






一、langchain介绍
LangChian 可以将 LLM 模型、向量数据库、交互层 Prompt、外部知识、外部工具整合到一起,进而可以自由构建 LLM 应用。
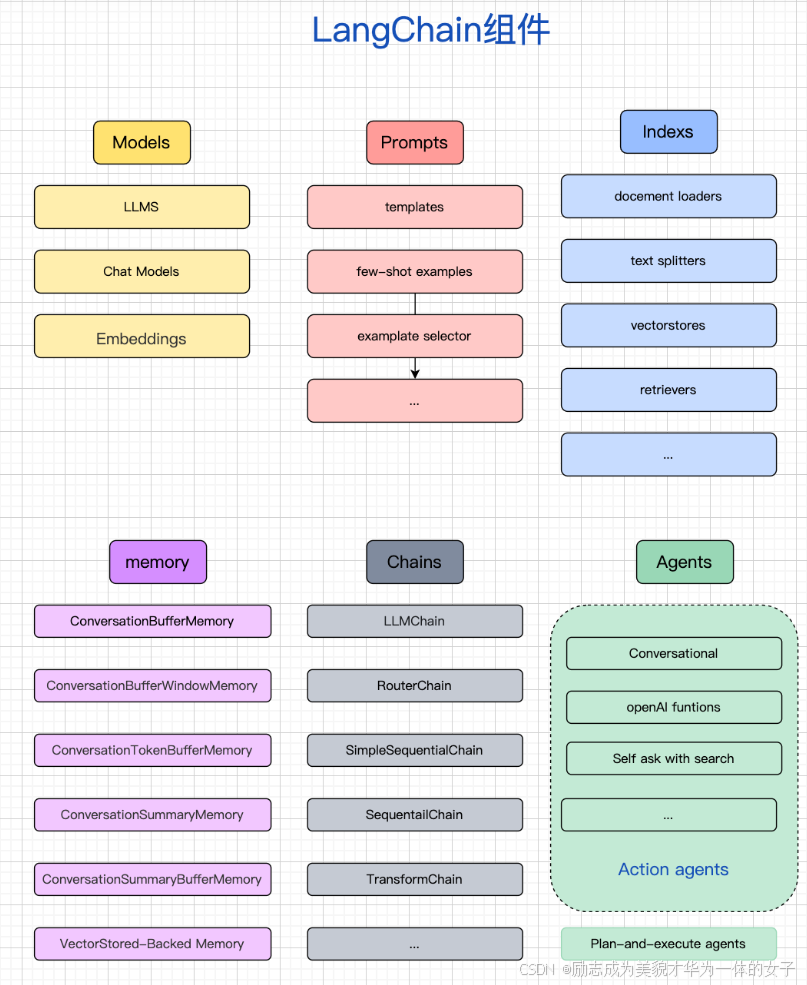
二、langchain模块分析
1. Models
三种类型的模型:Chat Modals, Embeddings, LLMs。
聊天模型的接口是基于消息而不是原始文本。LangChain 目前支持的消息类型有 AIMessage(ai生成的)、HumanMessage(人给出的)、SystemMessage(系统的)和 ChatMessage(ChatMessage 接受一个任意的角色参数)。大多数情况下,只需要处理 HumanMessage、AIMessage 和 SystemMessage。
from langchain.chat_models import ChatOpenAI
# 调用了langchain的一个现成的包
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI(temperature=0)
chat([HumanMessage(content="Translate this sentence from English to French. I love programming.")])2. Prompts(提示词)
提示词模板:

3.Indexs(索引)
加载、转换、存储和查询数据:Document loaders、Document transformers、Text embedding models、Vector stores 以及 Retrievers。

Document loaders(文档加载)旨在从源中加载数据构建 Document。
Document transformers(文档转换)旨在处理文档拆分、合并、过滤等。
Text embedding model(s 文本嵌入模型)旨在将非结构化文本转换为嵌入表示。
Vector Stores(向量存储)是存储和检索非结构化数据的主要方式之一。它首先将数据转化为 嵌入表示,然后存储这些生成的嵌入向量。在查询阶段,系统会利用这些嵌入向量来检索与查询内 容“最相似”的文档。向量存储的主要任务是保存这些嵌入数据并执行基于向量的搜索。
Retrievers(检索器)是一个接口,其功能是基于非结构化查询返回相应的文档。
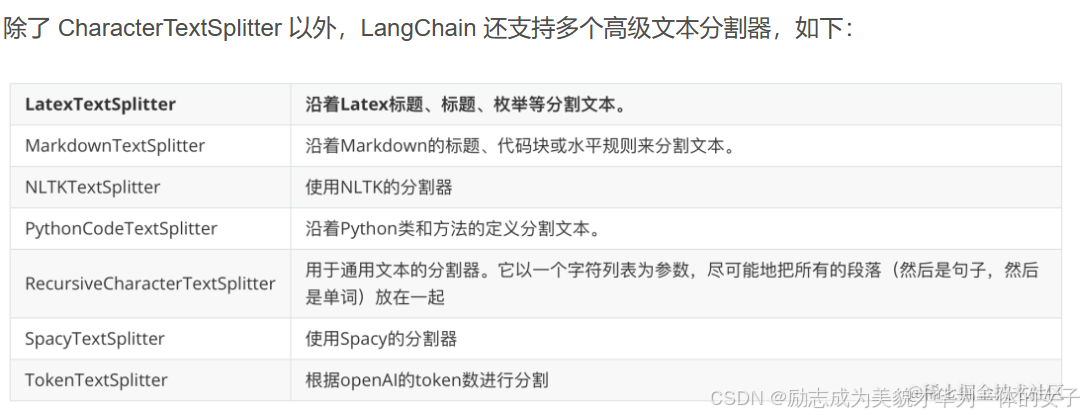
Text Splitters(文本拆分器)
VectorStores(向量存储器):

4.Chains(链)
链允许我们将多个组件组合在一起以创建一个单一的、连贯的任务。
from langchain import PromptTemplate, OpenAI, LLMChain
prompt_template = "What is a good name for a company that makes {product}?"
llm = OpenAI(temperature=0)
llm_chain = LLMChain(
llm=llm,
prompt=PromptTemplate.from_template(prompt_template)
)
llm_chain("colorful socks")
可运行对象Runnble


chain.stream/invoke/ainvoke等方法
内置方法

前一个可运行对象的 .invoke() 调用的输出将作为输入传递给下一个可运行对象。这可以使用管道运算符 (|) 或更明确的 .pipe() 方法来完成,它们的作用相同。
生成的 RunnableSequence 本身就是一个可运行对象,这意味着它可以像其他任何可运行对象一样被调用、流式传输或进一步链接。以这种方式链接可运行对象的优点是高效的流式传输(序列将在输出可用时立即流式传输输出),以及使用 LangSmith 等工具进行调试和跟踪。
import getpass
import os
os.environ["OPENAI_API_KEY"] = getpass.getpass()
from langchain_openai import ChatOpenAI
model = ChatOpenAI(model="gpt-4o-mini")
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
prompt = ChatPromptTemplate.from_template("tell me a joke about {topic}")
chain = prompt | model | StrOutputParser()
chain.invoke({"topic": "bears"})假设我们想要将笑话生成链与另一个评估生成的笑话是否好笑的链组合在一起。
from langchain_core.output_parsers import StrOutputParser
analysis_prompt = ChatPromptTemplate.from_template("is this a funny joke? {joke}")
composed_chain = {"joke": chain} | analysis_prompt | model | StrOutputParser()
composed_chain.invoke({"topic": "bears"})以下这个方法效果相同:
composed_chain_with_lambda = (
chain
| (lambda input: {"joke": input})
| analysis_prompt
| model
| StrOutputParser()
)
composed_chain_with_lambda.invoke({"topic": "beets"})可运行对象并行执行
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
vectorstore : FAISS.from texts(
["张三在华为工作”,“熊喜欢吃蜂蜜”],embedding=embeddings)
retriever = vectorstore.as_retriever()
template ="""仅根据以下上下文回答问题
{context}
问题:{question}
"""
prompt :ChatPromptTemplate.from_terplate(template)
retrieval_chain =({"context": retriever,"question": RunnablePassthrough()]
|prompt
|model
|StrOutputParser()
)# retriever给context,question通过RunnablePassthrough将张三在哪工作?给它
retrieval_chain.invoke("张三在哪工作?”)使用itemgetter
from operator import itemgetter
from langchain_community.vectorstores import FAISS
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
vectorstore : FAISS.from_texts(
["张三在华为工作”],embedding=embeddings)
retriever = vectorstore.as_retriever()
template ="""仅根据以下上下文回答问题
{context}
问题:{question}
用以下语言回答:{language}
"""
prompt=ChatPromptTemplate.from_terplate(template)
retrieval_chain =({
"context": itemgetter("question")|retriever,#context取到question给retriever再返回给context
"question": itemgetter("question")|,
"language": itemgetter("language)|,}
|prompt
|model
|StrOutputParser())
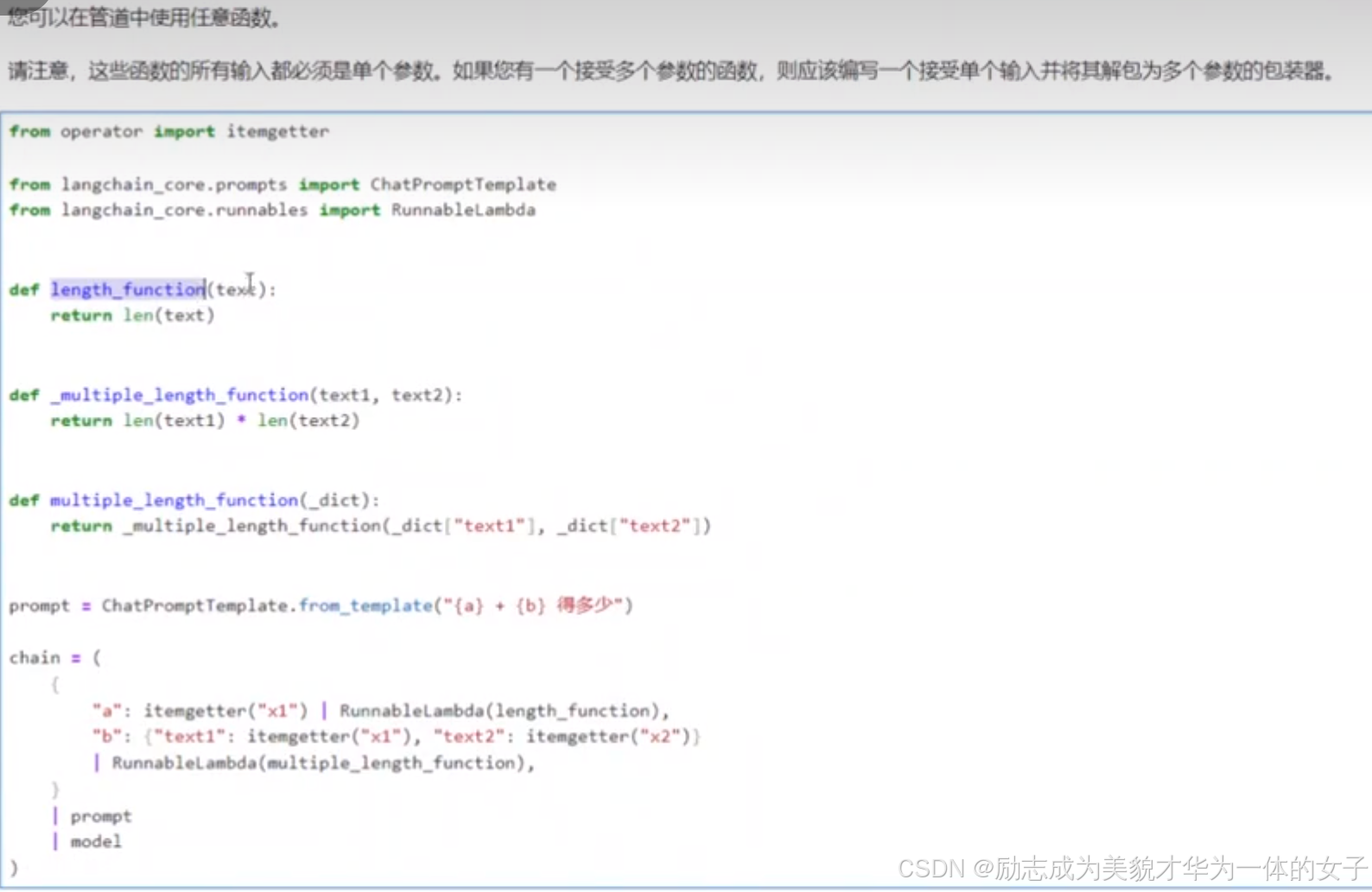
retrieval_chain.invoke({"question":"张三在哪工作?”,"language":"日语"})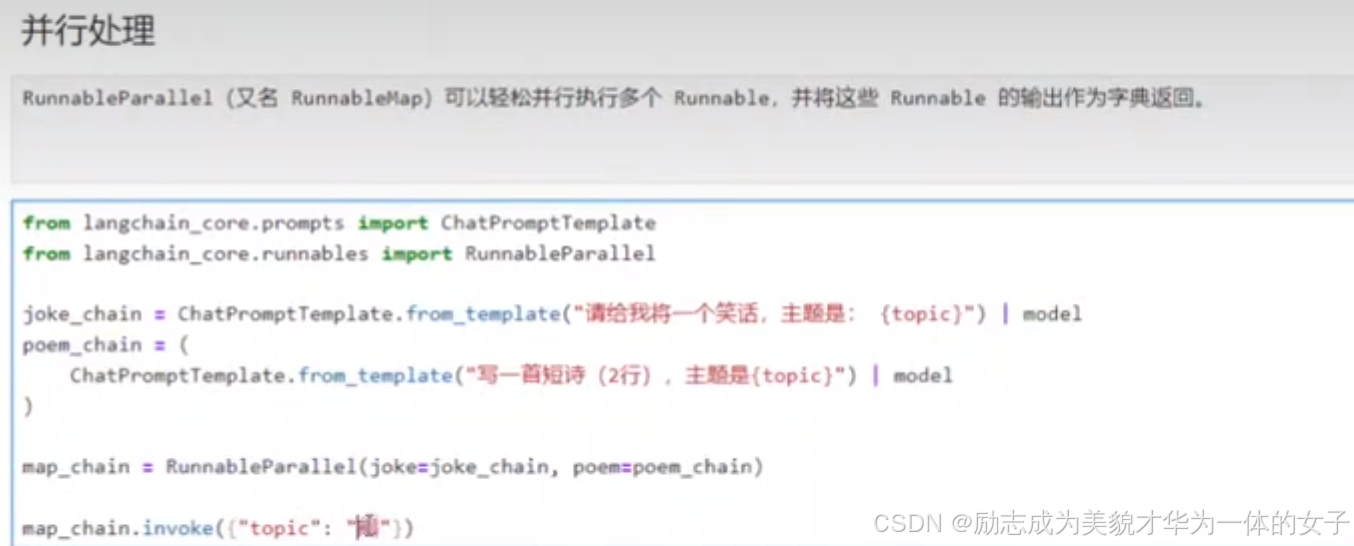
5.Memory(记忆)
ConversationBufferMemory
该组件类似我们上面的描述,只不过它会将聊天内容记录在内存中,而不需要每次再手动拼接聊天记录。
ConversationBufferWindowMemory
相比较第一个记忆组件,该组件增加了一个窗口参数,会保存最近看 k 论的聊天内容。
ConversationTokenBufferMemory
在内存中保留最近交互的缓冲区,并使用 token 长度而不是交互次数来确定何时刷新交互。
ConversationSummaryMemory
相比第一个记忆组件,该组件只会存储一个用户和机器人之间的聊天内容的摘要。
ConversationSummaryBufferMemory
结合了上面两个思路,存储一个用户和机器人之间的聊天内容的摘要并使用 token 长度来确定何时刷新交互。
VectorStoreRetrieverMemory
它是将所有之前的对话通过向量的方式存储到 VectorDB(向量数据库)中,在每一轮新的对话中,会根据用户的输入信息,匹配向量数据库中最相似的 K 组对话。

6.Agents(代理)
在LangChain的世界里,Agent是一个智能代理,它的任务是听取你的需求(用户输入)和分析当前的情境(应用场景),然后从它的工具箱(一系列可用工具)中选择最合适的工具来执行操作。这些工具箱里装的是LangChain提供的各种积木,比如Models、Prompts、Indexes等。
如下图所示,Agent接受一个任务,使用LLM(大型语言模型)作为它的“大脑”或“思考工具”,通过这个大脑来决定为了达成目标需要执行什么操作。它就像是一个有战略眼光的指挥官,不仅知道战场上的每个小队能做什么,还能指挥它们完成更复杂的任务。
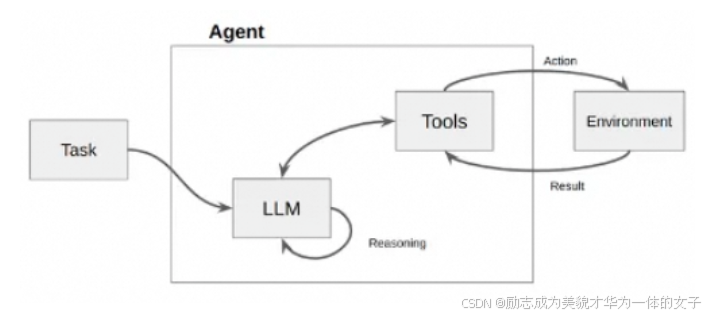
Tool:工具
Toolkit:工具包
AgentExcutor:调度器,调度逻辑全靠它
LangChain 中的 Agent 有哪些常见类型?
比如说:
ZeroShotReAct
Structured Input ReAct
OpenAI Functions
Conversational Agent
……
解释一下名词:Zero Shot,就是指大模型推理的一种任务,这种任务给大模型一个全新的事物让它去推理,这种事物在模型的训练数据中没有出现过。也就是“零准备”推理。
ReAct 实际上是一种框架,ReAct = Reason + Act,就是推理+行动。
让Agent自己去网上搜索“北京的面积”和“纽约的面积”,然后计算出来两者的差值。
"""LangChainTools"""
import os
from langchain.agents import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain.llms import Tongyi#通义千问模型
from langchain.tools import DuckDuckGoSearchRun#搜索引擎
# duck duck search
search = DuckDuckGoSearchRun()
res = search.run("北京的面积有多大?")
print(res)
res = search.run("纽约的面积有多大?")
print(res)
os.environ["DASHSCOPE_API_KEY"] = "sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
llm = Tongyi()
tools = load_tools(["ddg-search", "llm-math"], llm=llm)#工具链条
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,#Zero Shot”类型的“ReAct”代理人
verbose=True)
agent.run("北京的面积和纽约的面积差是多少?")使用AgentExecutor
import getpass
import os
#设置环境变量以开始langsmith记录跟踪信
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = getpass.getpass()
#定义tool 在线搜索
from langchain_community.tools.tavily_search import TavilySearchResults#在线搜索
export TAVILY_API_KEY="..."
search = TavilySearchResults(max_results=2)
search.invoke("what is the weather in SF")
#定义检索器
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
retriever.invoke("how to upload a dataset")[0]
#将检索器转换为tool
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"langsmith_search",
"Search for information about LangSmith. For any questions about LangSmith, you must use this tool!",
)
#工具tools
tools = [search, retriever_tool]
#使用语言模型
from langchain_openai import ChatOpenAI
os.environ["OPENAI_API_KEY"] = getpass.getpass()
model = ChatOpenAI(model="gpt-4")
#用此模型进行工具调用
#还没有调用该工具 - 它只是在告诉我们要调用它。为了真正调用它,我们将需要创建我们的代理。
model_with_tools = model.bind_tools(tools)
response = model_with_tools.invoke([HumanMessage(content="Hi!")])
print(f"ContentString: {response.content}")
print(f"ToolCalls: {response.tool_calls}")
#创建代理
from langchain import hub
# Get the prompt to use - you can modify this!
prompt = hub.pull("hwchase17/openai-functions-agent")
prompt.messages
#使用 LLM、提示和工具来初始化代理
#代理负责接收输入并决定采取哪些操作。至关重要的是,代理不执行这些操作 - 这些操作由 AgentExecutor(下一步)完成。
from langchain.agents import create_tool_calling_agent
agent = create_tool_calling_agent(model, tools, prompt)
#将代理(大脑)与 AgentExecutor 中的工具结合起来(AgentExecutor 将反复调用代理并执行工具)。
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools)
#运行代理
agent_executor.invoke({"input": "hi!"})为了让它有记忆,我们需要传递以前的 `chat_history`。
#自动跟踪消息
from langchain_community.chat_message_histories import ChatMessageHistory
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.runnables.history import RunnableWithMessageHistory
store = {}
def get_session_history(session_id: str) -> BaseChatMessageHistory:
if session_id not in store:
store[session_id] = ChatMessageHistory()
return store[session_id]
agent_with_chat_history = RunnableWithMessageHistory(
agent_executor,
get_session_history,
input_messages_key="input",
history_messages_key="chat_history",
)
agent_with_chat_history.invoke(
{"input": "hi! I'm bob"},
config={"configurable": {"session_id": "<foo>"}},
)
#{'input': "hi! I'm bob",
# 'chat_history': [],
#'output': 'Hello Bob! How can I assist you today?'}
agent_with_chat_history.invoke(
{"input": "what's my name?"},
config={"configurable": {"session_id": "<foo>"}},
)
#{'input': "what's my name?",
#'chat_history': [HumanMessage(content="hi! I'm bob"),
#AIMessage(content='Hello Bob! How can I assist you today?')],
#'output': 'Your name is Bob.'}
三、常用库
获取模型:
from langchain_openai import OpenAI
from langchain_community.llms import Ollama
from langchain.community.llms import HuggingFaceHub
嵌入模型:
from.langchain_community.embeddings import HuggingFaceInferenceAPIEmbeddings
from langchain_community.embeddings import OllamaEmbeddings
from langchain_openai import OpenAIEmbeddings
加载数据:
from langchain_community.document_loaders import PyPDFLoader
文档分割:
from langchain.text_splitter import RecursivecharacterTextSplitter
向量库存储:
from langchain_community.vectorstores import FAISS
向量检索:
from langchain.chains import RetrievalQA
template模板:
from langchain.prompts import PromptTemplate
from langchain.prompts.chat import SystemMessagePromptTemplate
from langchain_core.prompts import ChatPromptTemplate
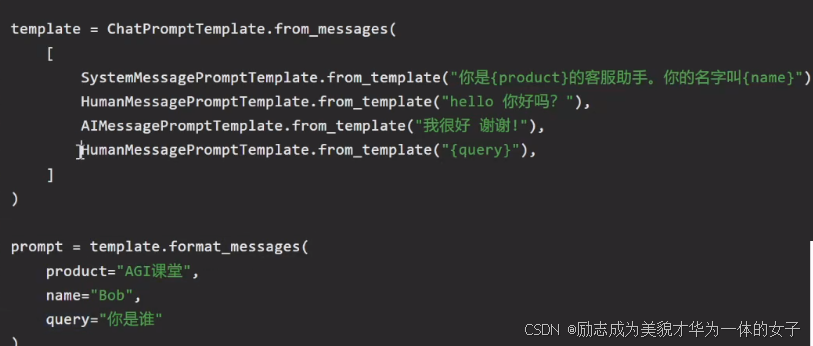
FewShotPrompt Template
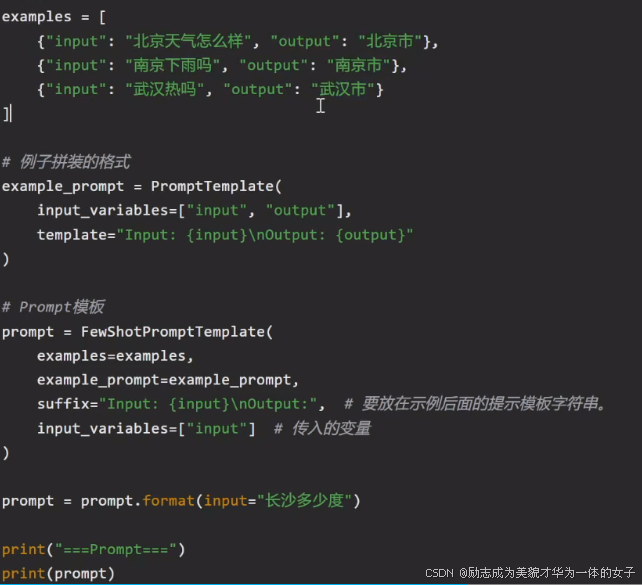
格式化输出:
from langchain_core.output_parsers import
四、langchain实现rag的步骤
-
先用本地的各种文件,利用Embeddings 模型构建一个向量数据库,做为本地的知识库。
-
然后当用户对大模型提问时,先在本地的向量数据库里面查找跟问题相关的内容。这一步叫做 Retrieval 检索。
-
再把从向量数据库中查找到的内容,和用户的原始问题合到一起,作为 Prompt 发给大模型。这一步叫做 Augmented 增强。
-
最后,大模型会根据 prompt 返回内容。这一步叫做 Generation 生成。
切分文本的时候,chunk_size 和 chunk_overlap 取多少合适?
文本转向量时,使用哪个 Embeddings 模型最佳?
查找问题的相关上下文时,用欧式距离还是别的距离,比如余弦距离还是?
每个 Embeddings 模型,以多大的的相关度数值做为阈值合适?
如何评估 RAG 的整体效果?
五、实战
Llama 3 + LangChain + HuggingFace 实现本地部署RAG(检索增强生成)_大模型_王玉川_InfoQ写作社区
【记录】LangChain|Ollama结合LangChain使用的速通版(包含代码以及切换各种模型的方式)_ollama langchain-优快云博客
探索Hugging Face在LangChain中的集成:从安装到进阶使用_langchain-huggingface安装-优快云博客
【喂饭教程】大模型基于Huggingface+Langchain快速实现RAG问答系统的构建,从原理讲解到代码解读,简单易学的保姆级教程!附代码_哔哩哔哩_bilibili
GitHub - anarojoecheburua/RAG-with-Langchain-and-FastAPI: This repository contains the code for building a Retrieval-Augmented Generation (RAG) system using LangChain and FastAPI. It includes document loading, text splitting, vector embedding, and API deployment for a scalable and efficient RAG-based application. GitHub - NanGePlus/RagLangChainTest: 在本项目中模拟健康档案私有知识库构建和检索全流程,通过一份代码实现了同时支持多种大模型(如OpenAI、阿里通义千问等)的RAG(检索增强生成)功能:(1)离线步骤:文档加载->文档切分->向量化->灌入向量数据库;在线步骤:获取用户问题->用户问题向量化->检索向量数据库->将检索结果和用户问题填入prompt模版->用最终的prompt调用LLM->由LLM生成回复
全网首发GLM4+最新langchain v0.3版本+RAG详细教程—环境配置、模型本地部署、模型微调、效果展示_哔哩哔哩_bilibili

















 1688
1688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









