




 本文详细介绍如何在VMware环境下,使用CentOS7操作系统搭建Hadoop2.6.1集群,包括静态网络环境配置、Java环境安装、Hadoop包安装与配置、SSH免密登录设置等关键步骤。
本文详细介绍如何在VMware环境下,使用CentOS7操作系统搭建Hadoop2.6.1集群,包括静态网络环境配置、Java环境安装、Hadoop包安装与配置、SSH免密登录设置等关键步骤。
参考文章【侵删】:https://www.cnblogs.com/yjmyzz/p/4280069.html
https://www.cnblogs.com/vincentzh/p/6034187.html#t5
环境:vmware14pro+centos7
hadoop 2.6.1 +jdk1.8.0_91
step1 搭建静态网络环境+建立互信关系
现在3台虚拟机采用的是NAT模式。全部改成静态地址。
1.设置静态IP
/etc/sysconfig/network-scripts/ifcfg-eth0 //是网络设备的配置文件。
设置成静态ip
BOOTPROTO=static
IPADDR=192.168.183.10
NETMASK=255.255.255.0
GATEWAY=192.168.183.2
DNS1=202.106.0.20保存退出后重启网络服务
/etc/init.d/network restart
master 192.168.183.10 、slave1 192.168.183.11 、 slave2 192.168.183.12
2.设置hostname
vim /etc/sysconfig/network
# Created by anaconda
NETWORKING=yes
HOSTNAME=slave13.设置hosts
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.183.10 master
192.168.183.11 slave1
192.168.183.12 slave24.关闭防火墙
centos7以上使用的是firewall 防火墙
iptables -F
service iptables sa
service iptables save
systemctl iptables save
systemctl stop firewalld
systemctl disable firewalld5.测试使用主机名互ping能否ping通
6.生成秘钥对
ssh-keygen -t rsa
#三次回车
[root@slave2 ~]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
Created directory '/root/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:rFQOMu+83UQMsudq4f03yFHYkWyq6tyg1mlHqIyLioE root@slave2
The key's randomart image is:
+---[RSA 2048]----+
| . . |
| = |
| o o o = . |
| + B oo o |
| +.S.o. |
|. +o+o.. |
|E o +=*...o |
|.o. +oB*ooo o |
|= .o.+=.o.o. . |
+----[SHA256]-----+7.复制秘钥文件(相互追加key)
[root@master ~]# ls /root/.ssh
id_rsa id_rsa.pub以上id_rsa.pub就是公钥
将三台主机的公钥内容复制到新文件 authorized_keys 中
[root@master ~]# cat /root/.ssh/id_rsa.pub > /root/.ssh/authorized_keys修改 三台主机的authorized_keys 文件权限(便于访问操作)
[root@slave2 ~]# chmod 600 /root/.ssh/authorized_keys相互追加authorized_keys文件
step2 安装配置java环境
1.卸载原来的java
使用命令 which java 获得现在版本的java目录
使用rm -rf 把整个目录删掉
检查~/.bashrc里面有没有java相关的环境变量,有就删了
检查 /etc/profile里面有没有java相关的环境变量,有就删了
2.下载安装包
使用uname -a查看自己linux系统是64位还是32位的(X86就是32位,X86_64就是64位的)
下载地址:
http://www.oracle.com/technetwork/java/javase/downloads/index.html
下载完成后,将tar.gz安装包拷贝到/usr/local/src
使用命令 tar -zxvf 解压安装
3.修改环境变量
vim ~/.bashrc
JAVA_HOME=/usr/local/src/jdk1.8.0_191
JAVA_BIN=$JAVA_HOME/bin
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/jre/lib/charsets.jar
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
刷新环境变量 source ~/.bashrc
确认:输入java 出现java用法提示。使用echo $JAVA_HOME 查看环境变量中java的根目录
step3 安装hadoop包
使用的是2.6.1安装包
tar -zxvf把安装包解压安装
在hadoop安装目录下mkdir tmp 建立缓存文件夹。
hadoop2的配置文件都在/usr/local/src/hadoop-2.6.1/etc/hadoop 下。
1.建立masters文件
hadoop2上面只有slaves文件,没有masters文件,因此需要建立一个masters文件。写入有哪些master。
因为已经修改了hosts文件,所以只需要输入master的hostname就行了。现在环境中只有一个master
mster2.编辑slaves文件
同样,输入slave列表
slave1
slave23.编辑core-site.xml文件
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/tmp</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.183.10:9000</value>
</property>
</configuration>
解释:
第一个:定义tmp目录。有的教程上有file: 有的教程上没有
第二个:定义hdfs端口 有人说用master可能会不成功,所以写静态IP
core-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/core-default.xml
4.编辑hdfs-site.xml文件
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.183.10:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/src/hadoop-2.6.1/dfs/data</value>
</property>
</configuration>留了个心眼儿,查看了根目录下是否有/dfs/name 和/dfs/data两个文件夹,果然没有,所以mkdir建立了一下。
hdfs-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
5.编辑yarn-site.xml文件
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>Master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>yarn-site.xml的完整参数请参考
http://hadoop.apache.org/docs/r2.6.0/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
6.建立mapred-site.xml文件
hadoop2本身没有mapred-site.xml文件
需要 cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Master:19888</value>
</property>
</configuration>mapred-site.xml的完整参数请参考
7.修改env?
https://www.cnblogs.com/yjmyzz/p/4280069.html这篇文章上说要修改hadoop-env.sh 、yarn-env.sh这两个文件中的JAVA_HOME指向,但是我进去看代码,已经指定了${JAVA_HOME},因此认为没有必要改。
结果配置完成运行hadoop显示报错
Error: JAVA_HOME is not set and could not be found.
因此先修改hadoop_env.sh,另一个暂时不改
hadoop命令运行正常
在报错的边缘试探。
8.修改环境变量
vim ~/.bashrc
JAVA_HOME=/usr/local/src/jdk1.8.0_191
JAVA_BIN=$JAVA_HOME/bin
JRE_HOME=$JAVA_HOME/jre
CLASS_PATH=$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_HOME/jre/lib/charsets.jar
HADOOP_HOME=/usr/local/src/hadoop-2.6.1
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export PATH=$PATH:$HADOOP_HOME/bin增加了HADOOP_HOME=usr/local/src/hadoop-2.6.1
export PATH=$PATH:$HADOOP_HOME/bin
这两行
然后source ~/.bashrc刷新一下
step3 配置slave2和slave3
1.把java根目录、hadoop根目录整个一起复制给slave1和slave2
hadoop:
scp -r /usr/local/src/hadoop-2.6.1/ root@slave1:/usr/local/src/hadoop-2.6.1
scp -r /usr/local/src/hadoop-2.6.1/ root@slave2:/usr/local/src/hadoop-2.6.1java : 略
2.根据master修改slave1和slave2的~/bash.rc文件
引申阅读:部分教程中,通过/etc/profile文件来配置环境变量,配置环境变量一共有3种方法。控制台、用户模式、全局模式
/etc/profile是全局模式,而且所有用户都有权限修改这里的控制变量
~/.bashrc是用户模式,仅对当前用户有效。
$ PATH="$PATH:/my_new_path" 是临时模式,仅对当前控制台有效,关闭控制台后失效。
https://www.cnblogs.com/jpfss/p/6560703.html
step4 启动集群
1.初始化namenode
hadoop namenode -format
2.启动进程
进入hadoop根目录下的./etc/hadoop/下,运行 ./start-all.sh
3.查看进程
使用jps查看3台设备的进程
master
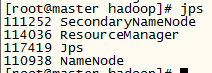 、
、
slave
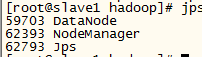
说明:hadoop2之后是没有jobtracker进程的。
参看文章:https://blog.youkuaiyun.com/ASN_forever/article/details/81062238
4.试运行命令
[root@master hadoop]# hadoop fs -ls /
18/11/29 14:43:09 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
出现报错。
这个报错是因为Apache提供的hadoop本地库是32位的,而在64位的服务器上就会有问题,因此需要自己编译64位的版本。可以暂时忽略。
[root@master sbin]# hadoop fs -put /etc/passwd /
18/12/03 11:11:28 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
[root@master sbin]# hadoop fs -ls /
18/12/03 11:11:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 1 items
-rw-r--r-- 2 root supergroup 2237 2018-12-03 11:11 /passwd
确定命令可以正常运行
5.解决native-hadoop library报错
参考网址:
https://www.jianshu.com/p/f25a0caafcc6
在~/.bashrc下加一行
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_COMMON_LIB_NATIVE_DIR"
[root@master native]# hadoop fs -ls /
Found 1 items
-rw-r--r-- 2 root supergroup 2237 2018-12-03 11:11 /passwd
·

















 16万+
16万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









