






| pred\label | Positive | Negative |
|---|---|---|
| Positive | tp(预测正确,预测结果是正阳本,实际是正样本) | fp(预测错误,预测结果是正样本) |
| Negative | fn(预测错误,预测结果为负样本,世纪为正样本) | tn(预测正确,预测结果是负样本) |
- 精确度(Precision):预测为正且实际为正的样本占所有预测为正的样本的比例,计算公式为
p r e c i s i o n = T P / ( T P + F P ) precision=TP/(TP+FP) precision=TP/(TP+FP)
精确度还有一个名字,叫做**“查准率”,我们关心的主要部分是正例,所以查准率就是相对正例的预测结果而言,正例预测的准确度。直白的意思就是模型预测为正例的样本中,其中真正的正例占预测为正例样本的比例,用此标准来评估预测正例的准确度**。 理解:精确度越高,误检率越低。 数学意义:Precision体现了模型对负样本的区分能力,Precision越高,模型对负样本的区分能力越强;
2.召回率(Recall):实际为正且被正确预测为正的样本占所有实际为正的样本的比例,计算公式为
r
e
c
a
l
l
=
T
P
/
(
T
P
+
F
N
)
recall=TP/(TP+FN)
recall=TP/(TP+FN)
召回率的另一个名字,叫做**“查全率”**,理解:所有正例的样本被检测为正例的比例。 更具体地说,召回率R是检索出的相关文档数D1和文档库中所有的相关文档数D2的比率,可以用以下公式表示:R = D1/D2。 数学意义:Recall体现了模型对正样本的识别能力,Recall越高,模型对正样本的识别能力越强
-
F1 精确值与召回率的调和平均值,两者的综合,F1 score越高,说明模型越稳健。
F1-Score又称为平衡F分数(balanced F Score),他被定义为精准率和召回率的调和平均数。
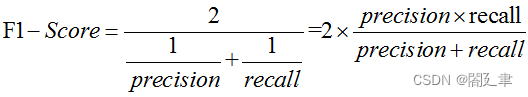
F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差。
更一般的,我们定义Fβ分数为
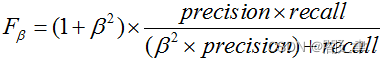
除了F1分数之外,F2分数和F0.5分数在统计学中也得到大量的应用。其中,F2分数中,召回率的权重高于精准率,而F0.5分数中,精准率的权重高于召回率。参考:
《Thresholding Classifiers to Maximize F1 Score》
《Beyond Accuracy, F-score and ROC: a Family of Discriminant Measures for Performance Evaluation》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









