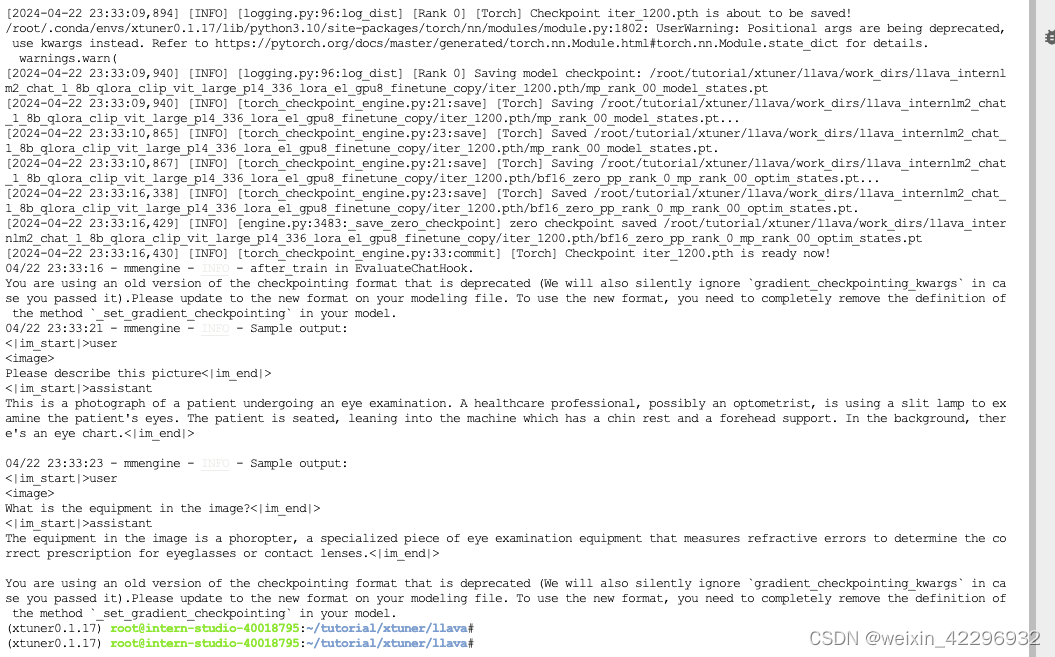
最后对比Finetune前后的性能差异
Finetune前
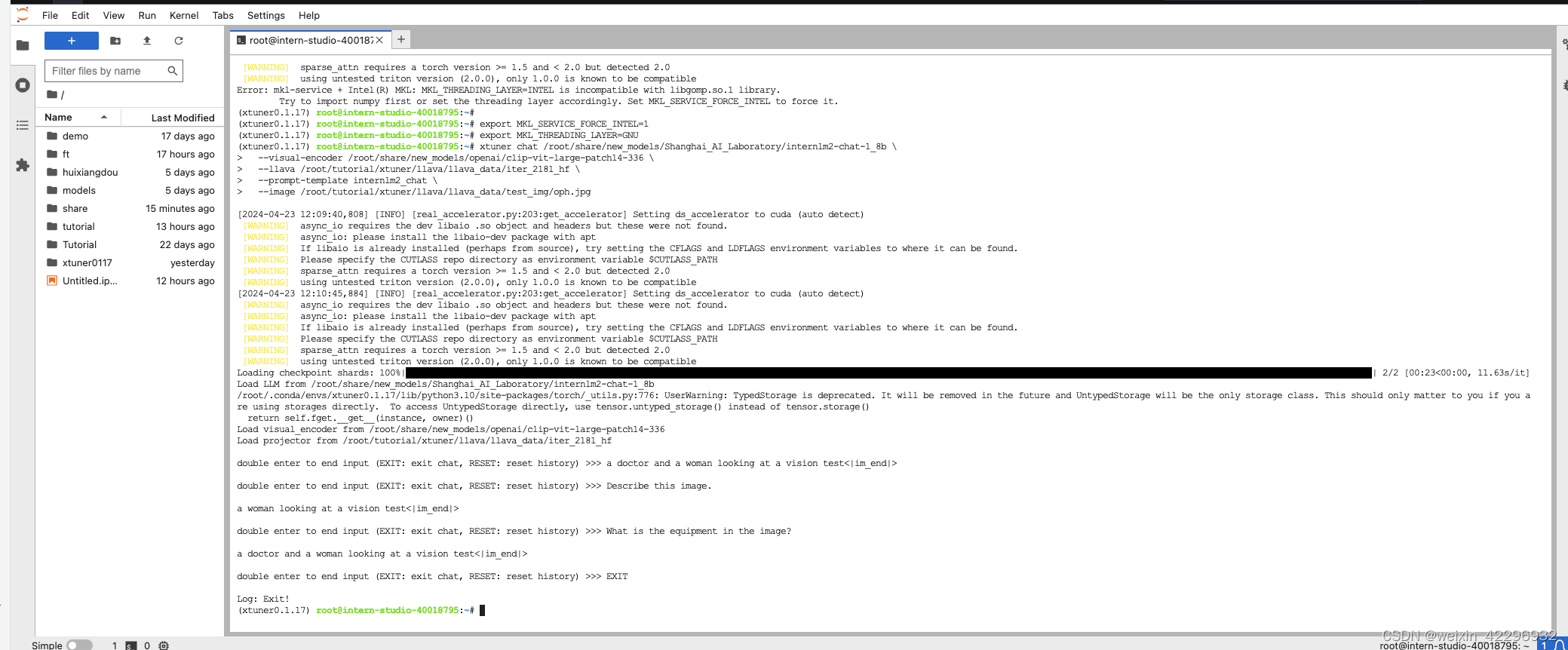
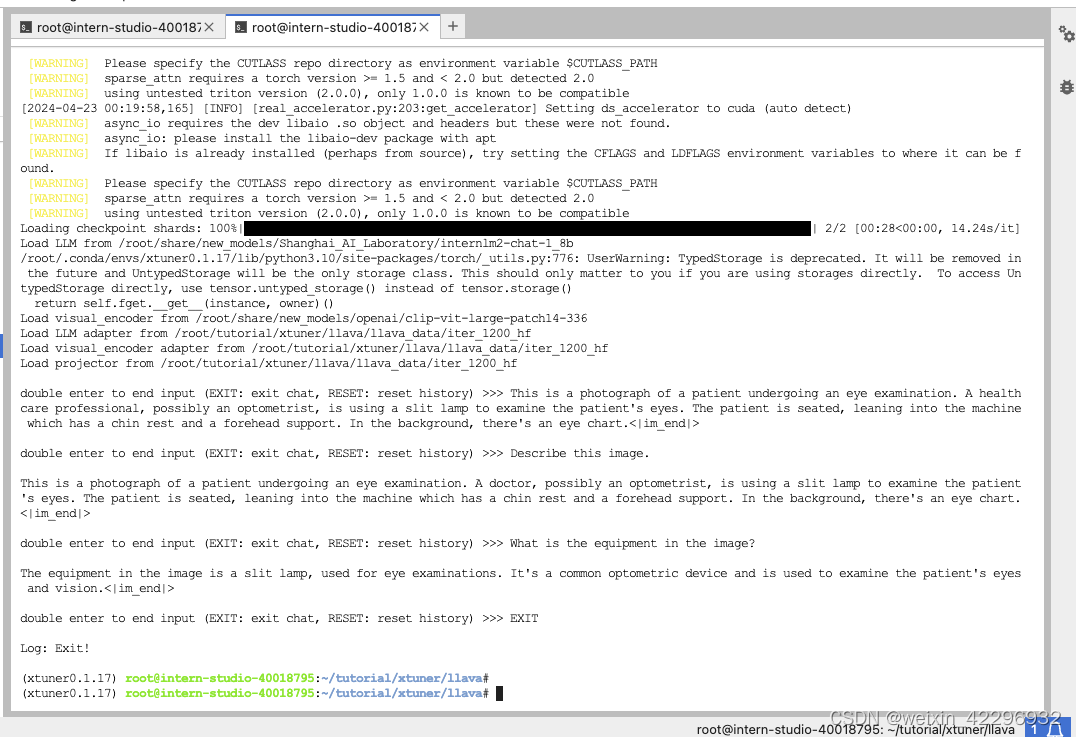
Finetune后



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









