







 本文全面介绍了使用Python进行各种文件格式(包括.txt、.xls、.xlsx、.docx)的读写操作,覆盖基础到进阶技巧,利用标准库及第三方库如xlrd、xlwt、pandas和docx,提升数据处理效率。
本文全面介绍了使用Python进行各种文件格式(包括.txt、.xls、.xlsx、.docx)的读写操作,覆盖基础到进阶技巧,利用标准库及第三方库如xlrd、xlwt、pandas和docx,提升数据处理效率。
基础:.txt文件的读写
- 读文件
filename.txt如下:
张三 男 20
李四 男 25
赵五 女 18
按行读取 readline()
with open('filename.txt', 'r') as f:
while True:
content = f.readline() # 按行读
if content == '':
break
content = content.strip().split()
name = content[0] # 张三 李四 赵五
读取所有 readlines()
with open('filename.txt', 'r', encoding='utf8') as file:
content = file.readlines()
for line in content:
print(line) # 张三 男 20
name = line[0] # 张三
两种读法各有利弊,根据具体情况选用。
- 写文件
with open('filename.txt', 'w', encoding='utf8') as file:
file.writelines('序号'+ '\t' + '姓名' + '\t' + '年龄' + '\n')
file.writelines('1'+ '\t' + '张三' + '\t' + '20' + '\n')
进阶:用xlrd和xlwt对.xls文件进行读写
- xlrd模块
xlrd模块用来读取.xls文件
import xlrd
# 打开一个.xls文件
workbook = xlrd.open_workbook('filename.xls')
# 文件的第一个sheet
sheet = workbook.sheet_by_index(0)
# 文件的总行数
nrows = sheet.nrows
# 按行查询文件内容
for i in range(1, nrows):
row = sheet.row_values(i) # 第i行的所有信息
content = row[0] # 第i行第0列的内容
- xlwt模块
xlwt模块可以将数据写入.xls文件
import xlwt
# 创建一个xls文件
file = xlwt.Workbook(encoding='utf-8')
#新建一个sheet,并且给它命名
table = file.add_sheet('rules')
#在这个sheet下,用write填写,第一个参数是行,第二个是列,第三个是单元格内容
table.write(0, 0, '序号')
table.write(0, 1, '姓名')
table.write(1, 0, '1')
table.write(1, 0, '张三')
# 保存文件
file.save('filaname.xls')
所以上面的例子可以生成:
| 序号 | 姓名 |
|---|---|
| 1 | 张三 |
注意,xlrd可以读取.xls和.xlsx类型的文件。
但是xlwt只能生成.xls类型的文件,不能生成.xlsx类型的文件,会报错。
再进阶:利用pandas进行文件的读取
pandas非常之好用,可以读取txt, csv等各种类型的文件,再加上pandas自带的各种功能,对数据进行统计、分析就变得简单了。
read_table
df = pd.read_table('filename.txt', header=None, names=['name', 'gender', 'age'])
# 统计
print(df.age.value_counts()) # 数一下同一个年龄的有多少人
print(df.groupby(['age']).size()) # 也是统计age列的个数
print(df.groupby(['age', 'gender']).size() # 高级的地方在于可以安排多个列排序
# 相当于先按照age排序,然后age相同的再用gender区分。和excel的高级筛选差不多。
read_csv
df = pd.read_csv('filaname.csv')
如果仅仅是需要读文件中的内容,前两个就够用了。但侧重点在读取数据后,还需要对数据进行修改、删除、统计、归类等等操作,那就非常推荐pandas啦。
再进阶:用docx模块对.doc文件进行读写
我使用的是docx第三方库
- 读取文件
from docx import Document
doc = Document('filename.docx')
for paragraph in doc.paragraphs: # 按段落读取文件内容
print(paragraph.text)
"""
output:
这是文章的第一段。
这是文章的第二段
"""
关于docx文件的读写,有个很重要的概念需要理解一下,就是run。
txt文件可以整篇读取,然后按行迭代读取,最小切分单位为一行(当然还可以用split继续划分,这里就不说了)。
excel文件按照sheet - 行 - 列的顺序迭代,最小切分单位为一个单元格。
对于.docx文件来说,第一步是按照段落,在每一段里继续划分可以分为很多run。这个run可以理解为.docx文件的一次保存,可能是用户自己点击的保存按钮,也可能是文档的自动保存,总之是把用户写在内存里的文字提交,写入磁盘。所以.docx文件的最小切分单位为一run。
所以对于上面的读取文件的代码,还可以继续切分。(当然,切分完的结果很可能不是一个完整的句子)
from docx import Document
doc = Document('filename.docx')
for paragraph in doc.paragraphs: # 按段落读取文件内容
for run in paragraph.runs: # 按run读取
print(run.text)
"""
output:
这是文章的
第一段。
这是
文章的第二
段
"""
# 这代表第一段里有两个run,第二段里有三个run。
文档的简单读取,按段落读取就足够了。按run读取用于更高级的识别,比如对于文档格式(颜色、高亮、字体等)的读写等。
- 写入文件
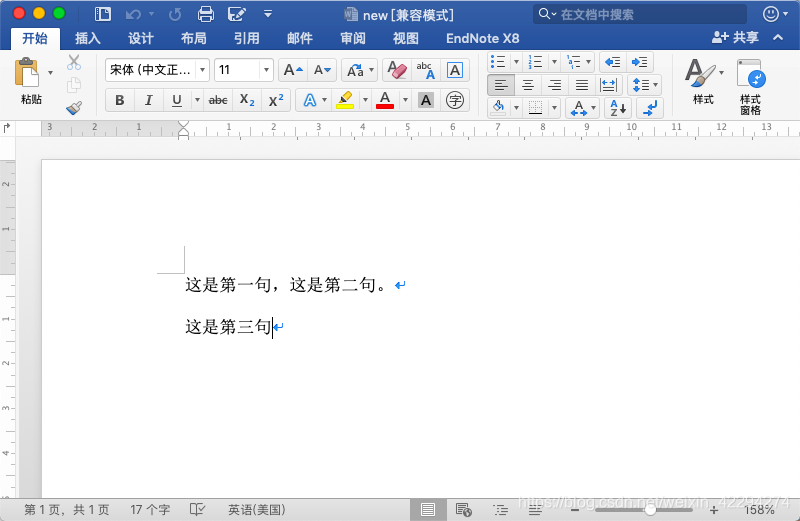
from docx import Document
doc = Document()
para1 = doc.add_paragraph() # 添加段落
para1.add_run('这是第一句,') # 在添加的时候,文字也是按run添加的。
para1.add_run('这是第二句。')
para2 = doc.add_paragraph() # 添加第二段
para2.add_run('这是第三句')
doc.save('new.docx')
生成的文档截图如下。
- 文字高亮
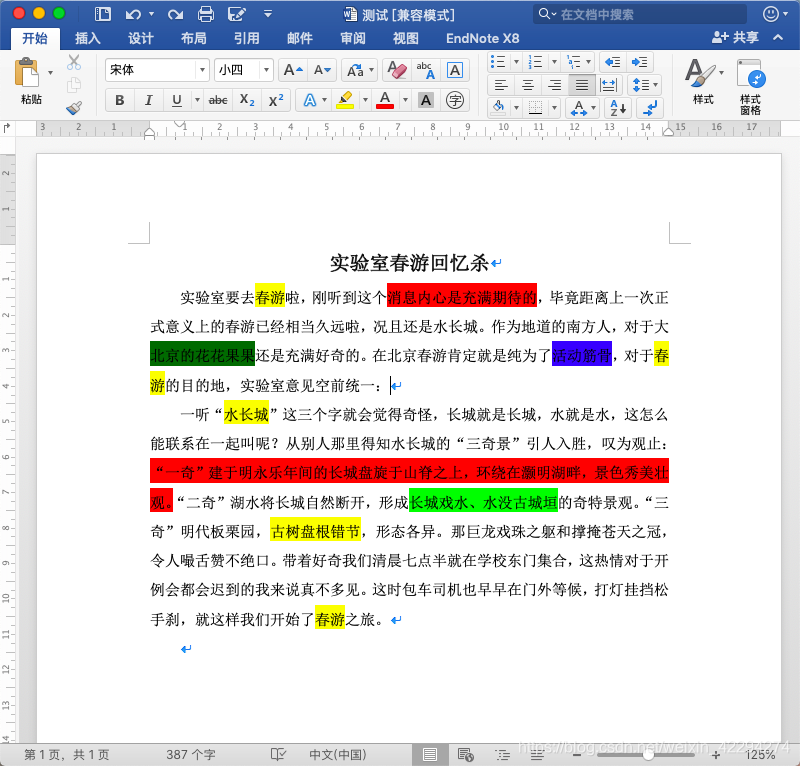
高亮大家在word中肯定都用过,可以标记或者突出部分文字。这个用python可以实现自动高亮啦。效果就像下图这样:
未完待续……

















 2083
2083

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









